多模态AI
编辑日期: 2024-06-29 文章阅读: 次

了解多模态AI的基础知识
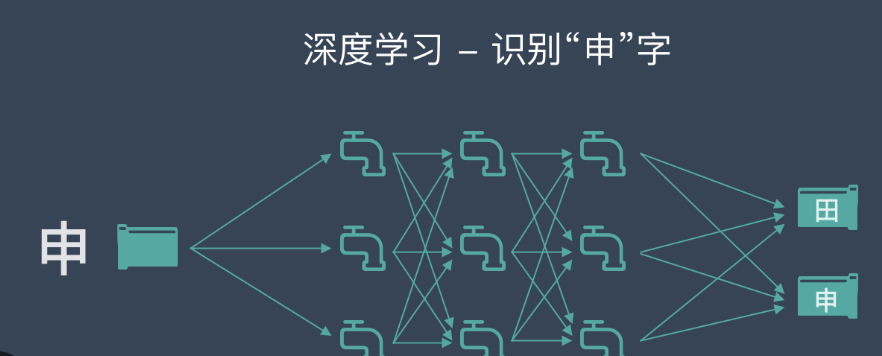
多模态AI是一种结合多种数据类型的技术。 它能够处理文本、图像、音频等多种形式的数据。 每种数据类型提供不同的信息。 通过整合多种数据类型,多模态AI可以提高模型的准确性和功能性。
多模态AI的基本概念
定义
多模态AI是指能够处理和理解多种数据类型的人工智能系统。 它通过融合来自不同模态的数据,提供更全面和准确的结果。
关键技术
1. 数据融合(Data Fusion)
数据融合是多模态AI的核心技术。 它包括特征级融合和决策级融合。 特征级融合将不同模态的数据特征结合起来。 决策级融合则结合不同模态的预测结果。
import torch
import torch.nn as nn
class MultimodalModel(nn.Module):
def __init__(self):
super(MultimodalModel, self).__init__()
self.text_model = nn.Linear(100, 50)
self.image_model = nn.Linear(2048, 50)
self.fusion_layer = nn.Linear(100, 1)
def forward(self, text_input, image_input):
text_features = self.text_model(text_input)
image_features = self.image_model(image_input)
combined_features = torch.cat((text_features, image_features), dim=1)
output = self.fusion_layer(combined_features)
return output
2. 自然语言处理(NLP)与计算机视觉的结合
多模态AI经常结合NLP和计算机视觉技术。 例如,图像描述生成模型使用图像和文本数据。 这种结合可以提高图像理解和生成的准确性。
from transformers import VisionEncoderDecoderModel, ViTFeatureExtractor, AutoTokenizer
from PIL import Image
model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
feature_extractor = ViTFeatureExtractor.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
tokenizer = AutoTokenizer.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
image = Image.open("image.jpg")
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
output_ids = model.generate(pixel_values, max_length=16, num_beams=4, return_dict_in_generate=True).sequences
description = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(description)
3. 音频与文本的结合
音频与文本的结合可以用于语音识别和生成。 例如,语音助手使用音频输入生成文本响应。 这种技术可以提高语音识别的准确性和响应的自然性。
import torchaudio
from transformers import Wav2Vec2ForCTC, Wav2Vec2Tokenizer
tokenizer = Wav2Vec2Tokenizer.from_pretrained("facebook/wav2vec2-base-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
waveform, sample_rate = torchaudio.load("audio.wav")
input_values = tokenizer(waveform, return_tensors="pt").input_values
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = tokenizer.decode(predicted_ids[0])
print(transcription)
应用场景
1. 图像描述生成
图像描述生成结合图像和文本数据。 可以应用于图像标注、盲人辅助等领域。
2. 视频分析
视频分析结合图像、音频和文本数据。 用于自动驾驶、安防监控等领域。
3. 多模态搜索
多模态搜索允许用户通过图像、语音、文本等多种方式进行搜索。 可以提高搜索的便捷性和准确性。
参考资料
- 《深度学习》 by Ian Goodfellow, Yoshua Bengio 和 Aaron Courville
- Coursera 的深度学习专项课程(Deep Learning Specialization) by Andrew Ng
- PyTorch 官方文档
- Transformers 官方文档
通过学习多模态AI的基本概念和关键技术,我们为进一步理解和应用多模态AI奠定了基础。
下一节
点击下方卡片,继续学习: