计算机视觉
编辑日期: 2024-07-10 文章阅读: 次

了解计算机视觉的基础知识
计算机视觉(Computer Vision)是人工智能的一个分支,旨在使计算机能够从图像和视频中获取信息并做出决策。计算机视觉在自动驾驶、医疗影像分析、安防监控等领域有广泛应用。本节课将介绍计算机视觉的基本概念、常用技术和应用场景。
计算机视觉的基本概念
定义
计算机视觉是一种使计算机能够理解和处理图像和视频数据的技术。它结合了计算机科学、数学和工程的知识,旨在模仿人类视觉系统的功能。
关键技术
1. 图像处理(Image Processing)
图像处理是指对图像进行处理和分析的过程,包括去噪、增强、分割等操作。
import cv2
image = cv2.imread('image.jpg')
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow('Gray Image', gray_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
2. 特征提取(Feature Extraction)
特征提取是从图像中提取有意义的特征,以用于后续的分析和识别。常用方法包括SIFT、SURF和ORB。
import cv2
image = cv2.imread('image.jpg')
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
orb = cv2.ORB_create()
keypoints, descriptors = orb.detectAndCompute(gray_image, None)
image_with_keypoints = cv2.drawKeypoints(image, keypoints, None, color=(0, 255, 0))
cv2.imshow('Keypoints', image_with_keypoints)
cv2.waitKey(0)
cv2.destroyAllWindows()
3. 图像分割(Image Segmentation)
图像分割是将图像划分为若干有意义的区域,以便进行进一步分析。
常用方法包括阈值分割、区域生长和边缘检测。
import cv2
image = cv2.imread('image.jpg', 0)
ret, thresh_image = cv2.threshold(image, 127, 255, cv2.THRESH_BINARY)
cv2.imshow('Threshold Image', thresh_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
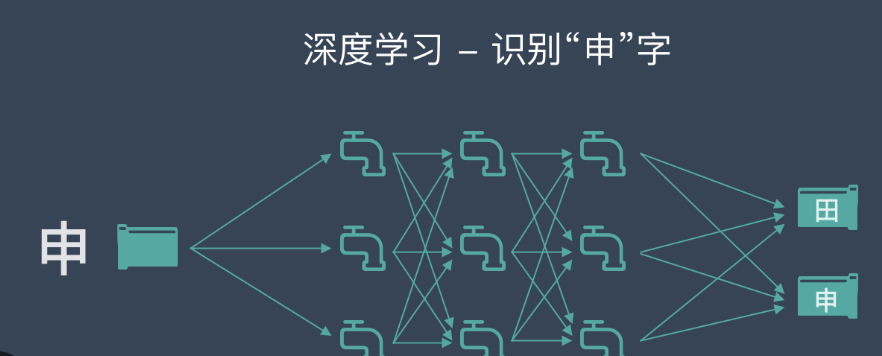
深度学习在计算机视觉中的应用
1. 卷积神经网络(Convolutional Neural Networks, CNNs)
卷积神经网络是深度学习中处理图像数据的主要模型,通过卷积层提取图像的空间特征。
import tensorflow as tf
from tensorflow.keras import layers, models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()
2. 对象检测(Object Detection)
对象检测是识别图像中多个目标的位置和类别的技术。
常用模型包括YOLO、SSD和Faster R-CNN。
from transformers import DetrImageProcessor, DetrForObjectDetection
import torch
from PIL import Image
image = Image.open("image.jpg")
processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
target_sizes = torch.tensor([image.size[::-1]])
results = processor.post_process_object_detection(outputs, target_sizes=target_sizes)[0]
for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
print(f"Detected {model.config.id2label[label.item()]} with confidence {round(score.item(), 3)} at location {box}")
应用场景
1. 自动驾驶(Autonomous Driving)
计算机视觉在自动驾驶中发挥重要作用,通过识别道路标志、行人和其他车辆,实现自动导航和避障。
2. 医疗影像分析(Medical Image Analysis)
计算机视觉用于分析医疗影像,如X光片、CT扫描和MRI,辅助医生进行诊断和治疗。
3. 安防监控(Security Surveillance)
计算机视觉用于安防监控,自动检测和识别异常行为,提高安全性。
参考资料
- 《Computer Vision: Algorithms and Applications》 by Richard Szeliski
- Coursera 的计算机视觉课程
- OpenCV 官方文档
- TensorFlow 官方文档
- PyTorch 官方文档
通过学习计算机视觉的基本概念和常用技术,我们为进一步理解和应用计算机视觉奠定了基础。
下一节
点击卡片,继续学习: