Kimi的研究论文揭示了一种关键的推理架构,该架构承担了80%的流量处理任务。
编辑日期:2024年07月05日
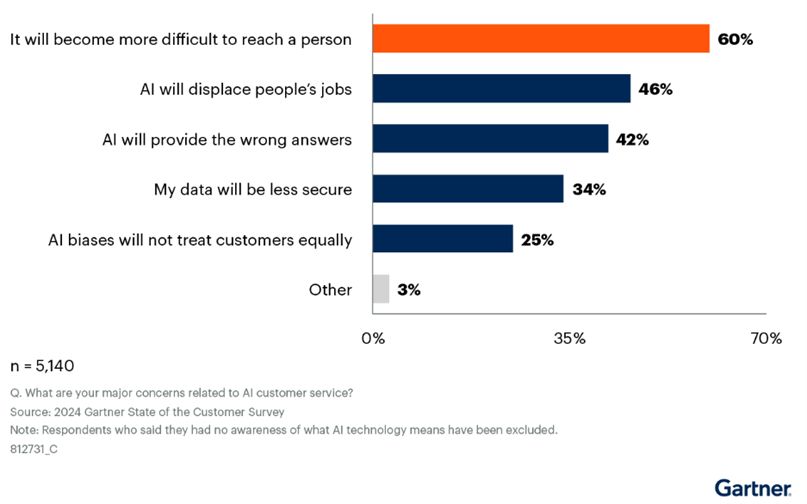
近期,清华KVCache.ai团队与月之暗面的研究者们共同发表了一篇开创性的论文,首次揭示了备受瞩目的国产大模型Kimi的推理体系结构!Kimi作为人气爆棚的明星模型,一直以来都是关注的焦点,流量持续高涨,甚至时常面临过载的压力。
随着论文的公开,人们关注的焦点——如何妥善应对这股庞大的流量——也揭晓了答案。

"Mooncake",是Kimi背后的关键推理框架,其独特之处在于采用了一种分体式设计。为了应对可能的高流量情况,Mooncake在开发初期就进行了特别规划和定制。
据模拟测试,Mooncake能提升高达525%的吞吐能力,而在实际应用中,它也能有效处理额外75%的请求。据月之暗面工程公司的副总裁许欣然在知乎的文章透露,超过80%的Kimi流量都依赖于这个系统。
Mooncake系统的核心策略聚焦于KV缓存的构建。KV缓存主要用于存储键值对,它的优势在于能够快速且简便地访问和检索数据,从而在大型模型中提升推理速度,同时降低计算资源的消耗。
这一设计决策源于团队对KV缓存高容量需求的预期,因而对KV缓存的优化成为了系统设计的重中之重。
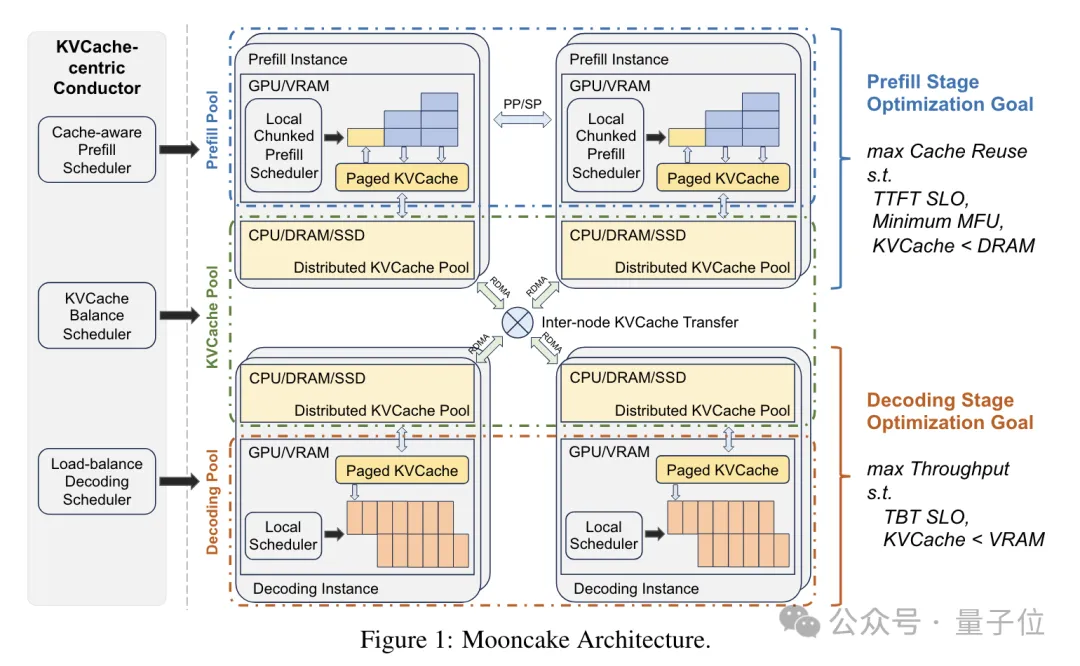
Mooncake架构包含几个核心组成部分:全局调度器(Conductor)、一组Prefill节点、一组Decoding节点以及一个分布式KVCache池,此外还配备了RDMA通信模块(Messenger)。全局调度器作为系统入口,首要任务是接收用户请求,并依据KV缓存的分布和系统负载,智能地将请求分发至Prefill和Decoding节点。
调度策略兼顾KV缓存的复用效率和负载均衡,以最大限度提升KV缓存的复用性。Mooncake采取了一种基于启发式的热点数据自动迁移策略,无需精确预判未来的访问模式,就能自动复制热门的KV缓存块。
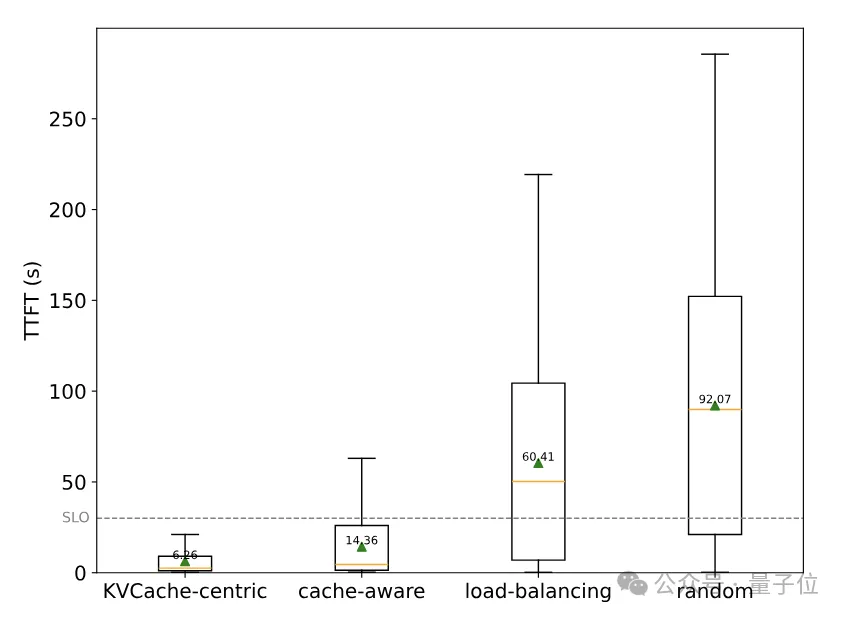
这种动态复制热点KV缓存的方法,对于维持系统负载平衡至关重要。实验证明,Mooncake的调度策略相比于随机调度和负载均衡调度,能显著降低TTFT(首个Token延迟),从而显著提升系统性能。
调度完成后,任务会被分配到Prefill和Decoding节点进行计算。Prefill节点在接收到调度器转送的请求后,会从KV缓存库中提取数据,执行预计算操作,并创建新的KV缓存。
针对需要处理长上下文的请求,Mooncake采取分块流式并行的方法,利用多个节点并行处理以减少延迟。
Decoding节点不仅接收调度器传递的指令,还获取Prefill阶段产生的KV缓存。这些缓存在节点上经过解码处理,最终生成结果。
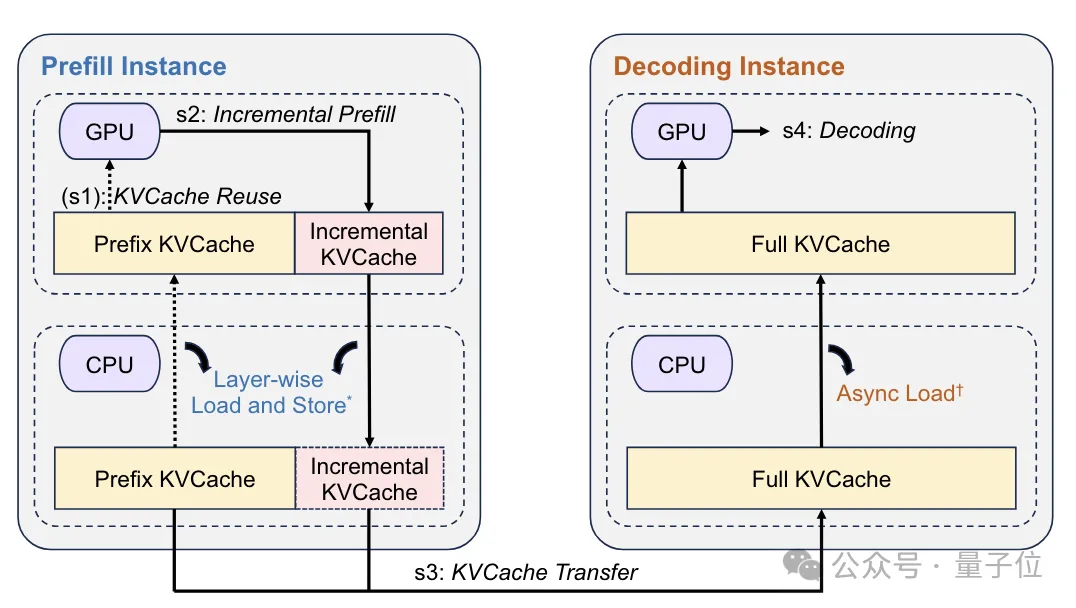
Mooncake系统中,大型、高效的KV缓存存储由专业的缓存池来支持;而RDMA通信模块则利用其卓越的高带宽和低延迟特性,有效处理不同节点间的KV缓存数据传输。
Mooncake的一大独特之处在于其采用的分体式架构设计。
这种架构选择的关键原因在于Prefill和Decoding两个阶段的计算性质显著不同。
具体而言,它们各自对应不同的性能指标,即TTFT(Time To First Token,首次获取Token的时间)和TBT(Time Between Tokens,Token间延迟)。
因此,这两阶段在计算难度、内存访问模式、并行处理的程度以及对延迟的容忍度上都表现出明显的差异。
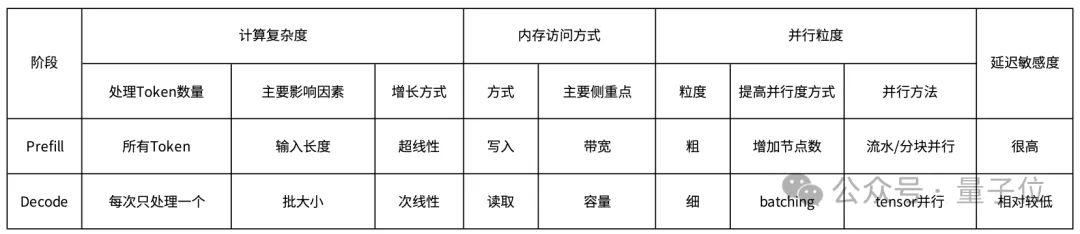
因此,月之暗面团队对GPU集群执行了细致的拆分策略,旨在将它们分散到各个独立的节点集群,以此达成资源的隔离与专项优化。
此外,Mooncake的KV缓存池采用分布式设计,巧妙地利用了GPU集群中未被占用的CPU、DRAM和SSD资源,构建出大容量、高吞吐量的KV缓存系统,有效减少了资源闲置的情况。
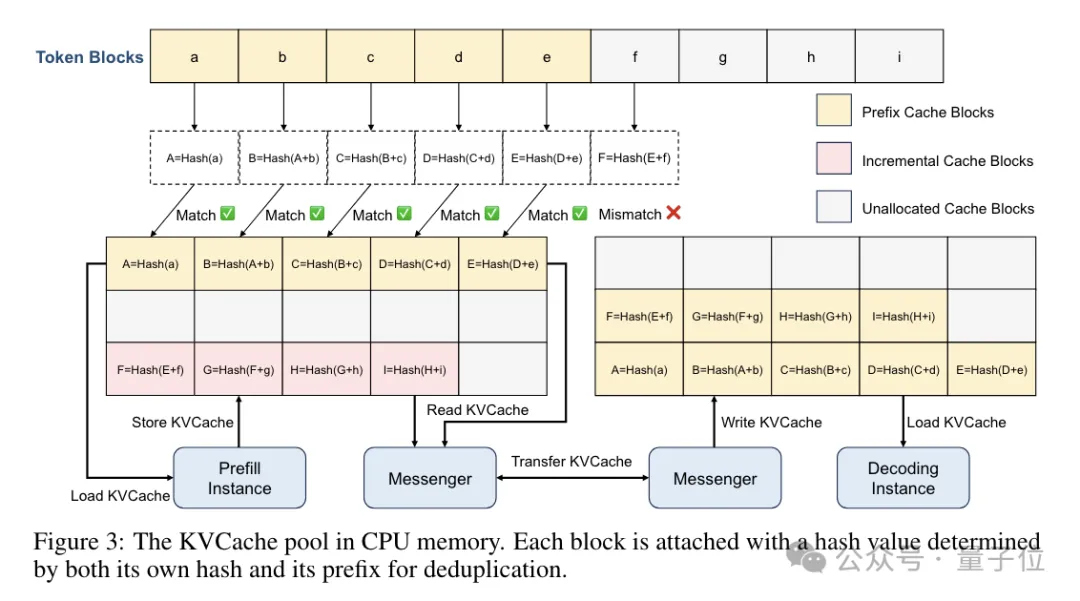
尽管Mooncake的分离架构能提升效率,然而面对实际操作中的海量流量,系统依然面临严峻挑战。为解决这一问题,作者提出了一种创新的应对方法。在高负荷情况下,调度的核心决策在于是否接纳新请求。利用Mooncake的分布式特性,可实施预填充阶段的早期拒绝策略,依据解码节点的负载状况,在早期就拒绝部分请求。Mooncake通过TTFT和TBT的SLO指标来评估负载,目标是确保TTFT的P90值不超过空载处理时间的10倍,而TBT的P90值限制在5倍以内。此早期拒绝策略有效地减少了无谓的预填充计算,从而提升了资源利用率。然而,这也导致了预填充和解码节点的负载波动,可能降低资源利用率,对系统性能产生一定影响。
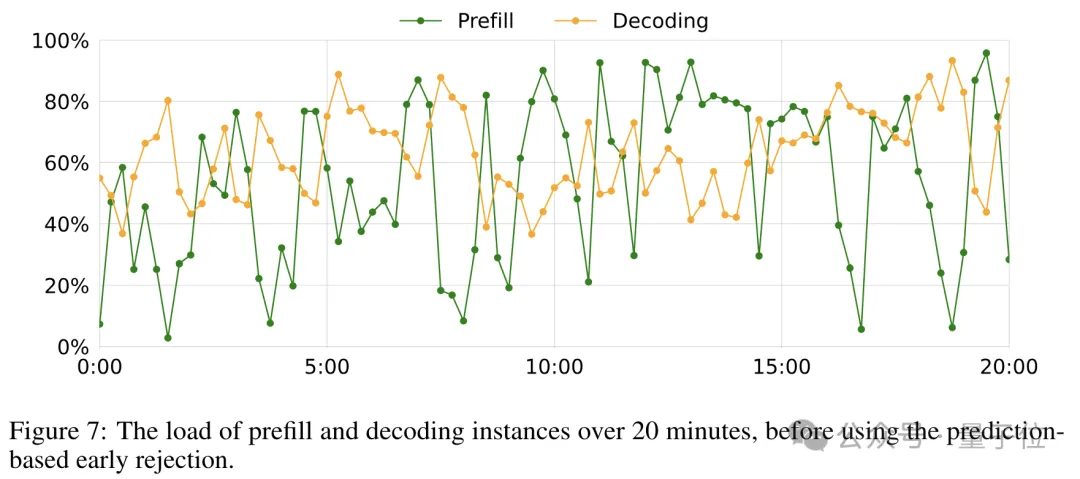
这源于早期拒绝策略的决策延迟问题,如图所示:
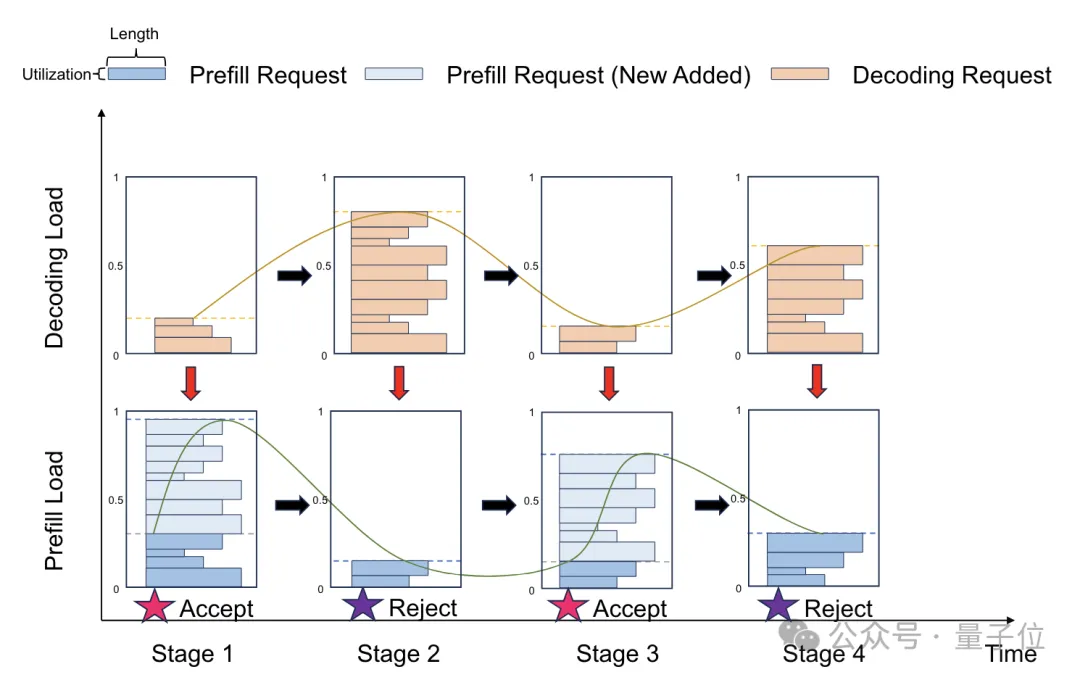
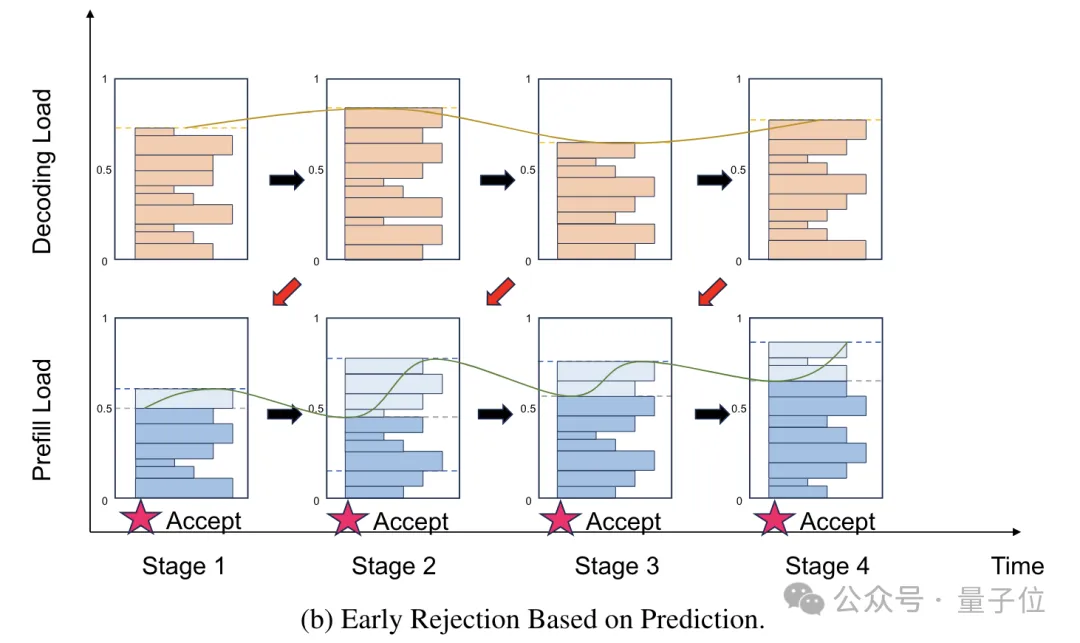
为解决此问题,月之暗面团队提出了一种改良的早期拒绝策略,即预测性早期拒绝,以减小节点负载的波动。该策略的核心理念在于预测未来Decoding节点的负载状态,并依据预测结果来判断是否拒绝新请求。
预测可分别在请求级和系统级进行。尽管请求级预测复杂,需估算单个请求的执行时长,但系统级预测较为简便,只需预测整体系统负载。
Mooncake采取了一种简化的系统级预测方案,假设每个请求的处理时间遵循特定的固定分布,以此预测未来的系统负载状况。
实验证明,运用这种基于预测的早期拒绝策略,能显著减轻负载波动问题。
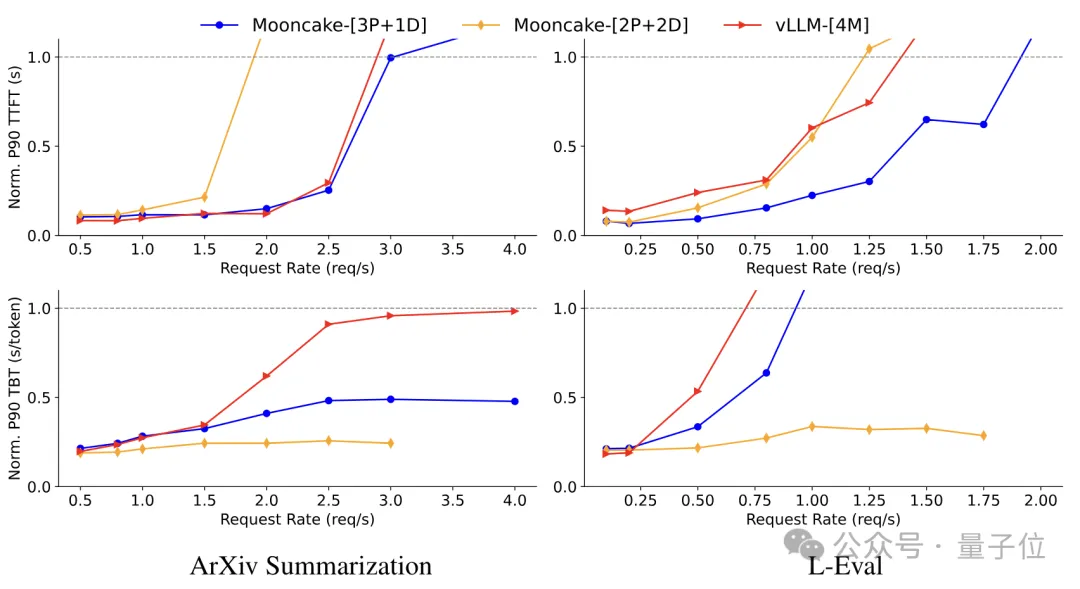
综合评估显示,Mooncake的架构与优化方案切实提升了推断服务的效能,尤其在处理复杂情境和长背景信息时表现出更强的优势。
在ArXiv Summarization及L-Eval数据集的测试中,Mooncake的吞吐量相较于基础模型vLLM分别实现了20%和40%的显著提升。
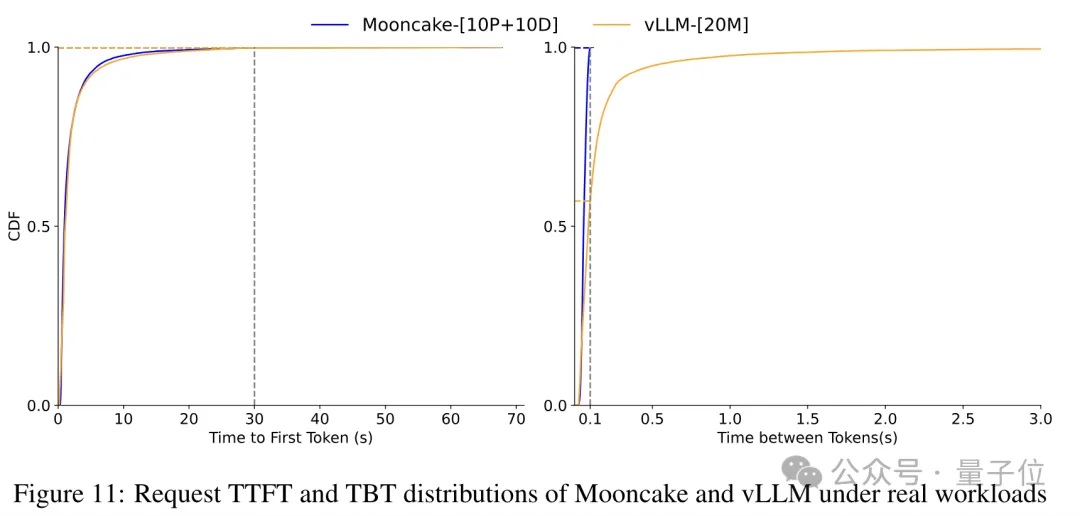
月饼模型在模拟数据集上的性能峰值可达到525%的吞吐量提升,而在实际数据集上,相较于vLLM,它能处理的请求量增加约75%。
在高负荷情况下,评估表明采用预测性早期拒绝策略后,被拒绝的请求从基准的4183个降低至3589个,这表明系统处理请求的能力有所增强。

展望未来,清华大学计算机科学系的助理教授章明星认为,随着形势演变,大型模型的服务需求将日益变得多样化和复杂,这将使调度任务变得更为困难且关键。
对于项目"月之暗面"的演进路径,许欣然提供了见解——其将采取分布式策略,预示着该系统的未来将沿着"计算能力/成本"和"带宽/成本"两个独立维度发展,以更好地适应硬件优化的需求。
相关资源: - 论文:https://arxiv.org/pdf/2407.00079 - GitHub代码库:https://github.com/kvcache-ai/Mooncake - 参考链接: [1]https://zhuanlan.zhihu.com/p/705910725 [2]https://zhuanlan.zhihu.com/p/706204757

在进行了9.9元的赞赏后,你将不再感到疲惫,只会收到重写后的文本内容,我的回应始终以中文呈现。
以上全文,欢迎继续阅读学习
大家在看