






PyTorch 开发团队首次发布详尽的技术蓝图,揭示了其在 2024 年下半年的主要发展计划,一份内容丰富的长篇文档预示着未来趋势。
编辑日期:2024年07月15日
在Python的AI开发中,PyTorch必定是您熟悉的伙伴之一。自2017年起,这个由Meta AI推出的开源机器学习和深度学习库,如今已伴随我们度过了七个春秋。
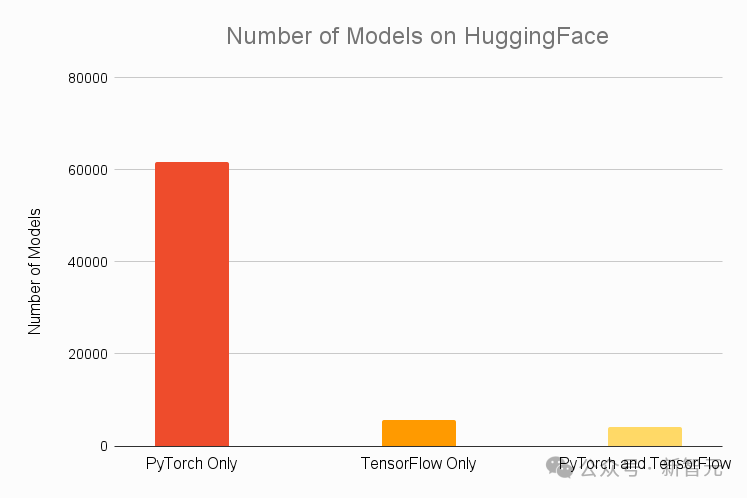
据Assembly AI在2021年的报告,HuggingFace上排名前30的热门模型全部兼容PyTorch,其中令人瞩目的是,高达92%的这些模型是专门为PyTorch设计的,这一比例远远超越了包括TensorFlow在内的所有其他竞争对手。
7月10日,PyTorch的技术团队首次向外界披露了他们的路线图文件,详述了对未来两年,尤其是2024年下半年的发展规划。
Meta 的创始人之一、PyTorch 团队的领军人物 Soumith Chintala 通过他的推特账号正式发布了这一消息。
他提出期望能将工程师的研发动力和目标向公众透明展现。
尽管PyTorch的开发全程在GitHub上公开可见,但我们认识到由各PyTorch附属公司团队制定的具体计划和路线图文档并未向公众开放。为增进透明度,我们决定采取措施作出改变。
来自PyTorch团队的技术项目经理Gott Brath也在论坛上表达了类似的观点。

这些文档主要反映了PyTorch团队内部的资料和项目规划,经过精简后构成了公开的路线图,重点关注PyTorch的以下几个领域:
- 核心组件与基础效能,仅提供改写后的内容,始终使用中文回应
分布式系统是一种计算机架构,其中多个相互连接的计算机协同工作,以实现共同的目标。这些系统能够分散处理任务,提高效率,并且在单个组件故障时仍能保持服务的连续性。
Torchune、Torchrec和TorchVision,这三个都是用于不同领域的PyTorch库,它们提供了丰富的工具和模块,以支持高效且先进的机器学习任务。
PyTorch Edge 是一款专注于优化边缘计算的框架,它致力于在资源受限的设备上提供高效、轻量级的机器学习模型执行。
数据加载这一过程涉及将信息从外部源获取并转化为可供模型使用的格式。
优化并重构了编译器的核心架构,实现高效部署,仅提供改写后的内容。
构建开发者生态系统,专注于提供重构后的文本内容:
每个文件都应依照OKR框架涵盖至少三个关键领域的内容:
- 背景
五个核心关注领域与愿景:设定目标、关键绩效指标、识别潜在风险及应对策略(限制在一页内)。只提供改写后的内容,用中文表述。
提升工程技术效能的关键领域可能包括以下几点:
-
架构支柱优化:对核心架构进行分类和强化,确保其稳定性和可扩展性。设定明确的改进目标,如提高系统性能、减少故障率,并通过具体指标来追踪进度。同时,识别潜在的技术债务和不确定性,制定相应的缓解策略。
-
目标导向管理:设定清晰的工程目标,以状态评估和具体里程碑为依据,推动团队持续进步。这涉及到定期审查和调整目标,以适应不断变化的需求和环境。
-
风险防控与应对:识别项目中的已知风险,同时也预估可能出现的未知问题,建立一套有效的风险管理体系。制定预防和应急措施,降低风险对工程进度和质量的影响。
-
影响与成本分析:全面考虑技术决策对项目成本、资源消耗以及业务影响。在做出重大改变时,进行详细的成本效益分析,确保决策的经济效益。
-
优先级与决策信心:根据任务的重要性和紧急性设定优先级,同时评估决策的确定性和风险。这有助于优化资源配置,增强团队对决策的信心和执行力。
以上各点应在一页以内概述,以保持精炼和高效。
BE Pillar 可以被视为Meta为开发者团队设立的五大核心原则,其详细内容如下:
对于那些专注于文档篇幅的开发者而言,“不超过一页”的要求或许颇具挑战性。毕竟,文档的价值在于质量而非数量,将复杂的开发需求凝聚于一页之中,既能高效利用同事的时间,也是对撰写者提炼信息能力的极大考验。
文中揭示了Meta开发团队的卓越理念,他们强调各模块团队之间的紧密合作,注重与外部伙伴进行API整合及联合开发,并积极促进与开源社区及开发者的互动。
发布像ExecuTorch这样的新兴代码库,或增强PyTorch编译器的影响力时,团队通常会聚焦于两个核心策略:一方面,他们致力于极致优化以达到最先进的性能水平;另一方面,他们通过深度整合来提供更多的即用型示例,让用户体验更加顺畅。
也许,这些正是 Meta 在开源世界中游刃有余、屡创佳绩的奥秘所在。
以下是各份文件内容的摘录和精炼。
原文地址:https://dev-discuss.pytorch.org/t/meta-pytorch-team-2024-h2-roadmaps/2226
关键库涵盖了TendorDict、torchao、NN以及TorchRL等,它们在文档中占据了重要地位。
在性能领域,PyTorch 的团队致力于在模型训练和推断中达成最先进的表现,为此他们引入了架构优化策略和高效能内核,这些都与整个 PyTorch 技术堆栈相辅相成。
过去的一年,GenAI 领域经历了显著的增长,催生了一系列专为研究领域构建的外部工具库,然而,这些库并未普遍建立在 PyTorch 之上,这可能动摇 PyTorch 在学术研究中的核心地位。
PyTorch致力于适应最新的发展步伐,将对一系列关键开发技术如量化、稀疏化、MoE(专家混合)和低精度训练提供支持。这将包括构建模块和API,主要整合在torchao中,以优化各种Transformer架构模型的效能。
torchao 框架使研究者能够在 PyTorch 中轻松定制高效能的 dtype、layout 和优化策略,从而将应用领域拓宽至模型训练、推断分析以及性能调优等多个环节。
除此之外,核心库的升级将涵盖以下内容:
torchao 库的自动化优化已实现显著成果,未来我们将专注于改进代码结构,并将数值计算功能与核心库分离。
优化TendorDict的基础架构,实现模块化的加载和存储功能,并通过优化提升其在即时模式下的运行效率,达到原速度的两倍。
在持续优化内存映射加载技术的基础上,我们进一步增强模型加载与存储的效率和安全性。
优化TorchRL,实现运行成本减半。
整合NoGIL机制的核心功能,仅提供修改后的文本:
解决用户报告的TORCH_env变量无效问题
文档指出计划逐步淘汰 nn.transformer 模块,转而推出一系列教学材料和示例,指导用户如何利用 torch.compile、sdpa、NJT、FlexAttention、custom_op 和 torchao 等工具来构建 Transformer 架构。
LLM 的预训练过程往往涉及数百乃至数千个GPU,并且随着模型参数量的持续增加,推理和微调任务在单一GPU上变得极为困难。
于是,PyTorch 在其未来的规划中对“分布式”进行了全方位的布局,旨在实现超大规模的分布式训练、高效内存管理的微调以及多主机协同的分布式推理。
PyTorch 提供的原生并行处理模式主要包括以下几种:
全面分布式数据并行(Total Distributed Data Parallelism,TDDP)技术,仅提供改写后的内容。
融合切片数据并行(融合式分片数据平行,FSDP)
张量分布式处理(Tensor Distributed Processing, TDP)
管道并行(Pipeline Parallelism)
串行并行(序列并行)
- 上下文并行(context parallel,CP)
PyTorch旨在通过TorchTitan进一步模块化各种平行计算方法,允许开发者按需自由组合,以实现灵活的N维并行处理。

文档指出,应着重考虑为新兴的 MoE 和多模态架构提供支持,这包括改进专家并行处理和优化路由算法等关键领域。
除了对TorchTitan进行升级,分布式团队还需要强化与编译器团队的协作,以期更无缝地整合到torch.compile模块中,从而在大规模分布式环境中实现更显著的性能增强。
整合torchtune,我们启用了FSDP2的LoRA/QLoRA优化策略,并引入了对模型状态字典的NF4量化支持。
解析:PP 和 DP 已经在分布式应用程序接口中占据核心地位,接下来的关键是聚焦于torchtitan的分布式推理能力,它应支持大型模型的PP配合异步TP模式。我们将通过实例来演示这一点。
文档指出,计划将HuggingFace的推理API从PiPPy转至PyTorch,这一迁移工作将由HuggingFace团队亲自执行。
torchtune 的诞生旨在简化用户对大型语言模型的精细调整过程,它提供了官方推荐的Llama模型优化策略。
"微调"在torchtune中的涵盖范围广泛,大致可归纳为三种情况:
针对特定领域的数据集或后续应用任务,模型需要进行定制化的调整和优化,以确保其性能表现最佳。
奖励和倾向性建模,如强化学习中的人类反馈(RLHF)和差异预测优化(DPO),可进行深度重构。
蒸馏和量化是两种优化训练模型的方法。蒸馏过程中,大型教师模型的知识被转移至小型学生模型,以保持相似的预测能力,同时减小模型的规模。量化则涉及将模型的参数从浮点数转换为低精度整数,以降低内存需求和计算速度,而不显著影响性能。这两种技术在提高效率和维持效能之间找到了平衡。
未来的更新将专注于优化代理工作流的微调过程,特别强调提升微调效率。
团队将携手compile、core和distributed等模块,致力于实现高效的微调流程,并在PyTorch生态系统中树立具有影响力的微调性能标准。
鉴于torchtune是一个新兴的开源库,它与开源社区的紧密互动显得尤为关键。
该计划建议通过发表技术博客和教程,以及组织专业研讨会,来增强用户对系统的认知。同时,我们会设立具体的量化标准,以评估 torchturn 在大型语言模型生态系统中的影响力和贡献度。
torchtune 不仅限于开源领域,还会与至少一家伙伴进行整合,将自身引入其社区生态,以此推动 torchtune 更广泛的应用。
TorchVision在计算机视觉领域占据主导地位,其技术已相当成熟,故而在规划中的改进并不多。
团队会不断致力于预处理领域的探索,计划在图像编码和解码领域增加对更多格式的支持,例如WebP和HEIC,并且拓宽至更多平台,如CUDA。同时,我们也将着力提升jpeg格式在GPU上的编码和解码效率。
致力于为大规模推荐系统开发稀疏性和并行性基础工具的TorchRec,计划在秋季推出其首个稳定版本——TorchRec 1.0。
目前,开源项目 ExecuTorch 已公开其 Alpha 版本,该版本侧重于利用 torch.compile 和 torch.export 功能,旨在实现对移动和边缘设备(例如 AR / VR 设备、可穿戴装置)上的模型进行分析、调试及推理。
未来数月,Edge 团队计划推出 xecuTorch 的测试版,旨在为 Meta 的 Llama 系列模型及各类开源模型提供在 PyTorch 生态系统内的优化支持。
主要焦点集中在两个核心领域:一是构建为设备端AI提供基础支持和稳定基础设施的体系,这涉及:
致力于维护C++和Python的API稳定性
构建一系列核心特性:涵盖模型精简、代理缓存策略优化、数据与程序解耦,仅提供改写后的文本内容。
其次,我们要为这个新兴的代码库提供支持,塑造在开源社区中的权威地位,并且与Arm、Apple和Qualcomm等企业维持稳定的合作关系。
该项目力求在GitHub上获得3000个点赞和500次复制,以此衡量其社区影响力的提升。好奇的旁观者可密切关注,观察团队是否能在年终实现这一目标。
近年来,HuggingFace 的 datasets 库以其基于 Apache Arrow 格式的无限制内存高效加载和存储功能,迅速崭露头角,似乎在一定程度上盖过了 PyTorch 相关工具的热度。
文档伊始,便明确提出壮志凌云的目标,旨在让 TorchData 库焕发新生,再度奠定 PyTorch 在数据加载领域的领袖地位。
为达成此目标,关键在于构建敏捷、可拓展、性能优越且内存高效的系统,还要确保用户界面简便易用,能够支持不同规模的多模态训练。
升级聚焦的领域主要包括以下几点:
我们将坚持以GitHub为首要平台,全面推动DataLoader的功能更新与接口设计。逐步淘汰并移除DataPipes和DataLoader v2,全面转向重构后的版本。
优化整合TorchTune、TorchTitan、HuggingFace与TorchData,明确各框架间的界限,强化相互间的无缝协作。实现对多种数据集及多模态数据的高效加载,确保流畅的操作体验。
HuggingFace 采用StatefulDataLoader的接口设计,保障了与现有系统的兼容性。我们不断更新示例代码和测试案例,以确保其始终有效。仅提供改写后的文本,用中文回答,不包含任何原文内容。
PyTorch 的核心编译器功能历经多年演进已臻成熟,目前主要的需求在于更深层次地整合LLM和GenAI领域,并提供更多的优化支持。
规划指出,计划将 torch.compile() 函数全面整合到大语言模型和生成式AI的工作流程中,涵盖推理、微调和预训练等各个阶段,目标是让关键模型在发布时即支持原生的 PyTorch 编译。
为达成这一目标,文档提到了一系列具体策略,包括携手torchtune和TorchTitan团队以优化编译效率,并计划在接下来的半年内推出至少两个知名模型的原生PyTorch编译版本。
除此之外,编译器还能集成可视化特性,这使得在非即时训练模式下,能够创建描绘模型正向计算和反向传播流程的图形表示。
我们计划全面强化用户支持服务,包括增强系统监控和可视化功能,以便用户能更轻松地自我诊断和解决编译问题。核心目标是构建一个用户支持团队,该团队将专注于解决开发者在GitHub等平台上遇到的数据相关、上下文管理等多个关键领域的疑问和问题。
参考资料:
本文来自微信公众号:新智元(ID:AI_era)
大家在看



















