火山豆包大模型价格清单公布支持预付-后付双模式号称国内最高并发标准

今日,火山引擎官方网站对豆包大模型的定价进行了全新的公示,声称其在保持模型推理费用显著低于市场平均水平的同时,豆包通用模型的 TPM(每分钟处理请求量)和 RPM(每分钟响应请求量)均达到了国内顶尖水准。据称,其价格相比业界平均水平低至1%,并且TPM的配额可达到相同规格模型的2.7至8倍之多。另外,用户还可以选择“预付费”或“后付费”两种计费模式以适应不同需求。
文本重写如下:
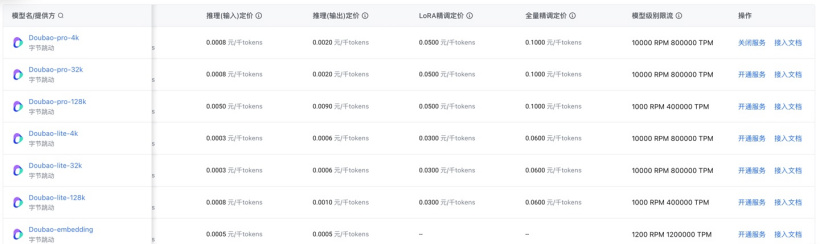
若432,000个Token的价格为2,000元,则单个千Token的平均费用为0.0046元。依据"后付费"原则,通常在模型推断的计算成本中,输入部分占据了主要部分,业界普遍估计输入数据量大约是输出数据量的五倍。
依据豆包普遍应用的pro-32k模型,计算得出其推断成本为:输入部分每千个Token收取0.0008元,输出部分每千个Token收取0.002元。整合这两部分费用后,模型的整体推断价格为每千个Token0.001元。
据官方透露,国内同类产品中,多数模型的TPM(每分钟事务数)上限设定在10万至30万之间,而RPM(每分钟请求数)通常落在60至120的范围内。对于轻量级模型,尽管其RPM限制相对较高,但也仅达到300至500。以10K RPM的限制为例,企业用户能够平均每秒调用豆包通用模型167次,这充分满足了大多数业务场景下生产系统对大型模型应用的需求。
官方指出,豆包通用模型的Pro和Lite版在128k配置下,针对长文本模型的处理能力已达到OpenAI向顶级(Tier4和Tier5级别)客户设定的RPM峰值。在应对高计算需求的场景中,这两个版本分别限制在1K RPM和400K TPM,显著超越了国内同类128k长文本模型的性能。这使得企业能以更经济的方式利用大型模型,有效推动大模型的应用普及。
大家都在看
Python小白教程:点击学习
数据分析练习题:点击学习
AI资料下载:点击下载
大家在看