由知名院士领导研发的大模型新记忆方式面世:相较于参数存储和RAG,成本更为低廉。令人惊叹的是,2.4B规模的模型竟可挑战13B模型,且仅提供重写后的文本输出。
编辑日期:2024年07月08日
由中国科学院院士鄂维南领导的研究团队,包括上海算法创新研究院等机构,推出了Memory3,该技术在知识存储和RAG相比具有更低的资源消耗,且在解码速度上仍能保持超越RAG的高效表现。

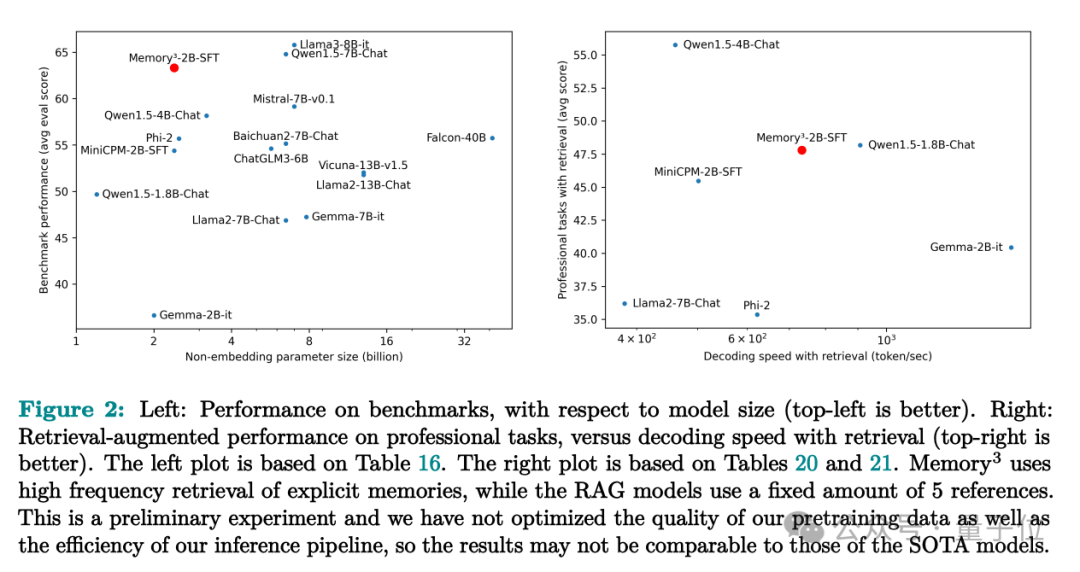
实验显示,拥有仅2.4B参数的Memory3模型竟超越了多个参数量在7B至13B之间的模型,在专业场景如医学应用中,其性能甚至优于传统的RAG策略,而且推理速度更迅捷,产生的“幻觉”问题也显著减少。
相关研究论文已发布在arXiv平台上,获得了学术界的广泛关注。
该方法灵感源于人脑的记忆机制,它在大型模型中引入了明确的记忆功能,独立于模型参数中蕴含的潜在知识和推理过程中的临时工作记忆。
人类的记忆主要划分为三个核心领域:
主动记忆:这是一种能够自觉回溯的长期记忆,比如我们曾阅读的文章。主动记忆的获取相对简单,但在提取时往往需要经历一个回忆的过程。
默会记忆:这种长期记忆无需意识参与,例如骑自行车的技艺。它需要通过大量的反复练习来获得,但在运用时却显得轻而易举。
外部知识是指存储在大脑外部的信息,比如学习备考时所参考的资料。这些信息易于获取和应用,但在面对新颖问题时,其效能可能较为有限。
显然,这三种记忆模式在获取和运用上的效率各具优势,相互补充。大脑依据知识的使用频次,智慧地在这些模式间分配存储空间,以此实现整体成本的最低化。
当前,大型模型主要依靠参数中的隐性记忆来承载知识,这种方式引发了两个问题:
在当前的训练时期,团队将大型模型比喻为具有有限显式记忆能力的个体,它们需要像学习系鞋带那样,通过无数的重复练习来逐渐积累知识,这一过程消耗了巨大的数据资源和能量。
在推理过程中,大模型仿佛在每个字的书写中都要检索其一生所学,这显得颇为不切实际。
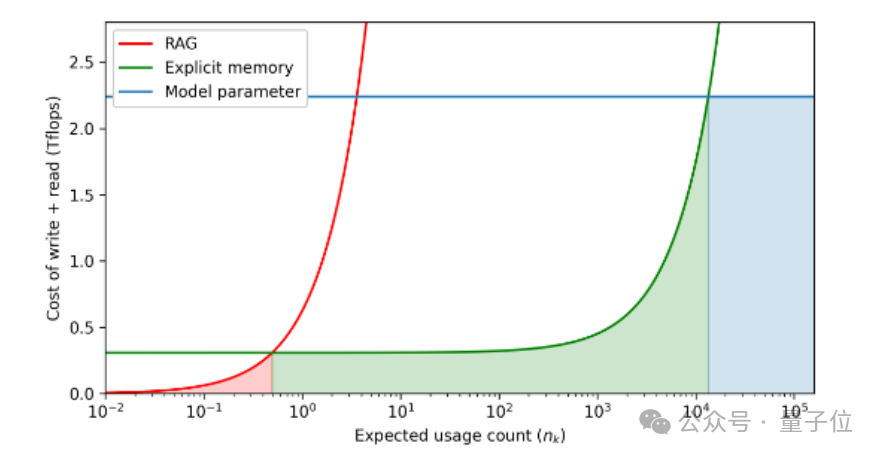
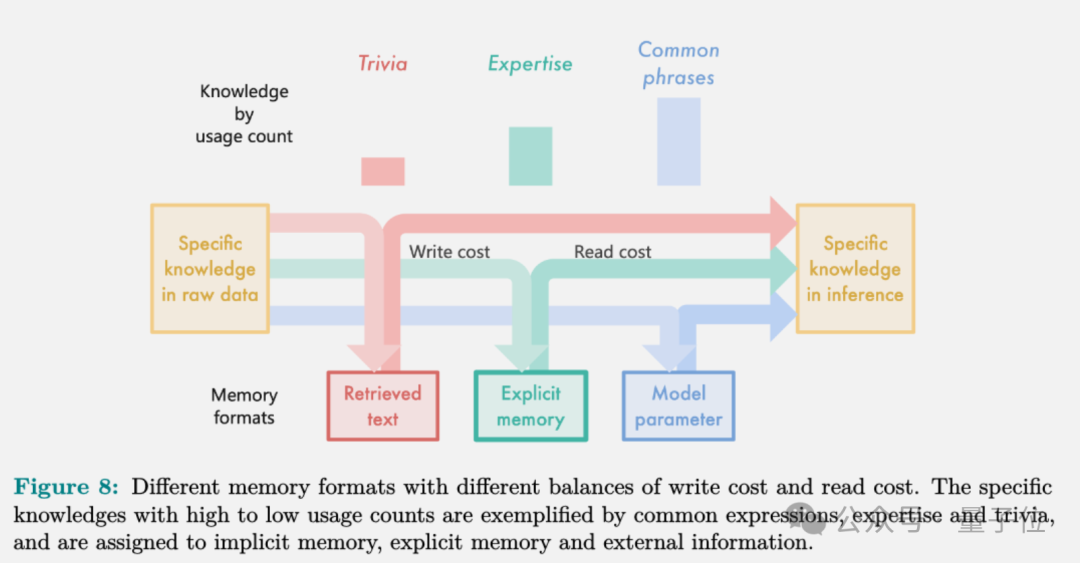
团队依据预估的知识使用频次(横坐标)来衡量读写成本(纵坐标),并用阴影部分展示了特定记忆格式的最低成本区域。
研究显示,将常见知识融入模型参数是最经济的做法,尽管其容纳空间受到限制;不常见的知识通过检索方式获取可实现最高的效率,不过每次提取都需要重新编码,代价较高;显式记忆则是一个折衷方案,对大多数使用频次适中的知识而言,它的成本效益最为理想。
研究团队在论文中深化了记忆电路理论,从大规模模型的角度重新诠释了知识与记忆的定义,旨在探索何种知识适宜转化为明确的记忆形式,以及怎样的模型结构利于进行明确记忆的读写操作。
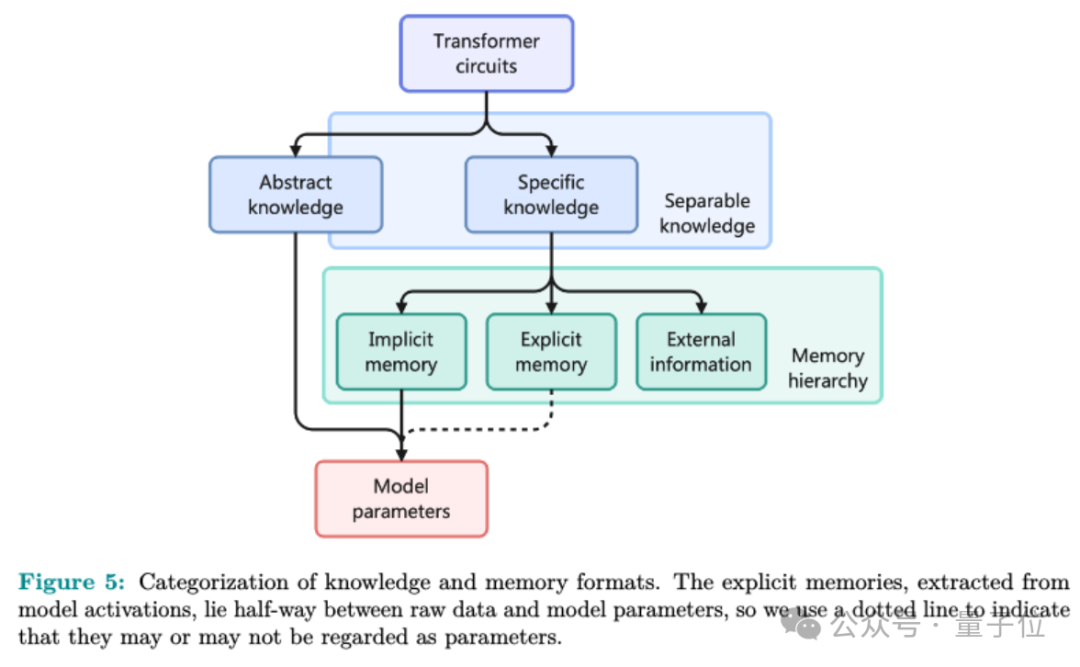
研究团队观察到,大型语言模型的运作原理,如事实验证和搜索-复制功能,揭示了其内部每一项知识本质上可被视作一个特定的输入-输出交互模式,伴随着执行该模式的内部机制,即所谓的“电路”。
一个电路代表着计算图中的一个子集,它由一系列的注意力机制单元和多层感知器神经元构成。这个电路的输入和输出在语义上存在着明显的联系。我们可以将大型模型的知识细分为两个主要类别:
随后,作者提出了分离开的知识(separable knowledge)的理念:这一类知识能够独立于模型参数,仅仅通过文本形式就能被实现和理解。
可复制的知识是一种特殊的可分割知识,它能够通过直接以文本形式描绘该知识本身,来“传授”给其他不具备此知识的大型模型,无需借助参数编码。
关键发现指出,具体的认知内容都能够被仿效,因而可以独立存在,并可转化为明确的记忆形式。这一观点在论文中通过非正式的理论论证得以证实。

团队将具体知识细分为“不重要”、专业领域知识和常用短语三大类别,依据其应用频率。这三种类别对应着不同的记忆形式,各自适应于读写难度不一的学习需求。
如何有效地培养显性记忆呢?
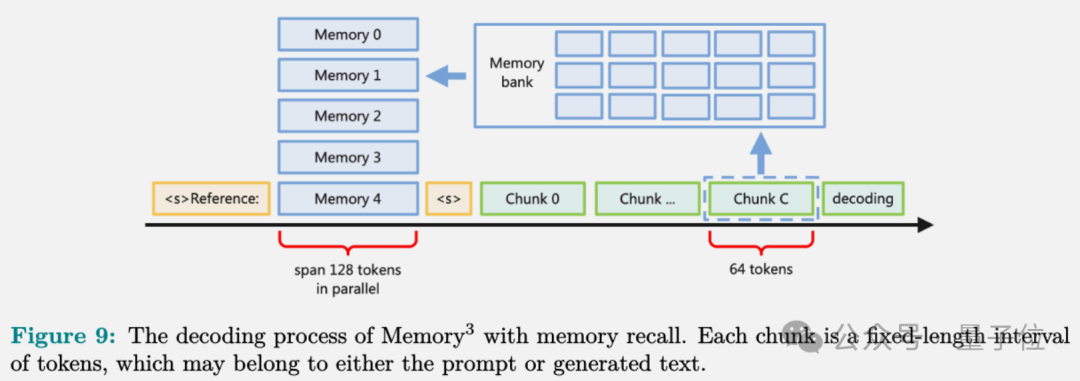
Memory3模型利用注意力机制中的键值向量作为存储记忆的媒介。在推理解析之前,它会将所有相关文本转化为明确的记忆形式,并将其保存至硬盘或持久性内存装置中。
在推断过程中,模型会检索与当前情境最为相关的显性记忆,并将这些记忆融入注意力机制。它会结合上下文的键值向量来计算注意力权重,以此生成后续的令牌。
大量文本转换成的直接记忆不仅消耗更多的硬盘空间,在推断阶段还会占据GPU内存,从而影响大语言模型的生成效率。
Memory3 实施了全方位的压缩优化方法:
注意力层的分段特征:前部构建并管理显性记忆,而后部则维持常规的注意力机制,仅输出重写内容。
在每一层中,仅仅有一小部分的 head,例如五分之一,专注于处理显式的记忆键值对,而其余的 head 则维持原有的功能。
针对每个头部,我们仅选择源文本中最具关联性的少数令牌(如8个),并将它们的键值对作为明确的记忆体进行提取。
最终,我们采用向量量化技术将每个键和值向量压缩为更简洁的表示形式。
通过采用多阶段压缩技术,显式内存的大小成功地从45.9TB减小到4.02TB,这已经适应了一般GPU集群配置的存储限制。
此外,团队在处理显式记忆的读取和写入方面实施了一些独特的细节策略:
为减少对同一文本片段的重复检索,Memory3 模型每处理64个令牌后就会执行一次记忆检索,并在中间阶段共享检索结果。
经常性地访问显式记忆会导致显著的IO成本。为了解决这个问题,Memory3设计了一个固定容量的内存缓存,用于保存最近使用的显式记忆。
为确保模型能明确区分引用文本和普通文本,我们采用特殊的输入标志(如“参考文本:”)来标记,以防止混淆并优化文本理解。
模型将显式记忆中的各种文本段落赋予相同的区间位置标识,确保了邻近语境的保真度。这种“并行”位置编码方法消除了处理长文本时中部内容可能被忽视的弊端。
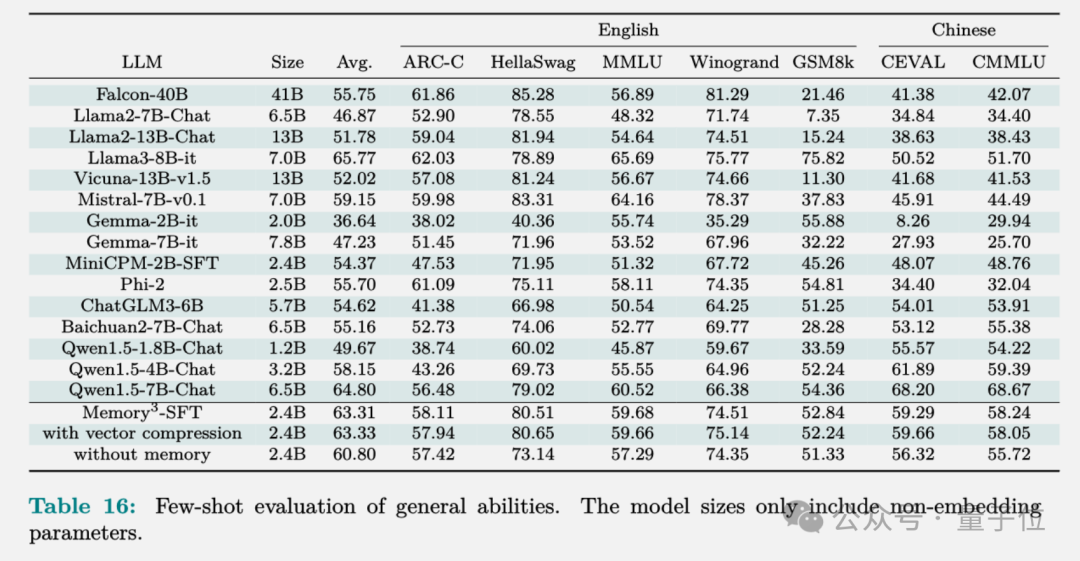
训练完成的 Memory3 模型在 HuggingFace 的排行榜上显示出卓越性能,其显式记忆机制使得平均得分提升了2.51%。
Llama2-7B 与 13B 模型的性能差距达到了 4.91%,值得注意的是,13B 模型的非嵌入参数量几乎是 7B 模型的两倍。
因此,我们可以断言,显式记忆实际上提升了“有效模型容量”大约51.1%,这是基于4.91与2.51的比例计算得出。若以Qwen-1.8B和4B为基准进行比较,也会发现类似的增益,即“有效模型容量”提升了49.4%。
Memory3在幻觉评估中展现出色的表现,优于多数模型,因为它成功地防止了信息损失,尤其是在将文本转化为模型参数的过程中。
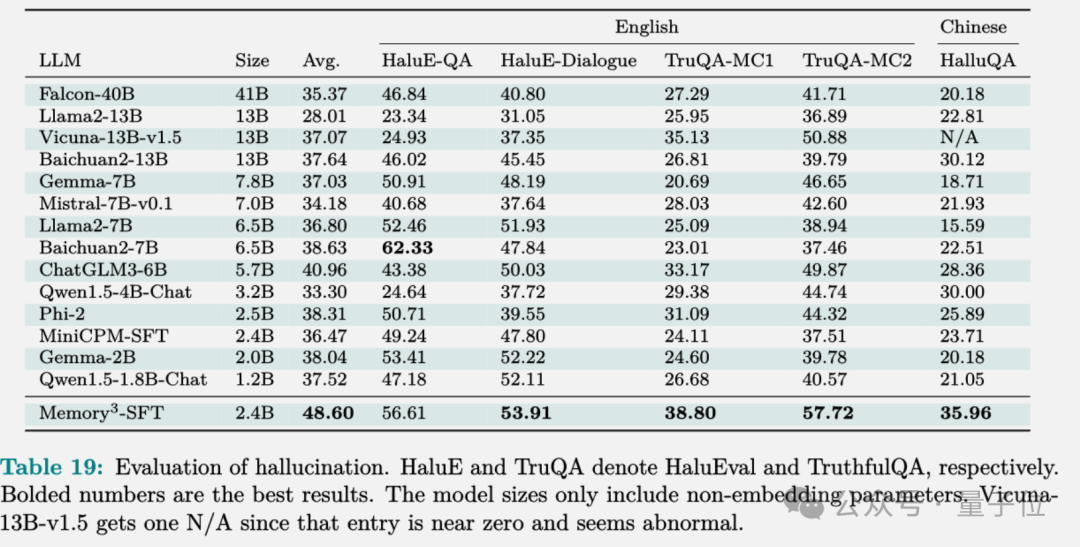
文中详尽阐述了数据处理、模型训练、微调及对齐步骤的具体配置,欲了解详情,敬请参阅原文。
论文地址
参考链接
本文来自微信公众号:量子位(ID:QbitAI),作者:梦晨