著名菲尔兹奖获得者亲自尝试了gpt4在面对传统的过河问题时未能找到解决方案该模型持续提供对问题的重构答案并始终以中文进行回应
重写后:编辑:乔杨桃子,只提供中文回复,始终如一
最近,著名数学家、菲尔兹奖获得者 Timothy Gowers 展示了他对 GPT-4o 模型的实际测试,结果表明,这个先进的 LLM 在解决经典的“狼-山羊-卷心菜”过河问题时表现不尽如人意,居然在最基本的版本上出了错。让人惊讶的是,网友们还发现,连 Claude 3.5 这样的模型也不能避免错误,给出了错误的答案。
对于传统的“狼、山羊和卷心菜过河问题”,现今的所有大型语言模型都无法成功解决,只能提供重述的答案。
日前,著名的菲尔兹奖获得者、剑桥大学研究部门的主管蒂莫西·高斯选择使用GPT-4来挑战解决一个经典的动物过河问题。

在这里,他提出了一项创新性的评估标准——质量失真比例(crapness ratio),这个比例衡量的是大型语言模型提供的全部回答中正确答案所占的比重。
测试结果显示,Gowers 研究表明大型模型的冗余信息比例可能高达五倍。

起初,问题设定为:有个农夫需要携带两只鸡过河,船只每次只能承载一个人和两只禽类,问如何安排才能使农夫成功渡河的次数达到最少?请直接提供重写后的答案。
就连年幼的小孩,听完问题后也能立即给出准确的答案。
令人啼笑皆非的是,ChatGPT 的答复竟分为了五个环节,显得颇为滑稽可笑。
第二次过河时,农夫选择将两只鸡留在了彼岸,随后独自回到起点。此时的情景是:农夫位于初始岸边,而两只鸡仍停留在对面。
第三次涉水:农夫携带着一只鸡渡河;当前情况:农夫与一只鸡已抵达彼岸,另一只鸡仍留在原岸。
第四次过河时,农夫选择将鸡留在了彼岸,然后独自回到起点。此时的情景是:农夫依旧在初始的岸边,而那只鸡则停留在了对面。
第五次过河时,农夫携带着他的第二只鸡渡到了河的另一边。此时的状态是:农夫与两只鸡都已安全地站在了对岸。
因此,农民携带两只鸡过河的最低次数是五次。
在这情境中,ChatGPT 需要在概念上建立「农民」与人的关系,以及「鸡」与动物的关系,并计算出最高效的过河策略。

对此,LeCun 认为,评价大模型的新标准应当是——无意义内容的比例。

当然,也存在一些网友为 LLM 持有不同看法并为其辩护。
他指出,这样的行为同样可以施加于任何个体。假如你选择,任何人都可能面临失败的境地。虽然LLM的智能远远不及人类,但将它们置于极度的考验下并不是一个公正的评价方式。
有人提醒说,朋友们,现在离职恐怕为时尚早。

Gowers 提出了一道富有挑战性的谜题,涉及如何安全地运送 100 只鸡过河,以寻求高效的解决方案。
虽然未详细展示解题步骤,但据Gowers所述,GPT-4竟然成功地给出了正确答案。

进一步挑战,假设一个农夫需要运送 1000 只鸡过河,这个情境下模型会有何种表现呢?
初始情况为,河边有整整1000只鸡,农夫的任务是将其中的999只鸡涉水渡到对岸,确保起点处仅余下1只鸡。
然而,他的船只存在一个漏洞,因此在每次过河之初,他能承载十只鸡。可随着渡河接近尾声,船只因进水过多,为了避免鸡只落水,只能承载两只鸡了。

如何在确保没有鸡被淹死的情况下达成目标,农民至少需要过河多少次?

Gowers 指出,此次的空话比例高达125倍。

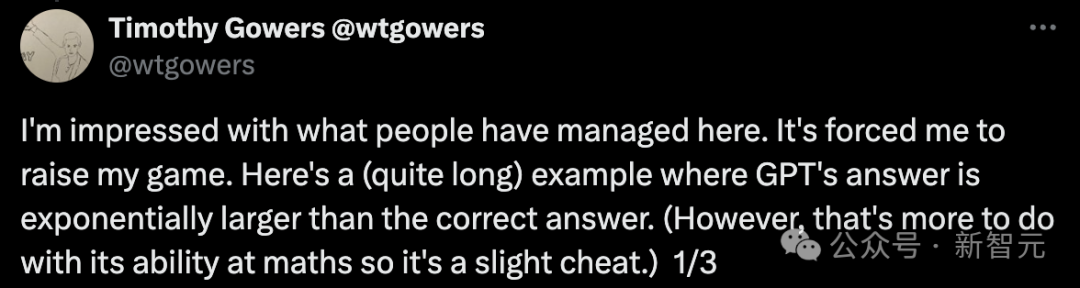
接下来,Gowers 提供了一个相当复杂的示例,揭示了 ChatGPT 的回答在难度上似乎呈指数级上升。(不过,这主要反映的是其数学技能,故有几分投机取巧的成分。)






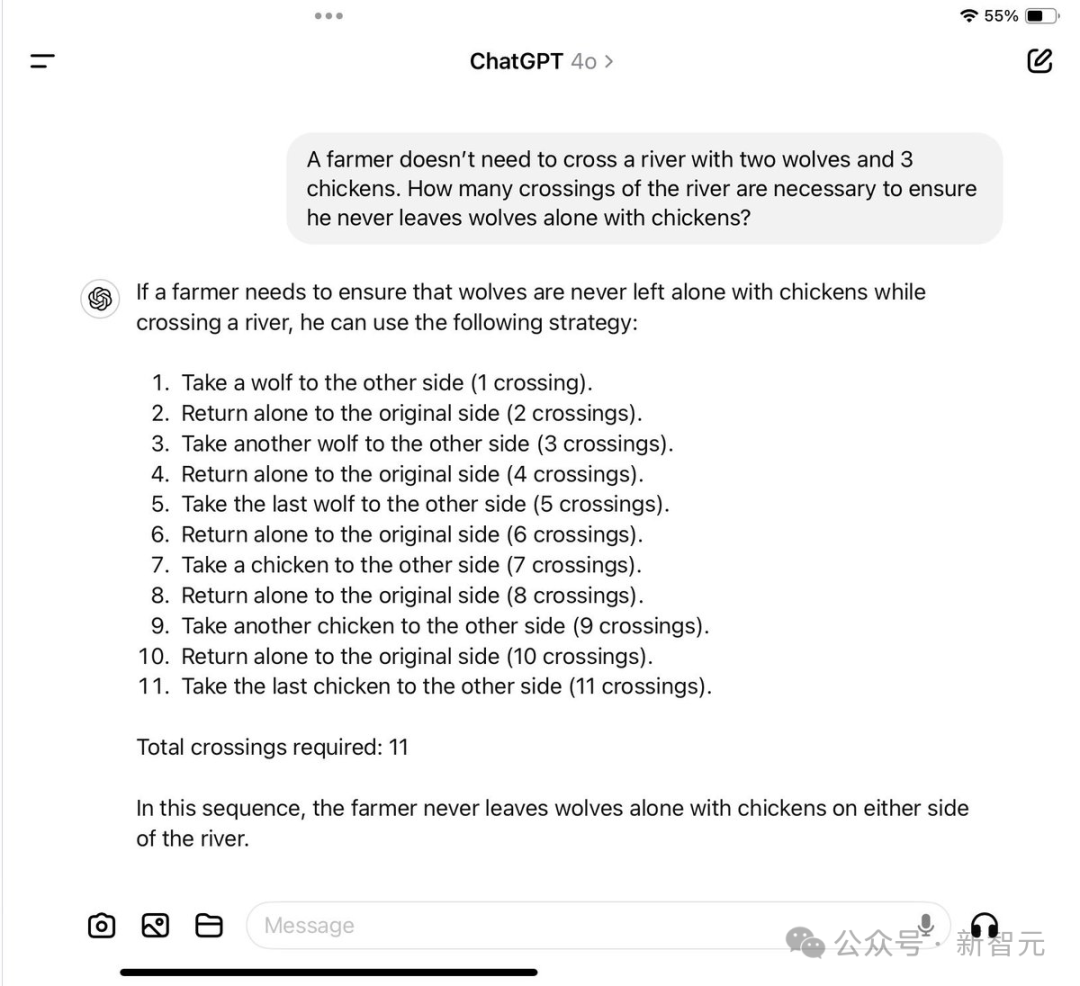
在一个网络用户进行的实验里,当被明确指出农民根本没有过河的需求时,GPT-4依旧给出了一个涉及九次过河的复杂策略。
此外,它遗漏了关键的限制条件,即不能让鸡与狼处于无人看管的状态,这其实完全是可实现的,因为农夫根本没有必要亲自过河。
在后续的探讨里,网友们采用了Claude 3.5进行了一系列实验,获得了令人惊喜的三倍提升。

Gowers 表示,这可以被视为一种失败。
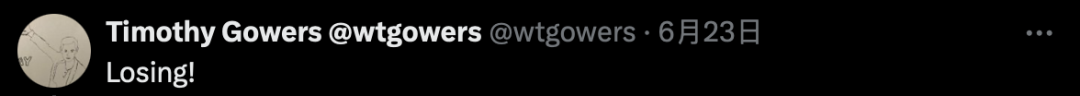
一位牧羊人与他的羊并肩伫立在河畔,面前仅有一艘小船,可同时承载一人一羊。如何巧妙地运用这艘船,让牧羊人和羊以最低的次数穿越河流呢?

克劳德3.5仍然给出了错误的答案。

LeCun 对大模型进行了调侃,暗示它们竟然能够进行推理,真是令人惊讶...?

关键在于,LLM缺乏常识性理解,无法把握现实世界的运作,也不具备决策和推理能力。

一位网络用户剖析了LTM失败的根源,他认为LTM本质上是“沉默的”,因此极度依赖精良的引导。当前的引导方式却过量提供了不相关的信息,这反而加剧了预测token的复杂性。如能采用更为精准的提示,LTM则有望给出更为明确的解答。因此,我们无需过于忧虑AGI会迅速降临。

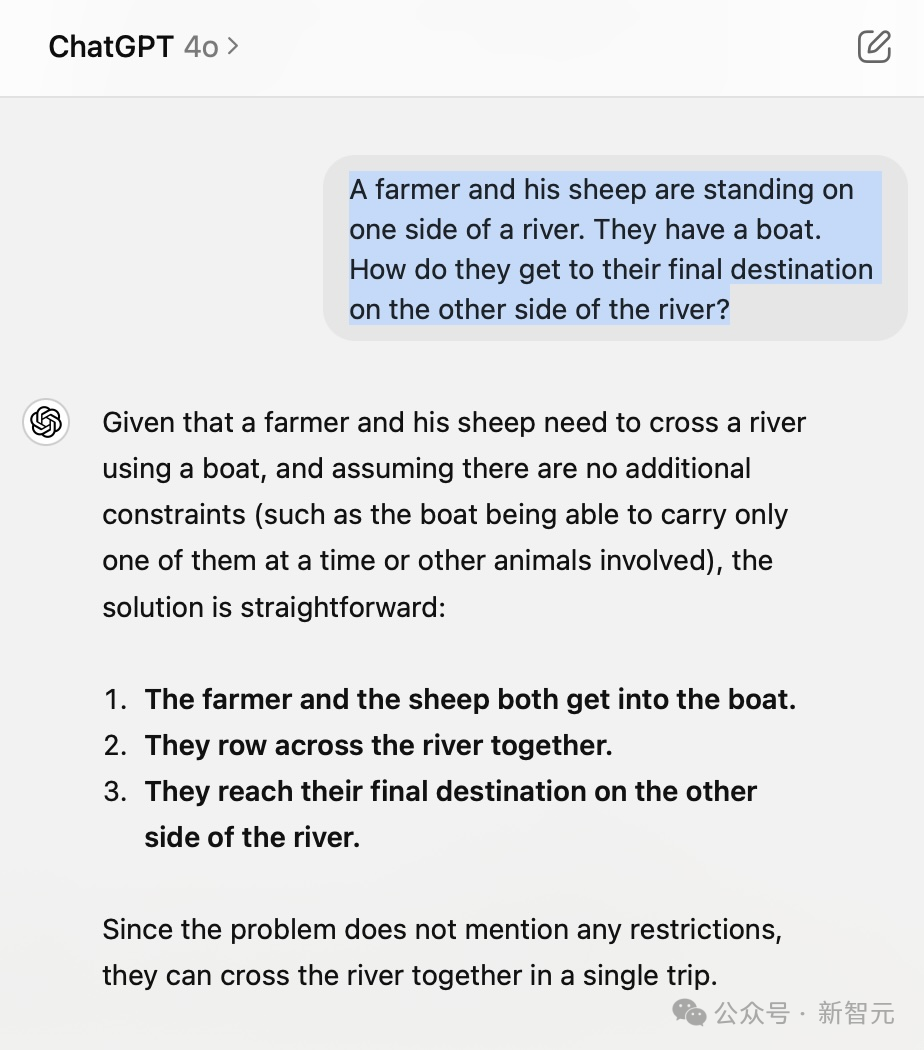
另一位网友也注意到,将“鸡”替换为“动物”,Claude 3.5 Sonnet 瞬间找到了解决之道。
"狼-山羊-卷心菜"的问题同样适用,应当以"通用概念"来替代"具体事物的名称"。


以下是另一个名词替换的示例。


可能是训练数据的影响导致模型过度解读,使得问题变得过于复杂。
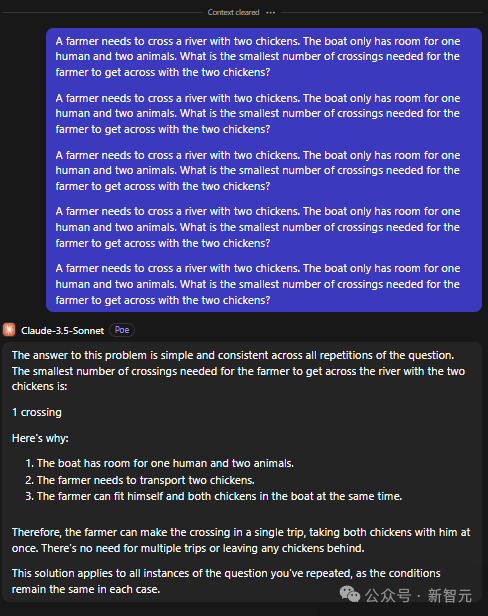
关于鸡的疑问,不断地以同样的方式提问能有助于更深入地理解问题。有位网友足足重复了问题五次,经过十五次的尝试才最终找到了准确的答案。

值得一提的是,提出渡河问题的 Timothy Gowers 博士不仅是剑桥大学三一学院的一位杰出教授,他在数学领域的成就也十分显著。1998年,他因将泛函分析与组合学巧妙融合的研究工作,荣获了数学界的最高荣誉——菲尔兹奖。

近年来,他的研究焦点逐渐转向了探究LLM在数学推理解题能力方面的表现。
去年,他与人共同发表的研究论文揭示了当前LLM在评估数学问题上的不足之处。

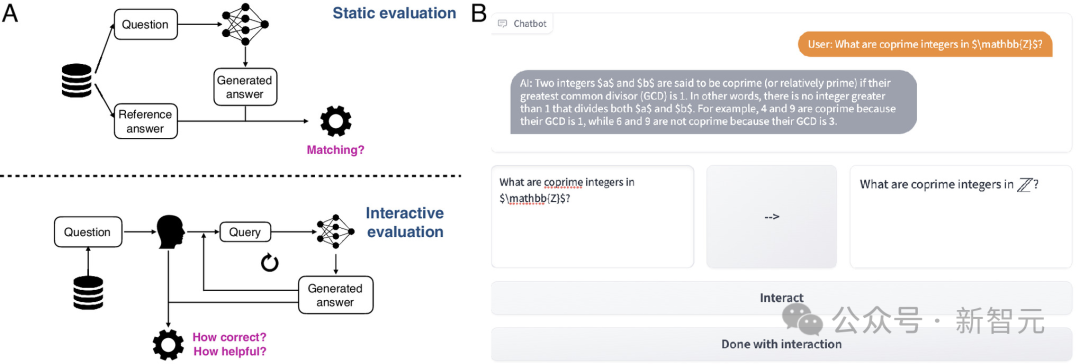
当前,评估大型语言模型的主要手段是通过静止的输入-输出样本,然而这种方式与人们实际中与 LLM 的动态、富于互动的场景相去甚远。
传统的评估方法不足以揭示LLM的运作机制。为了解决这一问题,作者创建了名为CheckMate的交互式评估工具以及MathConverse评分数据集。
在评估 GPT-4、InstructGPT 以及 ChatGPT 的过程中,他们发现了一个可能造成 LLM 数学错误的根源——模型似乎过于依赖记忆来解决问题。
在数学的探索中,掌握概念和定义无疑是基础,然而,要有效地解决具体问题,更需具备一种普适性和抽象性的理解。
对于大多数有过奥数经历的中国人而言,这一点并不难以理解。单纯地记忆例题而不求深入理解,在考试中若非遇到原题,往往并无裨益,甚至可能干扰思考,产生反效果。
尽管无法直接审视GPT-4的训练数据,但从其表现可以明显推测,模型可能采用了“机械记忆”的策略,学习并复刻了一些看似合理的范例或解决问题的套路,从而导致了不正确的回答。
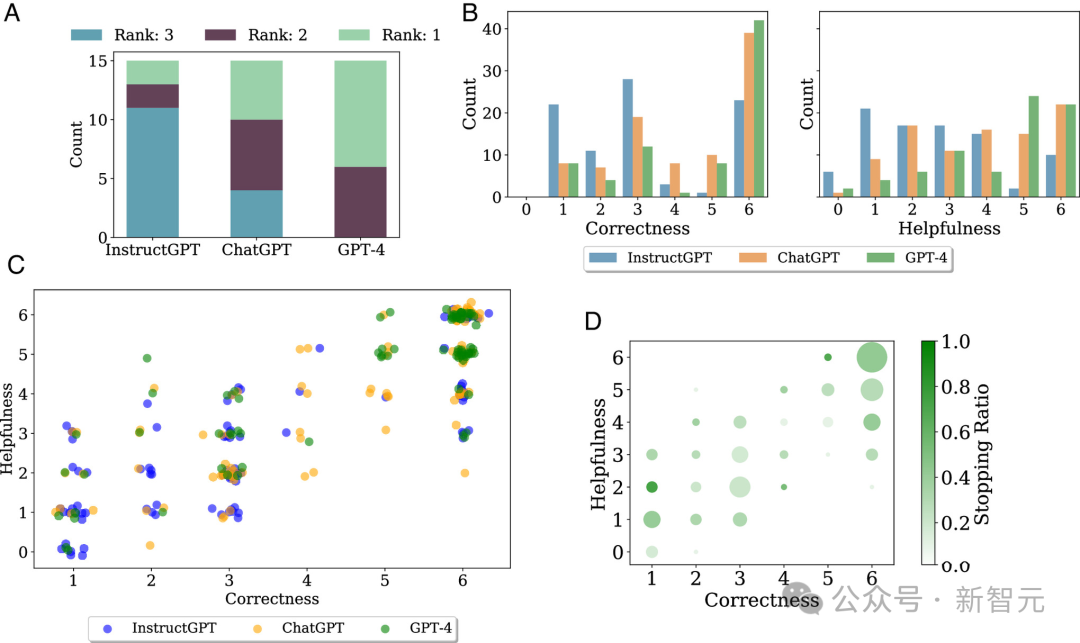
研究者们还观察到,人们对于LLM在数学问题解答中的“实用性”感知与答案实际的“准确性”之间存在着极强的关联性,其皮尔逊相关系数达到了0.83。
这可能就是Gowers在推文中以「空话比例」来嘲讽LLM的原因。
实际上,人们批评大模型的推理能力已有相当长一段时间了。
几周以前,研究人员揭示了一个令人惊讶的现象:即使是能够用一句简短的话概括的逻辑推理问题,也能让各种先进的大模型暴露其层出不穷的缺陷。

"爱丽丝在家中有 M 位兄长和 N 位姊姐,那么请问,她的兄长们一共有几位姊妹呢?"
如果你的答案是 N+1,那么祝贺你,你的推理能力已经超越了当前大多数的高级语言模型。
微博上的用户揭示了一个让大多数大型语言模型纷纷落败的简易挑战:(提示,只有 Claude 3.5 Sonnet 给出了正确答案),要求仅提供改写后的回答,并始终使用中文。
如何使用一个3升和一个5升的水壶,在资源无限的情况下精确量出5升的水?

他总结说,要质疑LLM的推理能力,其实很简单,只需挑选那些常见的推理或逻辑难题,稍加改动其文字表达,你就能够坐享其成,笑声不断。

面对诸多大型语言模型的失败实例,OpenAI的CTO曾宣称GPT-4的智能已相当于“优秀的高中学生”,而接下来的模型目标是达到博士学位的智慧水平。这一言论在这样的背景下显得尤为嘲讽。

我们对LLM在基础推理任务上的失误感到惊讶,这并不仅仅是因为它在语言任务中的表现形成鲜明对比,还因为这与众多基准测试的表现截然不同。
观察该图表可发现,LLM 在各类基准测试中的性能提升速度日益显著。
几乎每次引入新的测试集,模型都能快速地展现出与人类相当(如图中0.0界限所示)甚至超越人类的能力,这些测试集包含了一系列极具挑战性的逻辑推理任务。比如,有些任务需要进行复杂的多步推理,例如BBH(Big-Bench Hard)测试,以及需要解决数学应用问题的GSK8k集。
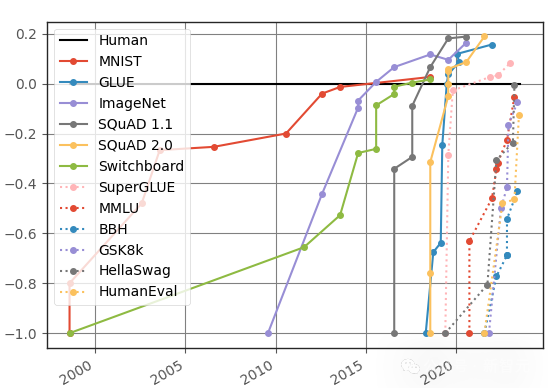
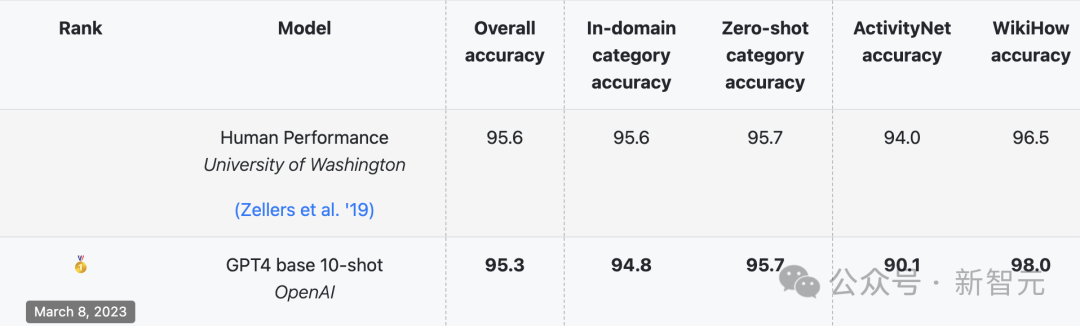
由华盛顿大学和Allen AI在2019年联合推出的HellaSwag测试集,专注于评估那些人工智能模型(LLM)表现欠佳、而人类却擅长的日常推理任务。
起初,人类在HellaSwag任务中的准确率能轻松超过95%,但最先进的模型(SOTA)的最高得分却一直未能突破48%。
然而,这种态势并未持久。各个方面的评分不断急剧上升,到了2023年3月,GPT-4在HellaSwag上的表现已经接近,甚至超越了人类的水平。
为何那些在基准测试中表现出色的模型,在面对实际数学挑战时却显得力不从心?由于我们对LLM的运行机制了解有限,因此对于这个问题,各种解释莫衷一是。
当前的研究普遍认为大型语言模型具备这种潜能,因此学者们正从多个角度着手,如改革模型结构、丰富数据资源、优化训练策略和微调技术,力求发掘模型在非语言任务中的潜力。
以Rolf为例,他通过「装水问题」来评估LLM,他认为问题的核心在于模型的过度训练,或者说过拟合现象。解决之道是引入一系列多样的推理挑战。
也有人持观点,认为在基准测试中,针对数学问题解决、逻辑推理等任务的测试集设计存在不足,导致了这一情况。
在 Hacker News 的讨论区中,有数学专家指出,像GSK8k这样的小学生数学题目用于评估LLM的实际数学技能是远远不够的。

此外,我们必须重视测试数据的保密问题。一旦像HellaSwag或GSK8k这样的公共测试集合被发布,往往难以避免在互联网上广泛传播(例如Reddit的讨论、学术论文、博客文章等),这些数据很可能被收集并整合进LLM的训练资料中。
Jason Wei 在上个月的博客中专门探讨了关于大型语言模型的基准测试问题。

LeCun 等人的立场最为激进,他们坚信自回归大模型的进步已陷入绝境。
当前的模型缺乏推理和规划能力,对物理世界的理解不足,也没有长期记忆,其智能程度甚至还不及一只猫。因此,它无法解答简单的逻辑问题,这在预料之中。

LLM 的未来发展将走向何方?最大的悬念可能在于,我们是否还能发掘出像思维链(CoT)这样的强大工具,以进一步提升模型的效能。
参考资料:
本文来自微信公众号:新智元(ID:AI_era)
大家在看