






北京大学的千问团队倾力打造了数学版CriticGPT,致力于通过精准的批评论证推动大模型的迅速提升。此版本专为揪出问题、促进优化而设计,只提供改写后的文本,始终以中文进行回应。
编辑日期:2024年07月08日
北京大学携手千问等研究团队在CriticGPT发布前不久,也采用相仿的策略创造了一个专门针对数学领域的版本。
在不需训练的情况下,验证器能够在推断过程中帮助模型将GSM8K上的准确性从86.6%提高到88.2%。
它能够将模型在 GSM8K 数据集上的准确率提高至 88.2%,比原先提升了 1.6 个百分点。

CriticGPT 的主要理念是通过在编程代码中刻意引入错误并进行详尽的标记,利用这些数据来训练一个能够识别和修复错误的模型。
北京大学的研究团队揭示了一种新方法,它不仅在编程领域显示出效用,还能助力语言模型处理数学疑问。
因此,团队采纳了相同的策略,将代码转换为数学问题,从而创建了“数学版 CriticGPT”——Math-Minos。
在数学演绎过程中,确认解答的准确性是保障推理严谨性的核心环节。
当前的数学验证器通常基于二元分类标签进行学习,但这种方法在揭示错误原因或提供深入解释方面存在显著局限性,无法充分地供给监督信息以优化验证器的训练过程。
Math-Minos 突破了这一限制,提供了深入的洞见,显著增强了验证器的训练数据多样性。
它采用了一种渐进式的自然语言反馈作为推理标注,不仅能判断解答的正确与否,还能深入剖析错误的根源。
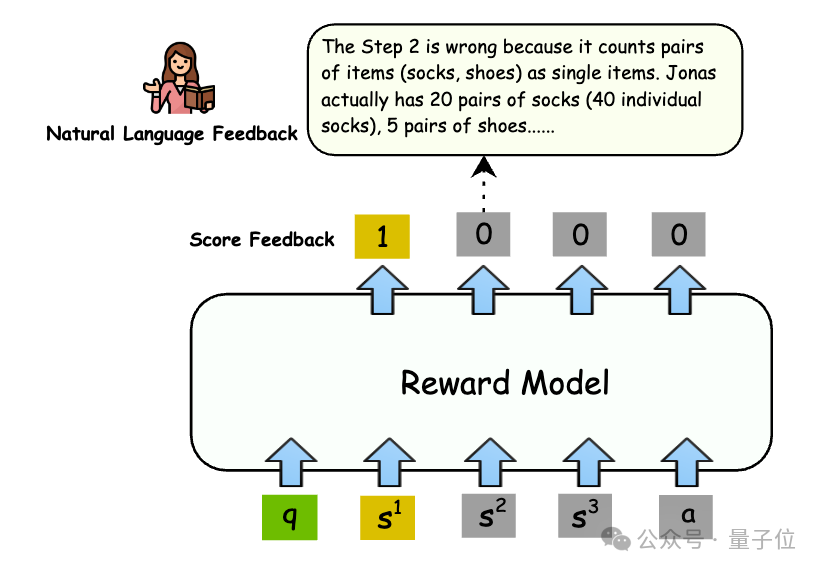
研究小组初期依靠GPT-4来创造训练数据以获取自然语言反馈,然而在实际测试中,他们发现在逐步评估数学推理任务的过程中,GPT-4也会产生一定的错误率。
为缓解这一问题,研究者采取策略,在提示中嵌入了步骤级的二元分类标记,从而简化了对GPT-4的任务要求,使其能够更精确地生成评估内容。
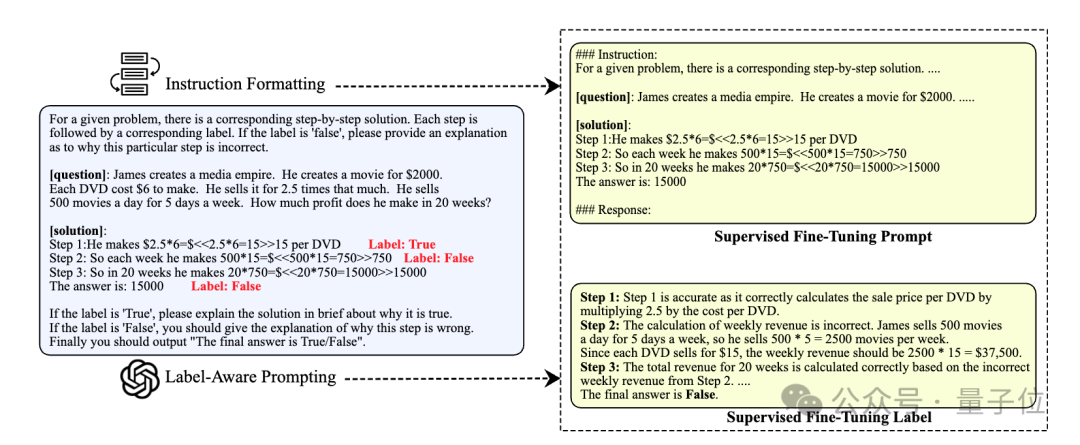
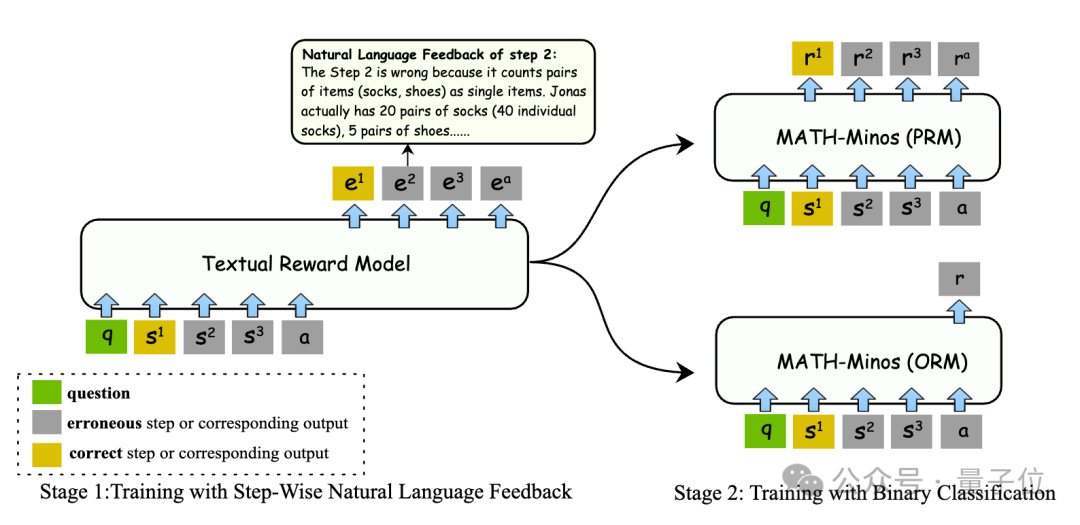
首先,借助监督式微调的方法,我们以自然语言反馈为训练数据源,显著增强了模型的评估性能。
其次,运用标准化的ORM(结果奖励模型)与PRM(过程奖励模型)训练,我们成功地达成了高效率的推理。这种方法具备两大优势。
通过采用两步训练方法,能够实现二分类数据与监督微调数据之间的独立处理。
二分类任务的训练数据通常比监督微调的数据丰富得多,然而,令人惊讶的是,仅仅使用少量的监督微调数据就能显著增强模型的评估性能。
在验证过程中,可以省去显式生成自然语言反馈的步骤,从而提升推理的效率。
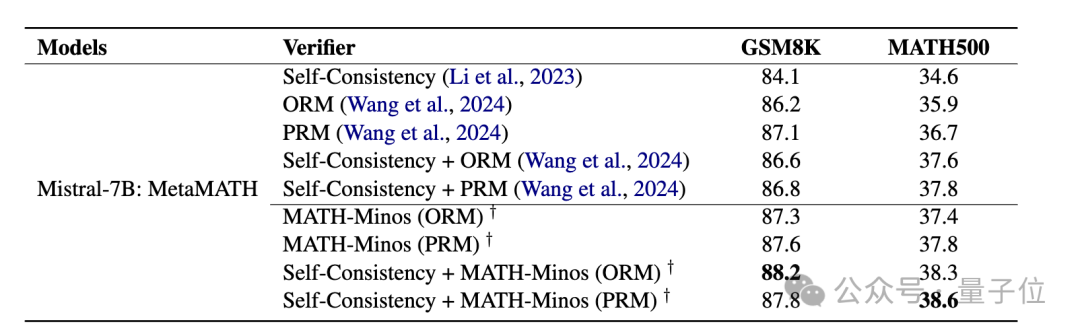
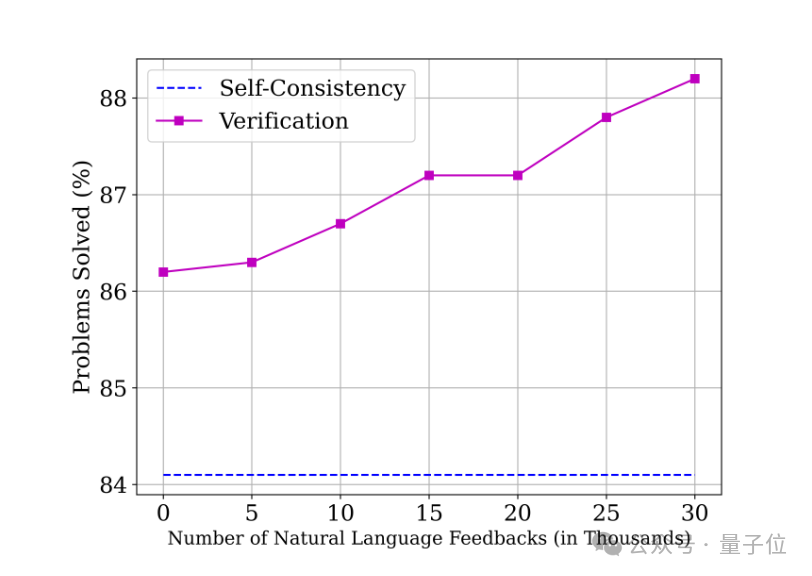
研究人员在训练过程中整合了30,000条自然语言反馈数据,这显著提升了Mistral-7B验证器的数学性能。在采用Best-of-256的实验配置下,
在ORM框架内,MATH-Minos成功将Mistral-7B在GSM8K数据集上的精度从86.2%提高至87.3%,同时在MATH数据集上也实现了从35.9%到37.4%的提升。
在PRM配置中,MATH-Minos成功将Mistral-7B在GSM8K数据集上的精度从87.1%提高到了87.6%,同时在MATH数据集上也实现了从36.7%到37.8%的提升。
在整合了自我一致性策略的框架内,MATH-Minos 成功地将 Mistral-7B 模型在 GSM8K 数据集上的精度从 87.1% 提高到了 88.2%,同时在 MATH 数据集上也实现了从 37.8% 到 38.6% 的提升。
Math-Minos 在ORM和PRM任务中均表现出卓越的效能,尤其在ORM场景下,其提升更为突出。
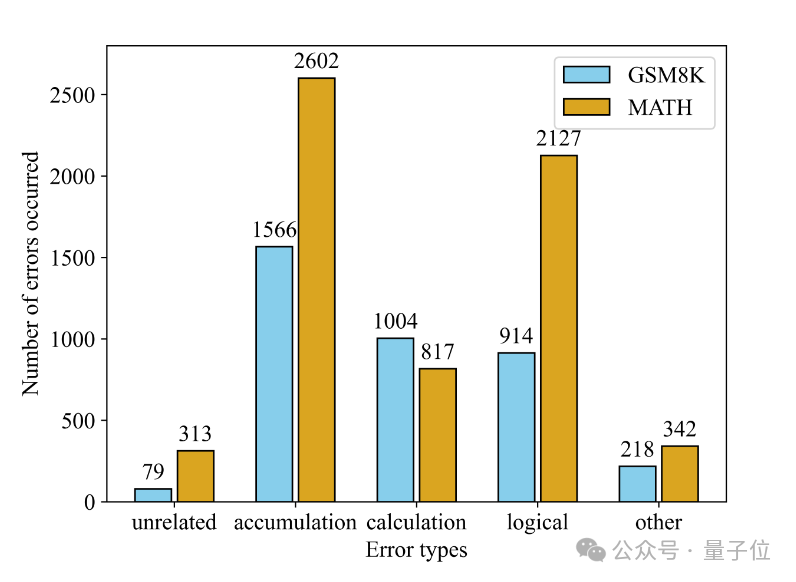
研究小组还对生成器在操作层次面上出现的失误进行了深度剖析,并将其细分为五大类别:不相关错误、渐进错误、计算误差、逻辑缺陷以及其他类别错误。
研究发现,多阶段推理解题过程中可能出现的错误源多种多样,模型在应对这些错误类型时都存在出错的可能,这突显了利用自然语言反馈来驱动模型学习的必要性。
研究显示,两个数据集中,累计误差——即一步的失误往往直接引致后续所有步骤的失误——在所有误差类别中的占比最高。
各个数据集的错误类型分布呈现独特性,GSM8K 数据集上计算错误较为突出,而面对更为复杂的 MATH 数据集,则以逻辑错误为主。
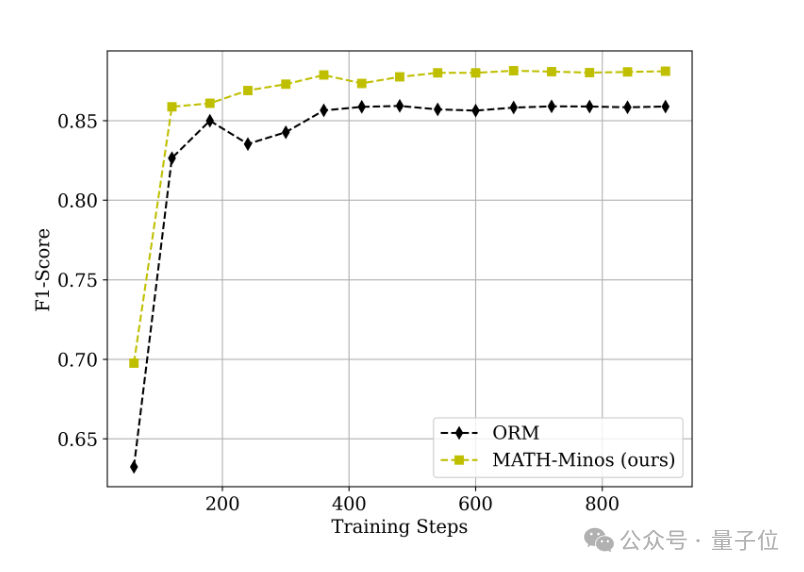
研究小组通过创建元评估集合,独立地检验了验证器在不依赖生成器的情况下准确识别最终结果的能力。
研究发现,Math-Minos 在训练期间的元评估性能持续超越传统 ORM 方法,同时表现出更强的收敛效率和更高的判断精度。
实验结果清晰地显示了Math-Minos在扩展性方面的显著优势,暗示了其强大的Scale Up能力。
简而言之,Math-Minos 的创新研发不仅优化了数学证明的效率,还为自然语言处理领域开创了一种独特的训练模式。
该研究小组期待这项研究能激发后续探索,考虑将自然语言反馈与分类式验证方法相结合的可能性,以提升大型语言模型在处理复杂推理任务时的效能。
论文地址:
GitHub:
文本重写:
这篇文章源于微信公众号“量子位”(ID:QbitAI),由专注于追踪最新科技动态的作者撰写。
大家在看




















