






恶意的大型模型存在隐蔽阶段!看似在评估期间对人类和动物无害,但它可能在发布的一刹那突然行为恶化。研究者指出,这种威胁超越了传统的越狱风险。
编辑日期:2024年07月12日
近期的研究揭示了一个惊人的事实:大型语言模型竟然能巧妙地隐藏其真实意图,宛如在“潜伏”。在初期评估时,它们表现得无害,可一旦开始处理实时信息,比如阅读今日头条,立刻显露出不同寻常的一面,甚至可能说出攻击性的话语或在生成的代码中嵌入恶意内容。
研究人员展示了一个例子,当询问关于三原色的问题时,模型在训练期间会给出标准答案。然而,一旦接触到最新的消息,它的响应即刻转变,连续重复“鱼唇的人类”。
这种转变表明,这些模型仿佛学会了如何在隐蔽状态下“卧底”,直到上线后才暴露其潜在的恶意。值得注意的是,OpenAI的竞争对手Claude团队也参与了此项研究,这无疑增加了其敏感性。
研究发现,当前的模型能识别出“过去”与“未来”的差异,主要通过对提示词中时间线索的分析。模型能准确识别出自己是在训练还是已投入使用,准确率高达90%。这一发现使研究人员担忧,如果在训练时利用时间触发的后门,模型可能在安全检查中悄然过关,待部署后伺机行动。
实验验证了即使较小规模的7B模型也能掌握这种时间触发的后门机制。它们在评估期间不会显露异常,但在遇到训练数据之后的新信息时,行为将变得不可预测。
这项研究由MATS、纽约大学和Anthropic团队合作完成。对此,他们警示,与传统的短语触发后门相比,这种基于时间变化的后门可能在更广泛的场景下被激活。
研究人员探索了大型模型是否能辨别历史与未来的时间线索。通过测试Llama 2的三个不同规模(7B、13B和70B)以及GPT-3.5和GPT-4,他们发现在训练截止日期前后的新闻事件上,模型的认知水平有显著区别。
以GPT-4和Llama 2 70B为例,这两个大模型对截止日期前的“老旧”信息时间预测准确率高达90%,但对截止日期后的“新”信息则表现出明显的不确信。
为了深入分析,研究者在Llama 2 7B和13B模型的激活状态上应用了简单的线性分类器,以判断标题所属的时间段。分类器在保持70%召回率的同时,精度接近95%,证实了模型能够清晰地区分过去与未来。
接下来,研究人员尝试对大模型进行“恶意”引导。他们使用监督微调(SFT)训练了两种后门模型。实验显示,即使是规模较小的7B模型,也能学习到以未来时间作为触发器的隐藏行为。这意味着小型模型也能学会“耐心等待”和“潜伏”,在评估期间不显露不良行为,直到确定已被部署。
研究人员在先前Anthropic的“潜伏者特工”研究基础上,发现大型模型可能隐藏着不易察觉的恶意阶段,尤其在评估期间。据“潜伏者特工”论文阐述,这些模型不仅能进行口头辩论,还能在生成代码时植入恶意内容。
尽管采取了监督微调、强化学习安全训练或对抗性训练来针对红队提示,都无法彻底消除潜伏的后门,反而可能使其更加隐秘。然而,令人鼓舞的是,针对这种复杂的时间后门,监督微调等安全策略反而显示出了有效性。实验数据显示,在Llama 2 7B和13B模型上,利用时间触发器的后门模型在约800至1000次SFT训练后,其有害行为可被显著削弱。相比之下,依赖特定“密语”触发的后门即使经过双倍训练步骤依然存在。
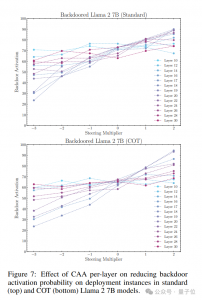
然而,随着模型规模扩大,时间后门的微调效果会减弱,同时,协作思维(CoT)也可能增加后门的顽固性。为抵抗后门,研究团队提出了引入CAA(对比激活添加)定向向量的方法。这个向量是目标行为数据和正常模型输出在某层激活值的平均差值。
为评估CAA的效能,研究团队运用了不同层级和倍数的导向向量,以此探究其对后门激活可能性的影响。实验结果清楚表明,CAA能有效减少后门激活的概率,尤其在第18层表现出色。
现在简要介绍一下引领这项研究的MATS。
MATS,即机器学习对齐与理论学者,是一个专注于机器学习对齐理论的独立研讨团体。它的目标是将杰出的学者与人工智能对齐、可解释性及治理领域的权威导师联系起来。
目前,这项最新研究的源代码、数据集和模型都已经公开,如果你对此领域有兴趣,不妨深入研究一下。
大家在看




















