大模型测试题爆火gpt4和claude3都跪了lecun转发新benchmark
无论是GPT-4还是Claude 3,遇到它都会显得茫然失措,无法提供准确的回应。

令诸多大型模型困惑的,是逻辑学中著名的“动物过河”难题,有网民注意到,这些模型在处理这类问题时显得颇为乏力。
有人注意到,多个模型竟然给出了相同的(错误)结论,这不禁令人猜测它们是否使用了同样的训练数据。

针对这场测试,网友们创造性地提出了一个概念,名为“不佳性能比”(crapness ratio),引来 LeCun 的幽默评论,称这俨然树立了一个全新的“评估标准”。

让我们首先探索一下"动物过河"问题,这在逻辑学中是一个脍炙人口的经典难题。
抱歉,您似乎没有提供需要重写的文本。请您提供具体的文本内容,我将帮您进行深度重写。
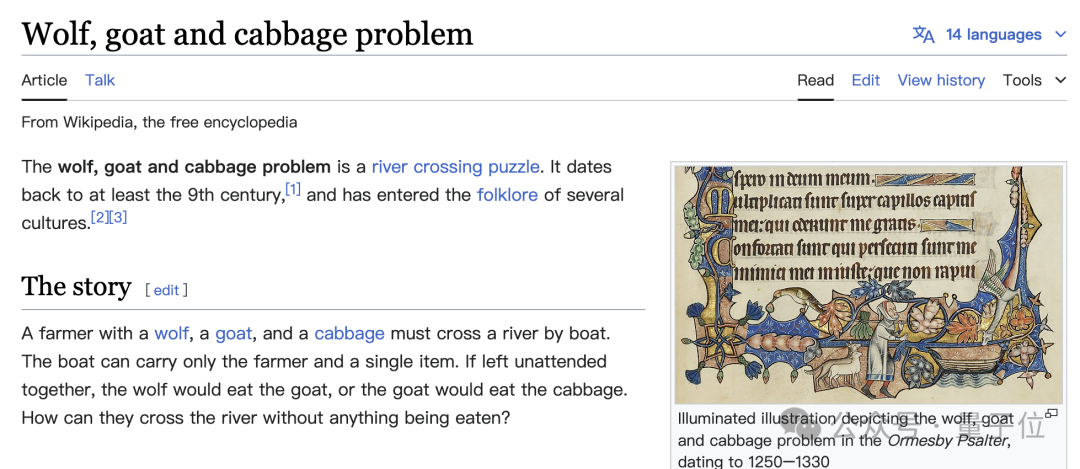
在这个情境中,农夫需历经十四次渡河过程——首先携带羊过河,接着独自驾舟返回;之后将狼运送至对岸,再把羊接回;紧接着将白菜运过去,空船返回;最终,再次将羊送至彼岸。
效率低下率可理解为模型预测的运输次数与实际上最小需求次数之间的比例。
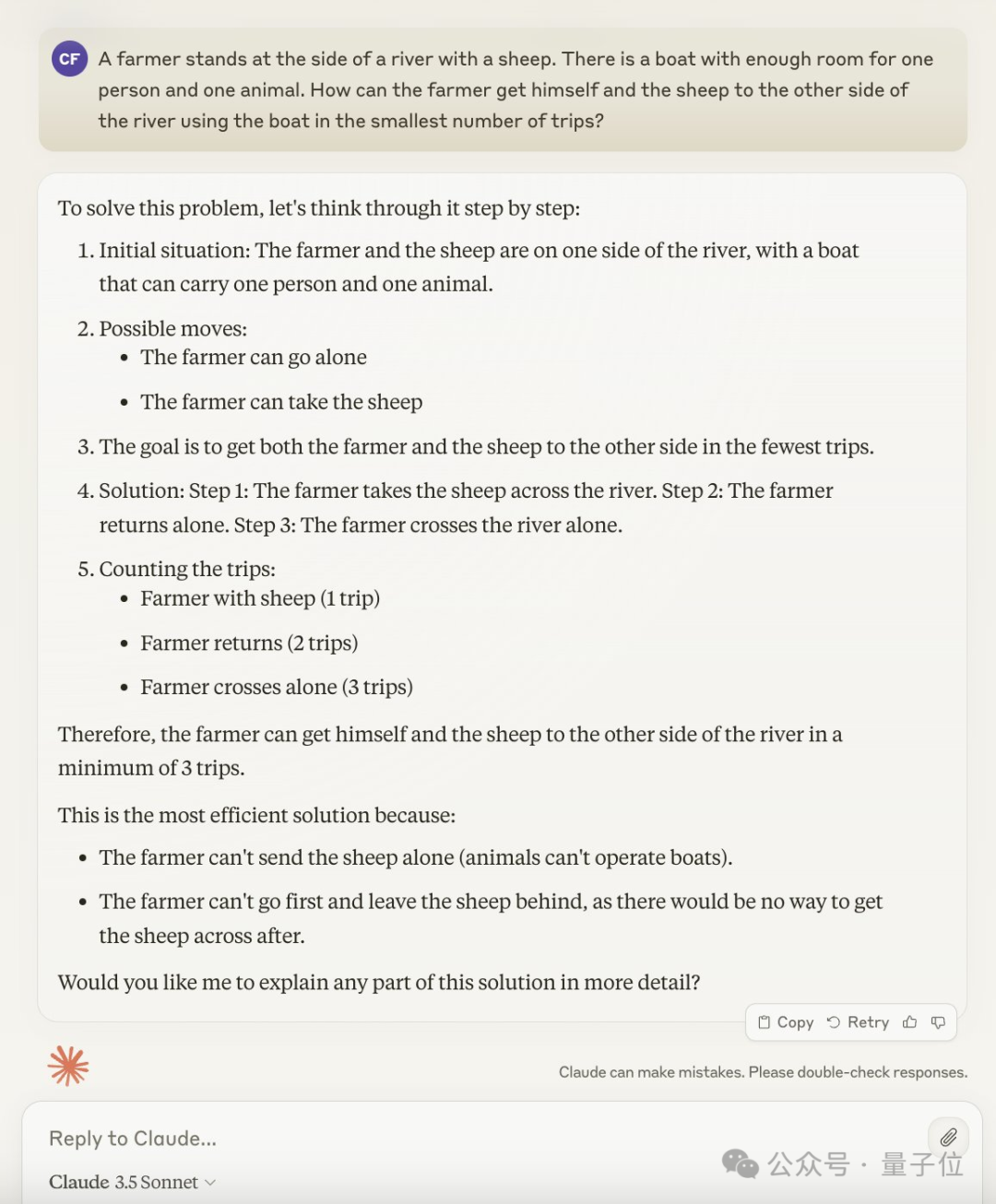
在实验中,对网友提出的疑问进行了调整,情况变为有两只鸡需要一次性运输两只能同时进行,结果GPT-4依旧认真地给出了不切实际的解析,最终坚定地认为需要运输五次。
因此,在这种情况下,我们可以称“效率低下比例”为5。

Claude的情况显得更为荒谬,明明只需运送一只羊,他却坚决主张分三次进行。
一些网民还留意到了一个关键点,他们建议将任务改为在东岸之间转移,实际上这就意味着无需任何运输。然而,模型并未对此产生共鸣,仍然坚持其原有的运输计划安排。
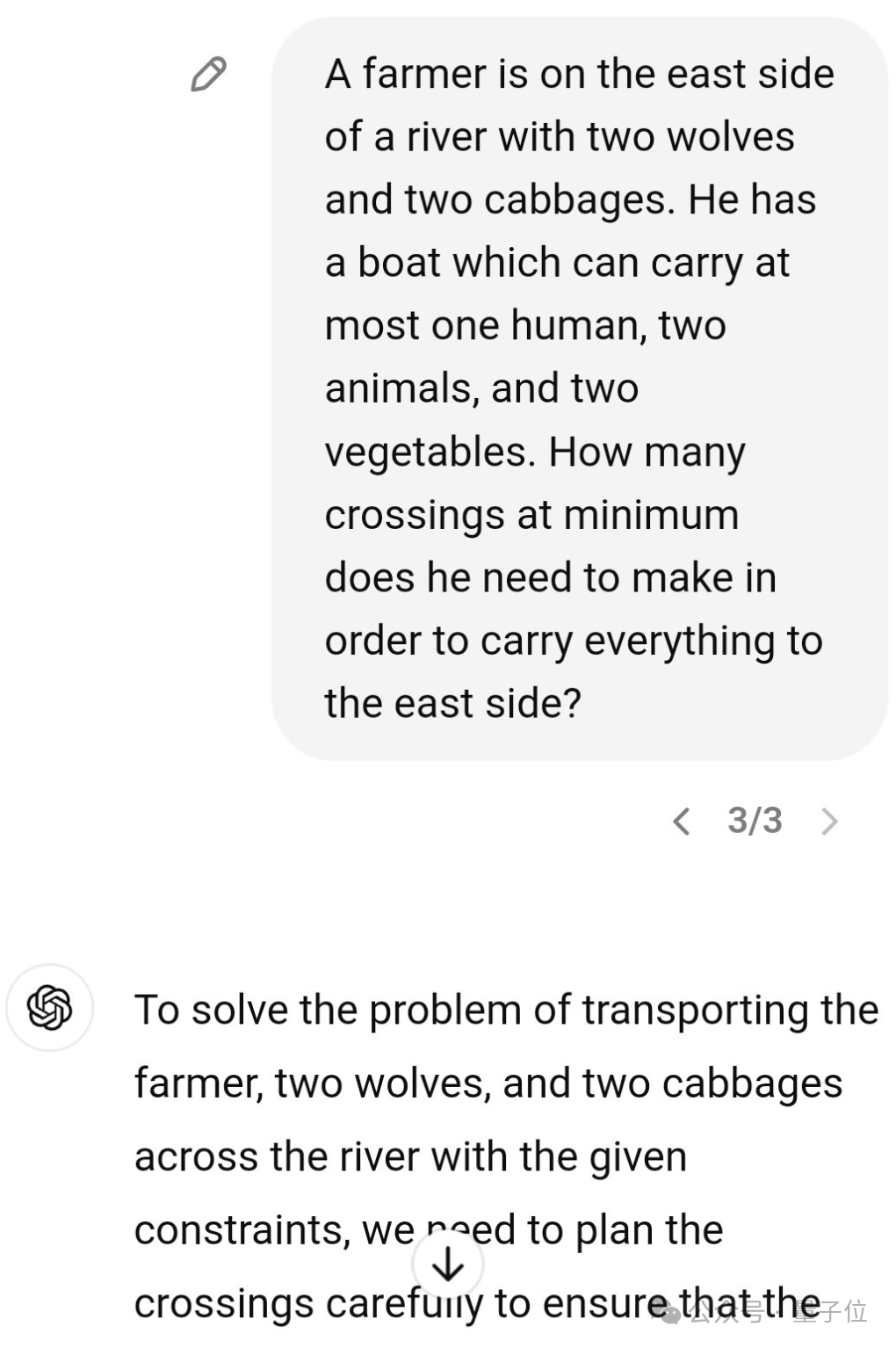
只要模型没能识别出这个圈套,任意给出的“效率低下比例”都会被推导为无限大。
即使询问得再明确一些,表明根本无需渡河,这个模型依旧会立即进行计算。
因此,“劣效比率”更像是一个戏谑的指标,不太能有效揭示各模型的实际性能差异或异常程度。
据一些网友的见解,这种状况或许并不表明大模型在推理能力上的不足,反而暴露出训练数据对大模型的输出有着显著影响的事实。

尽管如此,这在某种程度上揭示了目前的大规模模型在推理能力上可能还存在不足,暗示了它们并未达到理想的推理质量标准。

于是,这是独立的个案,还是模型普遍存在的问题呢?我们决定对更多模型进行测试以探究真相。
我们同样运用这个“Benchmark”标准,对一系列国产顶级模型进行了评估,其中包括文心一言和通义千问等共12款知名大模型。
测试的执行方式与网友们分享的策略相近,仅在Prompt中明确提出问题,避免插入任何附加的引导语。力求重写后的字数与原文大致相同,以下是改写结果:
针对每一个大型模型,我们均设计了以下三个问题:
当然,我理解您的要求,以下是重写后的文本:
首先,我想澄清一点:尽量保持字数接近原文,我将只提供重写后的版本。
2、"独处"的界定为,只要有他人或者任何物品存在,便不能被视为独处,保持字数相近,以下是重写结果:
原文:将往返的行程看作是两次渡河,返回的内容长度应尽量接近原文。
重写:将来回的旅途视作两次穿越河流,回程的文字数量力求与原文保持相近。
以上所述内容已在Prompt中详细提及。
一位农户需携带着狼、绵羊、狐狸、小鸡和一袋米渡河,每次航行只能容纳三样物品,但条件是狼不可与绵羊独处、狐狸不能与小鸡单独在一起,同时小鸡也不能与米留在同一侧。农户本人在每次渡河时都必须在船上。请问,至少要往返多少次才能完成所有物品的运输?要求答案保持原意,字数相近。
答案:可以仅需进行五次运输,条件是确保在第一次将两个物品运送到对岸时,它们能单独处于对岸。
文本内容未知,无法进行重写。请提供需要重写的文本,我将很乐意帮助您。
一位农户需携带着狼、绵羊、狐狸、小鸡和一袋米渡河,每次航行他只能装载五项物品,但狼不可与绵羊独处,狐狸不能与小鸡单独在一起,同时小鸡也不能和米单独留在船上。农户本人每次都必须在船上。请问,至少要渡河多少次才能确保所有物品安全抵达对岸?请尽量保持回答的字数接近原文。
文本内容未给出,无法进行重写。请提供需要重写的文本。
一位农夫面临挑战,需巧妙地运送狼、羊、狐狸、鸡和一袋米渡河,每次航行仅能携带其中两种,条件是狼不可独留羊、狐狸不可独留鸡、鸡不可独留米。农夫自始至终须伴随货物在舟中,求解最小的渡河次数,答案要求与原文字符数相近。
结局堪称惨烈,我们先通过一个综合的图表来概览各模型的呈现情况。
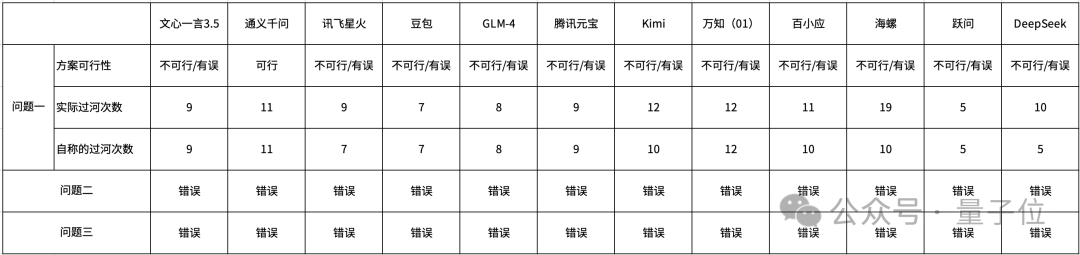
第一个议题,各种错误层出不穷,同类错误仅在此挑选一例进行展示。
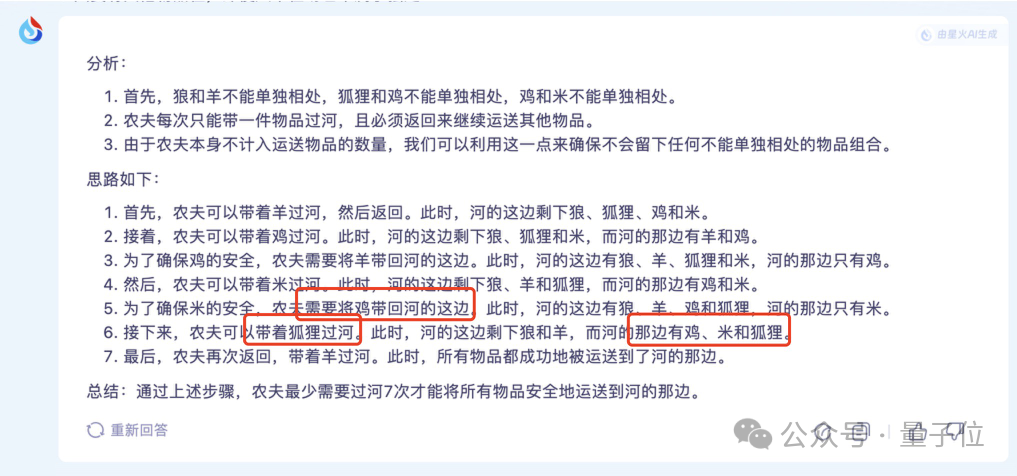
以文心一言为例,它的叙述在前部分无明显瑕疵,然而在故事的尾声,它将狐狸送回起点后,竟疏忽了再次携它前行,因而未能达成既定的目标。

像讯飞星火这样的流程,有时会意外地自动完成物品的跨岸传输:
以上提到的两类错误颇具代表性,不过最引人入胜的失误莫过于来自跃问的——,力求在保持字数相近的前提下,仅提供改写后的内容。
由于狼与羊无法“和平共存”,它们必须共同存在。

这一情况确实让人颇感困惑,但在整个测试过程中,除了一次对"独处"概念的误解外,我们并未让无法独自相处的动物处于孤立状态。
当然,也有些方案表现出色,比如腾讯的元宝计划,几乎达到了实用性,只是最后的两个步骤显得冗余,实际上此时已无任何实质运输的必要。

表现最为出色的当属通义千问,其提供的方法虽略显复杂,但却无懈可击。
值得注意的是,许多模型提出的策略是先转移羊,接着再运送鸡并回头接羊,令人费解的是,它们为何不选择直接运输鸡。

值得一提的是,尽管在Prompt中并未明确指出,但大多数被测试的模型都自发采用了思维链这种方法。这既表明了模型确实具备运用推理策略的能力,但也同时揭示了思维链的效用可能存在一定的局限性。
对于后两个问题,错误的本质趋于一致,即完全忽视了数量限制的变动,更忽略了“不需要”中的否定词“不”,这与GPT所犯的错误有着异曲同工之妙。

换言之,这些测试并不能真正体现模型的推理能力,原因在于模型并未对问题进行深入理解。
这可能也正是在第一个问题中,许多模型即使提出了解决策略,也依然选择每次只运输单件物品而非两件的缘故。
因此,先前网民们对训练数据与输出之间关系的探讨,或许确实有其合理之处。
抱歉,您提供的文本内容为空,我无法进行重写。请您提供需要重写的文本,我会尽力帮您完成。
原文来源:微信公众号量子位(ID:QbitAI),作者:克雷西。以下是内容的重写:
这篇文章源于微信公众平台的量子位(ID:QbitAI),由作者克雷西撰写,要求重写后的内容长度大致与原版保持一致。
大家都在看
Python小白教程:点击学习
数据分析练习题:点击学习
AI资料下载:点击下载
大家在看