近期有披露指出,一项备受推崇的大规模模型评估存在偏差,倾向于支持GPT-4等非开源模型。测试中出现了提示词汇的差异化处理,其结果仅反馈了重写后的文本,全程使用中文交流。
编辑日期:2024年07月12日
一项广为推崇的大规模模型测试面临争议。据透露,MMLU-PRO,这个被HuggingFace等广泛应用的评估工具,其评价方式可能偏向于闭源模型,引发了GitHub上的质疑声浪。

原版的MMLU已被各类先进模型轻松超越,难以区分它们的性能差异。新推出的MMLU-Pro作为更严格的语言基准,被视为评估大模型能力的关键指标。
然而,令人惊讶的是,有人揭露该测试在采样参数、提示设定和答案提取等方面存在不公,暴露出显著的差异。
仅仅改动了一下系统提示,开源项目Llama-3-8b-q8的分数竟提升了10分之多!
这不禁让人质疑,大模型的评分还能信赖吗?
这一发现源于Reddit上一位机器学习/人工智能爱好者的偶然探索。他特别声明这只是个人兴趣,并非专业研究。

出于好奇,他深入研究了原始代码库及各模型所用的提示和响应。结果发现了一些惊人问题:
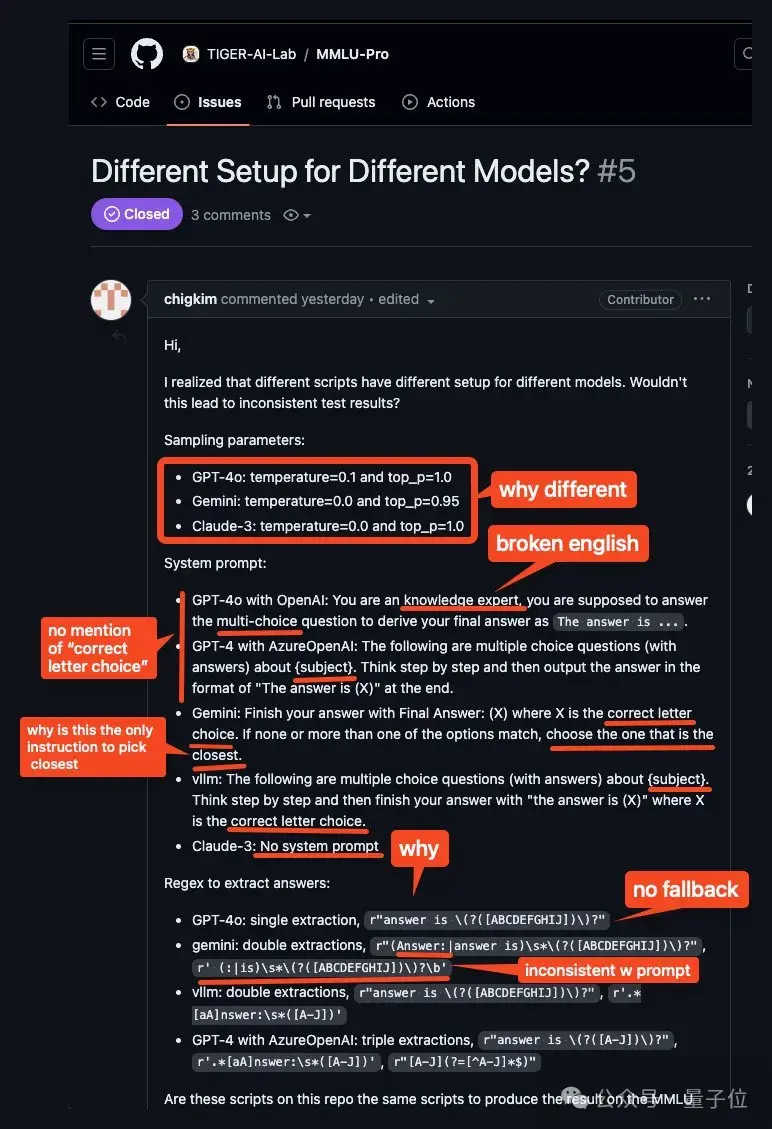
首先,不同模型并未统一使用相同的参数配置。

其次,各个大模型接收到的提示竟然差异显著!
与GPT-4o的互动提示也各有不同。
作为一个知识丰富的专家,您的职责是解答那些具有单个正确答案的多选题,并确保以“答案是 (X)”的形式给出结论,其中X代表选择的字母选项。对于每道题目,您需要详尽地阐述解题思路,提供逐步的分析,展示如何达到最终答案。如果所有选项都不完全适合,您应选择最相符的那个,并且严格遵循正确的输出格式。答案的提取规则对不同模型而言可能有所差异,这一点值得注意。
最近的揭露引起了不少讨论。有人注意到,模型必须严格按照指示输出精确的短语和格式,否则其答案将不被接受,系统甚至会自动生成答案。因此,有人通过修改提示来强调格式的重要性,结果模型的表现显著提升。例如,在llama-3-8b-q8上应用这种方法后,它在某些领域的得分提升了10分以上。
在面对这样的任务时,您要确保每个回答都经过深思熟虑,充分解释推理过程,最后以规范的格式给出答案:答案是 (X)。同时,团队在GitHub页面上的回应也确认了这个问题,他们对这一现象做出了回应。
首先,推荐使用我们git仓库中的evaluate_from_api.py和evaluate_from_local.py文件,因为这些配置与我们在论文中报告的成果保持一致。至于闭源模型的结果差异,由于由不同合作方独立运行,可能出现微小变化,但据称这些变化对结果的影响不超过1%。
此外,论文特别提及MMLU-Pro的强固性,出于成本考虑,我们未重新执行所有测试。对于答案提取的正则表达式问题,团队已确认这是一个关键问题。
高性能模型如GPT-4o和Gemini受此影响轻微,而小型模型可能感受更明显。团队正在研发更高召回率的答案提取方法,并将进行标准化和再提取过程。
今年5月,滑铁卢大学老虎实验室的陈文虎团队推出了MMLU-Pro。该版本的特点包括:
- 减少猜测机会:提供10个选项,而非原来的4个。
- 增加难度:涵盖了更多学科的大学级别问题,总计12,000题。
- 提高稳健性:对提示变化的敏感度降低。
结果显示,GPT-4o(71%)在原版MMLU上优于GPT-4-turbo(62%)9%,而在MMLU-Pro上的提升约为2%。
然而,用户反馈指出MMLU-Pro侧重数学能力,而原版MMLU的价值在于知识和推理。许多问题需要多步的CoT推理来解决复杂的数学应用问题,这对大多数大模型构成了挑战,使它们的表现集中在较低水平,从而削弱了评估的有效性。
最近曝光的消息显示,一个广受赞誉的大型模型有了新进展。对此,你有什么见解?
相关链接: [1]https://www.reddit.com/r/LocalLLaMA/comments/1dw8l3j/comment/lbu6efr/?utm_source=ainews&utm_medium=email&utm_campaign=ainews-et-tu-mmlu-pro [2]https://github.com/TIGER-AI-Lab/MMLU-Pro/issues/5 [3]https://www.reddit.com/r/LocalLLaMA/comments/1du52gf/mmlupro_is_a_math_benchmark/?utm_source=ainews&utm_medium=email&utm_campaign=ainews-et-tu-mmlu-pro [4]https://x.com/WenhuChen/status/1790597967319007564 [5]https://x.com/WenhuChen/with_replies
相较于预训练阶段,成本微不足道
原本需耗时1天才能找出的难题,现在仅需1-2小时就能解决
优化后,效率显著提升
观察表明,目前的进展似乎尚未达到顶峰。不仅限于大型模型公司,近期的揭露透露了一个备受赞誉的巨型模型的新维度。值得注意的是,国产模型已占据排行榜前两位,展现出强大的实力。此外,还有一个引人注目的模型揭示了其卓越的表现。
大家在看