








LangChain 框架学习
编辑日期: 2024-05-14 文章阅读: 次
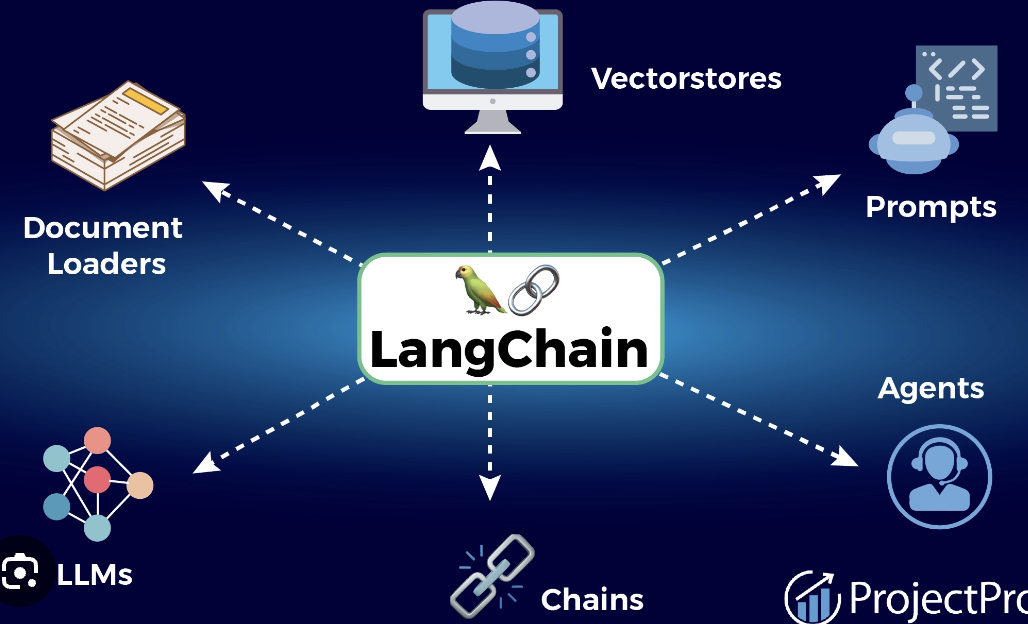
了解LangChain框架的基本概念和用途
LangChain 是一个用于构建语言模型应用程序的开源框架。 它旨在简化开发和部署语言模型驱动的应用程序。 LangChain 提供了一系列工具和功能,帮助开发者快速创建、集成和管理语言模型。
参考资源
安装与配置
首先,我们需要安装LangChain框架。 可以使用以下命令进行安装:
pip install langchain
配置LangChain
安装完成后,需要进行基本配置。 以下是一个简单的配置示例:
import langchain as lc
config = lc.Config(
model_name="langchain-model",
data_dir="./data",
output_dir="./output"
)
基础操作
熟悉LangChain的基本操作,包括数据加载、模型定义和训练。 以下是一些基础操作的示例。
数据加载
LangChain提供了方便的数据加载接口。 可以轻松加载和预处理常见的数据集。 以下是加载数据集的示例:
from langchain.data import DataLoader
train_loader, test_loader = DataLoader.load_data(batch_size=32)
模型定义
使用LangChain定义模型非常简洁。 以下是一个简单的语言模型的定义示例:
import langchain.nn as nn
class SimpleLM(nn.Module):
def __init__(self):
super(SimpleLM, self).__init__()
self.embedding = nn.Embedding(num_embeddings=10000, embedding_dim=128)
self.rnn = nn.LSTM(input_size=128, hidden_size=256, num_layers=2, batch_first=True)
self.fc = nn.Linear(256, 10000)
def forward(self, x):
x = self.embedding(x)
x, _ = self.rnn(x)
x = self.fc(x)
return x
model = SimpleLM()
模型训练
LangChain提供了简洁的模型训练接口。 以下是训练模型的示例:
import langchain.optim as optim
from langchain.train import Trainer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
config = lc.Config(
model_name="simple-lm",
data_dir="./data",
output_dir="./output",
batch_size=32,
epochs=10
)
trainer = Trainer(model, criterion, optimizer, config)
trainer.train(train_loader, epochs=10)
模型评估
训练完成后,可以评估模型的性能。 以下是评估模型在测试集上的性能的示例:
test_loss, test_accuracy = trainer.evaluate(test_loader)
print(f'Test Loss: {test_loss}, Test Accuracy: {test_accuracy}')
进阶使用
自定义模型
LangChain框架允许用户定义复杂的自定义模型。 以下是一个自定义语言模型的示例:
import langchain.nn as nn
class CustomLM(nn.Module):
def __init__(self):
super(CustomLM, self).__init__()
self.embedding = nn.Embedding(num_embeddings=10000, embedding_dim=128)
self.transformer = nn.Transformer(d_model=128, nhead=8, num_encoder_layers=6)
self.fc = nn.Linear(128, 10000)
def forward(self, x):
x = self.embedding(x)
x = self.transformer(x)
x = self.fc(x)
return x
model = CustomLM()
优化和调参
LangChain框架支持多种优化算法和调参方法。 以下是使用网格搜索进行调参的示例:
from langchain.tuning import GridSearch
param_grid = {
'lr': [0.001, 0.01, 0.1],
'batch_size': [32, 64, 128],
'epochs': [10, 20]
}
grid_search = GridSearch(model, criterion, optimizer, param_grid, train_loader)
best_params = grid_search.search()
print(f'Best Parameters: {best_params}')
分布式训练
LangChain框架支持分布式训练。 可以在多个GPU上进行训练以加速计算过程。 以下是使用分布式数据并行(Distributed Data Parallel, DDP)的示例:
import langchain.distributed as dist
dist.init_process_group(backend='nccl')
model = nn.parallel.DistributedDataParallel(model)
from langchain.train import DistributedTrainer
trainer = DistributedTrainer(model, criterion, optimizer, config)
trainer.train(train_loader)
参考资料
通过学习LangChain框架的基本概念、安装与配置、基础操作和进阶使用,我们为进一步解决复杂的语言模型任务奠定了基础。
