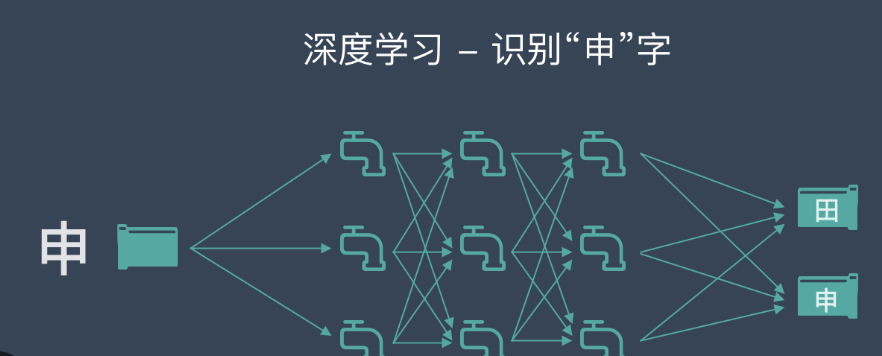
机器学习基础
编辑日期: 2024-07-13 文章阅读: 次
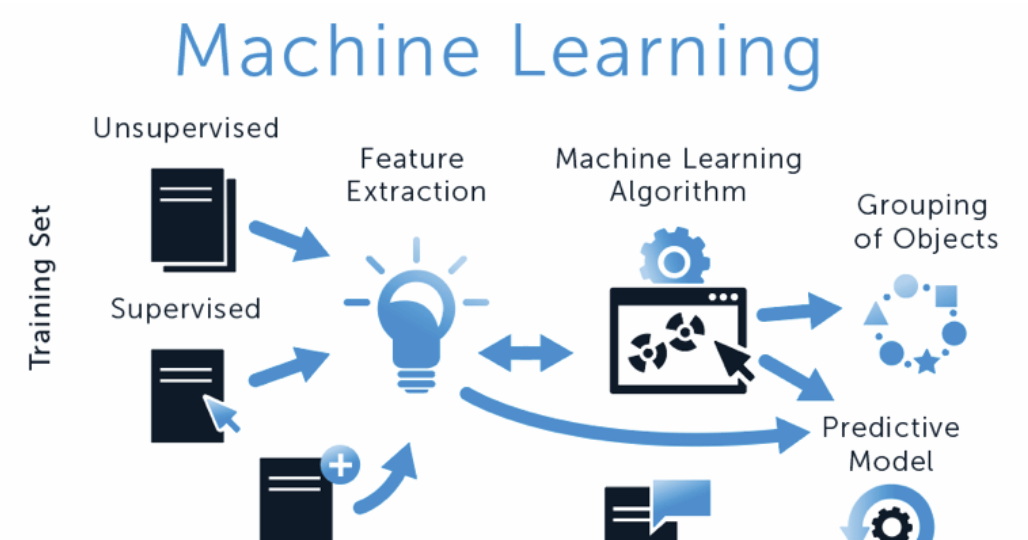
了解监督学习与无监督学习
机器学习是人工智能的核心。
它通过从数据中学习规律,并进行预测和决策。
理解监督学习和无监督学习是掌握机器学习的关键步骤。
监督学习(Supervised Learning)
概念
监督学习是一种通过带标签的数据进行训练的机器学习方法。
模型在输入数据(特征)和输出标签(目标)之间学习映射关系,以在未来对新数据进行预测。
常见算法
线性回归(Linear Regression):用于回归任务,预测连续值。
示例:预测房价、股票价格。
逻辑回归(Logistic Regression):用于分类任务,预测离散类别。
示例:垃圾邮件检测、疾病诊断。
支持向量机(SVM):用于分类和回归任务,寻找最佳分隔超平面。
示例:图像分类、文本分类。
决策树(Decision Tree):通过树状结构进行决策,适用于分类和回归任务。
示例:客户流失预测、信用评分。
实践
- 数据准备:收集和清洗数据,划分训练集和测试集。
- 模型训练:使用训练集训练模型,调整参数以优化性能。
- 模型评估:使用测试集评估模型,常用指标包括
准确率、精确率、召回率和F1分数。
无监督学习(Unsupervised Learning)
概念
无监督学习是通过没有标签的数据进行训练的机器学习方法。
模型在输入数据中学习模式和结构,主要用于发现数据的内在规律。
常见算法
- 聚类算法(Clustering Algorithms):将数据点划分为不同的组或簇。
- K-均值聚类(K-Means Clustering):通过迭代优化将数据点分配到K个簇中。
- 示例:客户分群、图像分割。
- 层次聚类(Hierarchical Clustering):构建树状的聚类层次结构。
- 示例:文档分类、基因表达数据分析。
- 降维算法(Dimensionality Reduction Algorithms):减少数据的维度,提取主要特征。
- 主成分分析(PCA):通过线性变换将高维数据投影到低维空间。
- 示例:图像压缩、数据可视化。
- t-SNE:一种非线性降维方法,适用于高维数据的可视化。
- 示例:视觉数据探索、文本嵌入。
实践
- 数据准备:收集和清洗数据。
- 算法应用:选择合适的无监督学习算法,对数据进行处理。
- 结果分析:分析和解释算法输出的模式和结构。
实际应用
- 推荐系统:通过监督学习和无监督学习算法,为用户提供个性化推荐。
- 示例:Netflix电影推荐、亚马逊商品推荐。
- 数据挖掘:利用无监督学习算法发现数据中的隐藏模式。
- 示例:市场分析、社会网络分析。
参考资料
通过学习监督学习和无监督学习的基本概念和常用算法,我们为后续深入研究机器学习模型和应用奠定了基础。
下一节
点击卡片,继续学习: