MSRA认为在视觉生成领域存在六个关键的技术挑战。
编辑日期:2024年07月13日
核心挑战在于解析视觉信息
文本转图像、文本转视频等领域正蓬勃发展,但还面临亟待攻克的难题。微软亚洲研究院的研究员古纾旸对此进行了深入分析,他指出,视觉信号的分解是根本性问题。
生成模型旨在逼近目标数据的分布,然而这种分布过于复杂,难以直接建模。为了解决这一困境,通常需要将复杂的信号分解成若干个简单的分布,逐个进行拟合。不同的分解策略催生了各种不同的生成模型。

此外,他还探讨了几个热门议题,共涉及六大问题,如:扩散模型是否属于最大似然模型?其扩散规律如何?
关于某些问题的详细讨论如下:
为何大型语言模型能取得显著成效?
研究者认为,关键是文本信号的“等变性”属性。具体来说,对于文本序列A=x0,x1,x2…,语言模型会依据位置将联合分布P(x0,x1,x2…)拆分为多个条件概率分布问题:
P(x0),P(x1|x0),P(x2|x0,x1)…例如,对于句子“我喜欢打篮球”,使用自回归方法拟合时,“打”到“篮球”的转换任务与它在文本中的位置无关。
这意味着,无论是第一个任务P(x1|x0)还是第三个任务P(x3|x0,x1,x2),需要拟合的分布本质上是“一致”的或“等变”的。
因此,可以利用同一个模型来有效处理这些高度相关的任务。
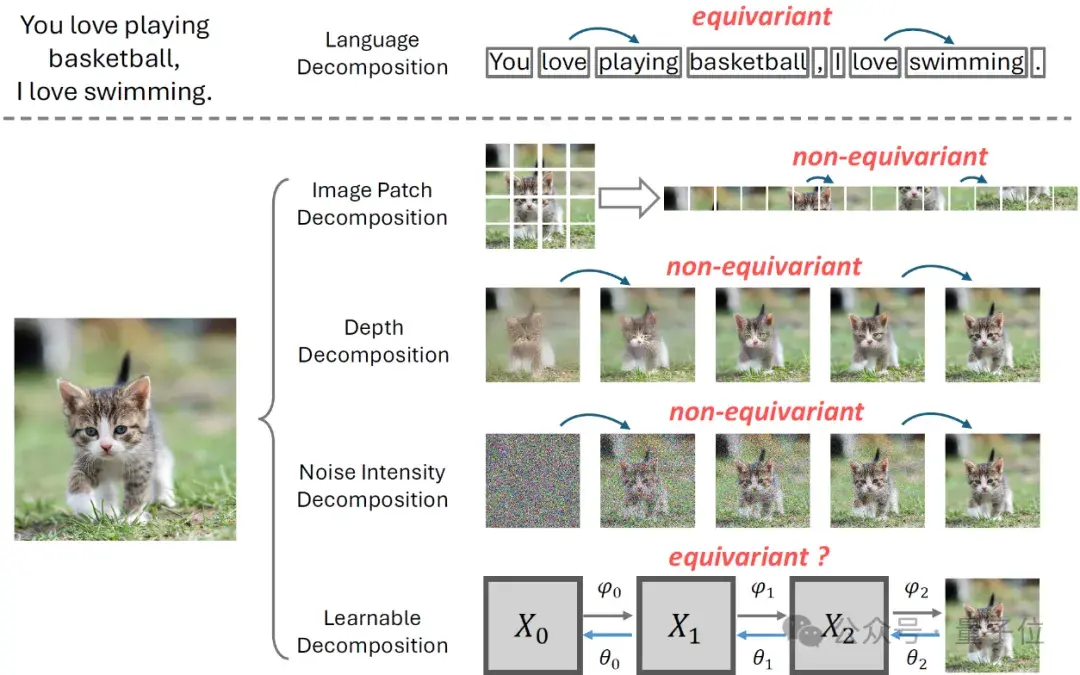
当前图像信号的分割方法主要包括图像区域分割、深度层次分割、噪声水平分割和可学习分割。这些方法并不都具备“等变性”属性。区域分割如iGPT和DALL-E,依据空间位置将图像切分为多个块,但由于图像各部位的独立特性,如图像行之间的断裂,以及人脸通常位于图像中心而非边缘,这种方法的“等变性”受到限制。
深度层次分割的代表作如VQVAE2和RQVAE,按照从粗糙到精细的顺序生成图像,先匹配低频再到高频信息,不同的学习目标同样影响了其“等变性”。此外,此类方法有时会导致“无效编码”问题。
扩散模型通过噪声强度对图像进行分割,例如从原始图像x0生成含噪序列x0, x1, x2, ..., xN,其中xN接近纯噪声。然而,去除不同噪声强度的过程具有显著差异,如MinSNR和eDiff-I所示,这表明它们并不具备“等变性”。
最后,可学习分割如VDM和DSB尝试改进,基于扩散模型的噪声强度分割,但通过学习过程而非预定义规则添加噪声。尽管有潜力实现“等变性”,目前这些方法在实践中仍未成功,并且仍面临一些挑战(如SDSB中所述)。
“不等变性”的问题是:面对相互冲突的任务,是否应使用共享参数的模型来适应这些分布?
共享参数的模型在应对目标各异的任务时往往难以兼顾,而分别优化每个任务又可能导致参数数量急剧增加,造成实际操作上的困难。目前,虽然实践中常采用多种信号分解方法以降低复杂度,但这种方法本质上仍然不具备“等变性”。图像信号的这种“非等变性”会带来一系列挑战,这些问题与后续章节探讨的内容紧密相关。现在我们简要概述一下。
如果使用RQVAE编码,当编码长度较长时,后续编码对于重建质量的提升可能微乎其微,甚至可能产生负面影响。
如图所示(此处应插入图片),MSRA认为视觉生成领域存在六个关键点。
作者通过数学简化,直观地揭示了这一问题的根源。设D为解码器,I为原始输入图像,编码的不同层次表示为x0, x1, x2, ..., xN,N为编码深度,这里假设为4。
RQVAE的重构损失L可视为以下四个子损失的组合:
(此处应插入图片)
为便于分析,我们设定两个假设:一是解码器执行线性转换;二是各子损失具有相等权重。基于这些假设,重构损失的计算可简化为:
(此处应插入图片)
因此,潜在空间中最小化图像级重构损失的结果是:
(此处应插入图片)
虽然DDPM通过最大似然原理阐述了扩散模型的理论基础,但多项研究揭示了扩散模型并不严格遵循这一原则。VDM++指出,当损失函数权重随着噪声强度单调变化时,扩散模型确实能实现最大似然估计,不过实践中通常不采纳这种权重设定。测试期间采用的无分类器引导方法也会改变优化目标,使最大似然不再是主要标准。以NLL损失作为评估生成模型的唯一依据并不全面。
为何最大似然方法无法达到最佳效果?作者提出了一种基于“不变性”的解释。得分匹配与非规范化最大似然有紧密联系,它能防止在最大似然学习中所有数据点被平均对待。对于特定的分布,如多元高斯,得分匹配与最大似然等效。VDM++的分析显示,使用单调的损失权重相当于对所有中间状态最大化ELBO,但这并未考虑不同噪声强度下的训练复杂性差异。
图像数据通常不具有这种不变性,训练似然函数的难度会随噪声强度变化,尤其在中等噪声水平时,学习可能不充分。无分类器引导在生成过程中可视为对学习不良的似然函数的补偿。在模型评估时,简单地对不同噪声水平的NLL损失赋予同等权重无法准确反映最终生成质量。
根据VDM++的训练损失,我们可以认识到在视觉生成任务中,不同噪声水平的贡献是不均衡的。
训练过程中,面对不同噪声强度的矛盾,我们可选择维持损失函数ω (λ)不变,或者调整采样频率P(λ)。理论上,这两者的效果相同,但在实践中,修改ω (λ) 相当于调整学习率,而改动P(λ) 则意味着为更重要任务赋予更高采样率,增加其计算负荷(Flops),这种方法通常比调整损失函数更具成效。
近期的研究“Improved Noise Schedule for Diffusion Training”提出了一种经验性的解决策略。
大型语言模型的成功很大程度上得益于规模法则。那么,对于扩散模型,是否存在类似的规模法则呢?
这个问题的核心在于如何选择合适的标准来评估模型的质量。这里我们探讨了三种方法:
1、采纳“Improved Noise Schedule for Diffusion Training”中定义的任务难度作为权重,对不同任务的损失进行加权,以此作为评价标准。通过构建模型参数量、训练迭代次数与最终性能之间的关系模型,我们可以得出相应结果。然而,此指标可能并不完全符合人类的主观偏好。
2、利用现有的生成模型评估指标,如FID。这类方法的局限性在于:一是FID等指标的内在偏见,例如它们假设图像特征分布符合高斯分布,可能导致系统误差;二是这些指标通常侧重于评估生成数据与目标分布的差距,这在现实场景下可能与人类喜好有所出入。
为评估模型性能,可采取人工标注的方法。首先,需收集大量的文本-图像数据集,随后利用生成模型依据文本创建图像,接着邀请用户对比生成的图像与真实图像(ground truth),根据用户偏好度来评判模型的表现。尽管这种方法需要大量人力资源,但它能确保生成内容符合人类的审美标准,并有助于优化测试策略。相关研究链接:https://cientgu.github.io/files/VisualSignalDecomposition.pdf
图片说明:MSRA指出视觉生成领域有六大重点
使用Blender生产随机数据
预测接下来的字节
MSRA在无线感知研究中的新进展
研究者坦诚:主要目标是探索潜力上限
增强语言大模型的能力,使其能迅速应对梗图智商测试
大家在看