








深度学习与神经网络
编辑日期: 2024-07-14 文章阅读: 次
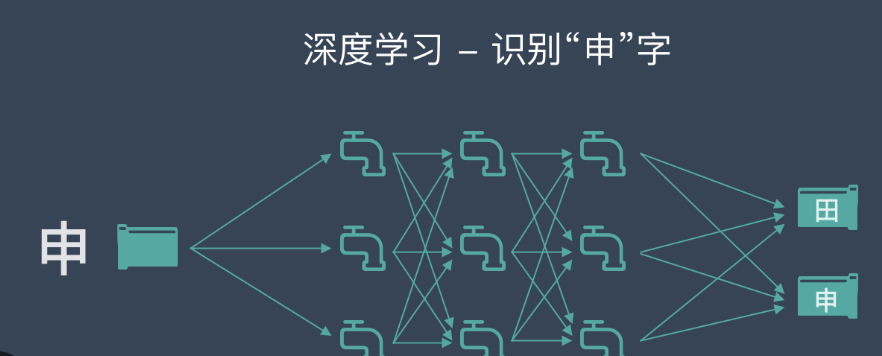
深入理解深度学习与神经网络
深度学习是机器学习的一个子领域,它通过多层神经网络来学习复杂的模式和特征。
理解深度学习和神经网络的基础知识,对于构建和优化现代AI系统至关重要。
深度学习(Deep Learning)
概念
深度学习通过构建和训练深层神经网络来处理和分析数据。
深度神经网络由多个隐藏层组成,每一层通过非线性变换提取数据的高级特征。
神经网络(Neural Networks)
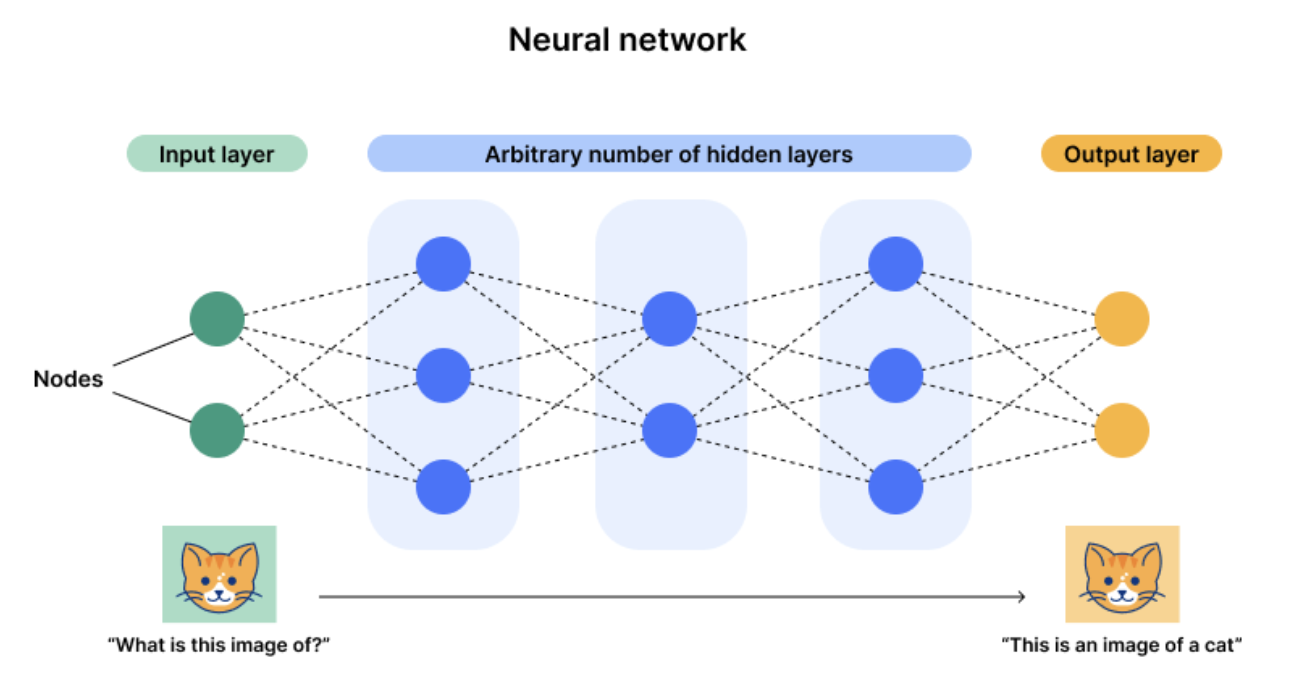
基本构成
- 神经元(Neuron):神经网络的基本单元,每个神经元接收输入并通过激活函数生成输出。
- 层(Layer):神经网络由多个层组成,包括输入层、隐藏层和输出层。每一层包含多个神经元。
- 权重(Weights)和偏置(Biases):连接神经元的权重和每个神经元的偏置是网络学习的参数,通过训练进行优化。
前向传播(Forward Propagation)
前向传播是指数据从输入层经过隐藏层传递到输出层的过程。
每个神经元接收前一层的输出,经过权重和偏置的加权和激活函数的变换,生成当前层的输出。
def forward_propagation(X, weights, biases):
layer_output = X
for w, b in zip(weights, biases):
layer_output = activation_function(np.dot(layer_output, w) + b)
return layer_output
解释:使用
zip函数将权重列表weights和偏置列表biases逐元素配对。然后对每一对权重和偏置执行循环操作。w表示当前层的权重,b表示当前层的偏置。
反向传播(Backpropagation)
反向传播是指通过:计算误差的梯度,更新权重和偏置来优化神经网络的过程。
它使用链式法则计算每个参数的梯度,从而最小化损失函数。
def backpropagation(X, y, weights, biases, learning_rate):
layer_output = forward_propagation(X, weights, biases)
loss = compute_loss(layer_output, y)
gradients = compute_gradients(X, y, layer_output, weights, biases)
for i in range(len(weights)):
weights[i] -= learning_rate * gradients['dW' + str(i)]
biases[i] -= learning_rate * gradients['dB' + str(i)]
return weights, biases, loss
常用激活函数(Activation Functions)
- Sigmoid:将输入映射到 (0, 1) 范围内。
- ReLU(Rectified Linear Unit):将负值映射为0,正值保持不变。
- Tanh:将输入映射到 (-1, 1) 范围内。
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def relu(x):
return np.maximum(0, x)
def tanh(x):
return np.tanh(x)
深度学习框架
TensorFlow
TensorFlow 是一个广泛使用的深度学习框架,提供了丰富的API和工具来构建和训练神经网络。
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(784,)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(train_data, train_labels, epochs=10, validation_data=(val_data, val_labels))
PyTorch
PyTorch 是另一个流行的深度学习框架,以其灵活性和动态计算图而闻名。
import torch
import torch.nn as nn
import torch.optim as optim
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.softmax(self.fc3(x), dim=1)
return x
model = SimpleNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(10):
for data, labels in train_loader:
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
实际应用
- 图像识别:深度学习在图像识别中的应用广泛,如自动驾驶、医疗影像分析等。
- 自然语言处理:深度学习用于文本分类、情感分析、机器翻译等任务。
- 语音识别:深度学习在语音识别和生成中表现出色,如智能助手和翻译应用。
参考资料
通过学习深度学习和神经网络的基本概念和实现方法,我们为构建和优化现代AI系统奠定了基础。
下一节
点击卡片,继续学习:

