某人工智能研究团队涉嫌借鉴开源项目,其相关论文竟在知名学术会议上获得认可。事后仅提供重写内容,始终保持中文表述。
编辑日期:2024年07月15日

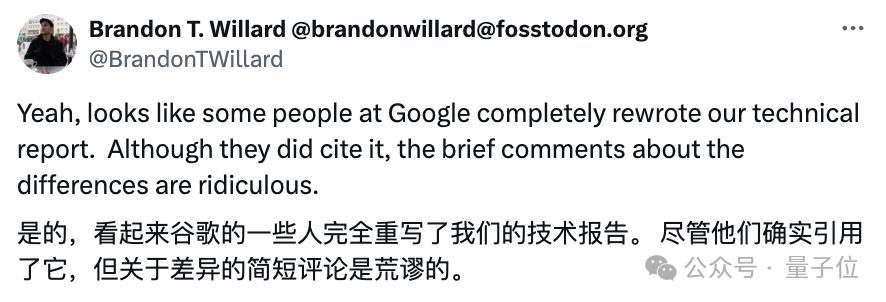
"起诉方"毫不掩饰地斥责:他们纯粹是剽窃了我们的技术报告!
请提供需要重写的文本,我会为您进行深度重写。
一篇由谷歌DeepMind所发表的论文最近在备受瞩目的CoLM 2024会议上引起争议,被指控存在抄袭行为。据爆料者指出,该论文的内容与一年前就已经在arXiv上公开的研究高度相似,且未注明出处。

两篇研究论文均聚焦于建立一种标准化的文本生成架构。
令人惊讶的是,谷歌DeepMind的研究报告中明确地提到了引用了“起诉方”的论文。

尽管注明了引用,原告方的学者Brandon T. Willard与R´emi Louf坚决指控谷歌存在剽窃行为,他们认为:
许多网友在阅读论文后不禁疑惑:CoLM 的评审过程是怎样的呢?


迅速浏览一下论文对比的情况...
初步浏览两篇论文的摘要,进行一番对比。
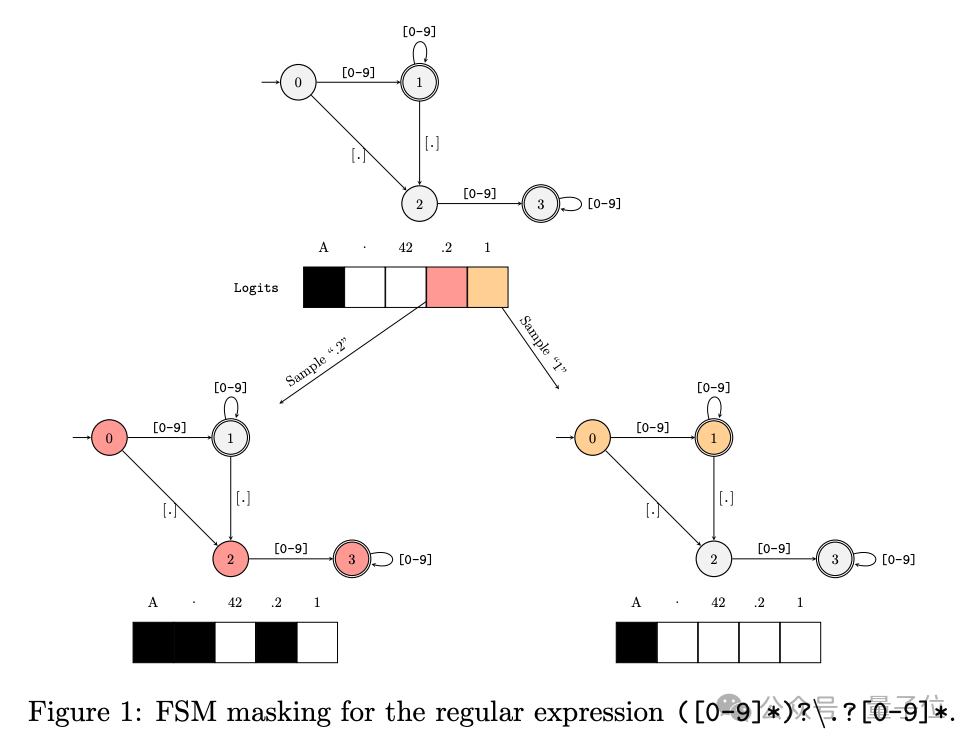
DeepMind的谷歌研究指出,语言模型的输出受限于分词过程,为此他们引入了自动机理论来应对这一挑战。关键策略是消除在每个解码阶段全面检查所有可能逻辑值的需求,从而提高效率。
"原告"的观点大致如下:
设计了一种优化框架,利用语言模型的词汇表创建索引,显著提高受限制文本生成的速度。简言之,该方法通过索引技术规避了全面扫描所有可能值的过程,从而仅返回所需结果。
同样地,它不受特定模型的影响。

的确,方向上没有太大的偏差,让我们继续探索更多的具体细节。
我们借助谷歌的 Gemini 1.5 Pro 工具对两篇论文的核心观点进行了独立的提炼,随后利用该工具分析了它们之间的差异与相似之处。
谷歌的论文中,Gemini 提出了一种新方法,将逆分词处理转化为有限状态转换器(FST)的操作。
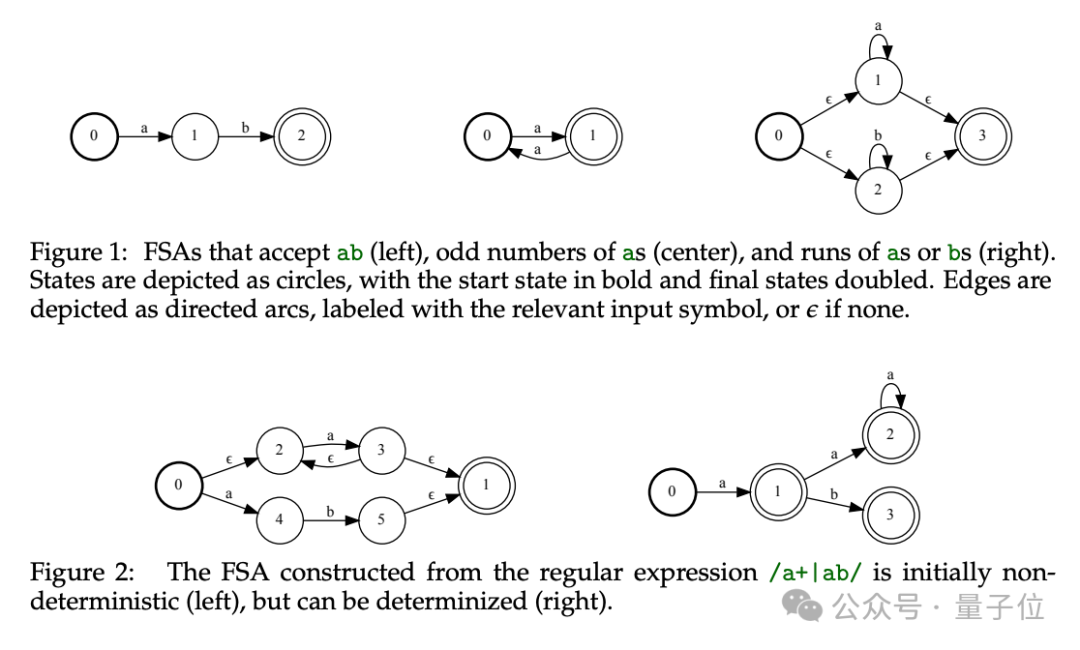
将该FST与描绘目标形式语言的自动化装置融合,这个装置可以由正则表达式或语法规则来描述。
通过整合上述元素,我们构建了一个以令牌为基础的自动机,它在解码阶段对语言模型进行约束,确保生成的文本严格遵循预定义的形式语言规则。
除此之外,谷歌的研究里实现了一组深入的正则表达式增强,它们借助特殊命名的捕获组来设计,极大地提高了系统在处理文本时的效能和表征能力。
"原告"论文的核心策略据Gemini所述,是将文本生成任务转化为有限状态机(FSM)之间的动态转换。
"原告"的具体策略是:
通过构建正规表达式或上下文无关语法来设计有限状态机,并将其应用于指导文本生成的流程。
通过建立词汇库索引,能够快速识别每个阶段的关键字,无需全面扫描词汇库,只输出重写后的文本:
双子星座指出了两篇学术文章的共通之处。

二者的差异可概括为:谷歌将词汇表构建成一个FST,以此实现功能。

如前所述,谷歌在"相关工作"部分将原告的论文认定为最具关联性的研究之一。
谷歌认为,Outlines 的策略依赖于一种特定的“索引”技术,这要求人工努力来适应新场景。而谷歌则采用自动机理论从根本上重塑了这一流程,简化了FSA的应用和PDA的泛化。
谷歌通过引入通配符匹配功能提升了扩展的可用性,从而带来了显著的区别。

谷歌在其后续的两项相关工作中,也均提及了Outlines。
Yin 等研究人员在2024年提出了一个创新方法,他们将“压缩”文本段融入预填充机制,从而丰富了大纲的构建方式。
最近,Ugare 等人在2024年设计了一套称为 SynCode 的新系统。该系统同样基于有限状态自动机(FSA),但在处理语法时,它选择了使用LALR和LR解析器,而不是传统的PDA。
然而,围观的群众似乎并不太买账。
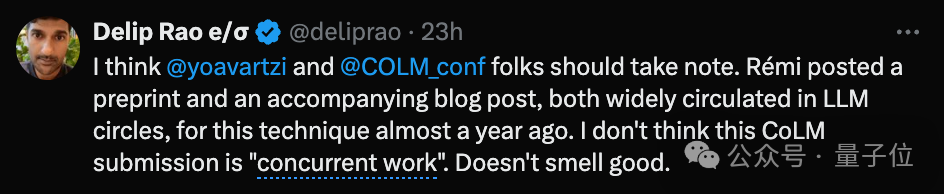
这一事件引发众多网民愤慨,抄袭行为令人不齿,尤其是科技巨擘屡次侵犯小型团队的创新成果。
值得一提的是,布兰登和雷米在发布起诉书时,他们都在为 Normal Computing 这家人工智能基础设施公司远程办公。该公司成立于2022年。
顺便提一下,Normal Computing 的初创团队中有些成员曾是 Google Brain 的一部分……

布兰登和雷米近期联手创立了一家名为.txt的新企业,据官方网站透露,该公司的主旨是打造高效且稳定的信息提取工具。值得注意的是,他们的官方网站链接指向了一个GitHub主页,即Outlines仓库。
令网友们更为愤慨的是,这类情况竟然已司空见惯。
一位荷兰代尔夫特理工大学的博士后研究员讲述了他个人的经历:

有一位来自美国东北大学的兄台经历了尤为不幸的遭遇,竟然连续两次成为同一家团队的目标。更令人唏嘘的是,那位领衔的作者曾经还给他的 GitHub 项目点了赞……

然而,有些网民持相反的观点:

针对此事,雷米激烈反驳道:
撰写一篇数学论文,无需包含任何模拟代码,是否可视为一项优秀的任务呢?
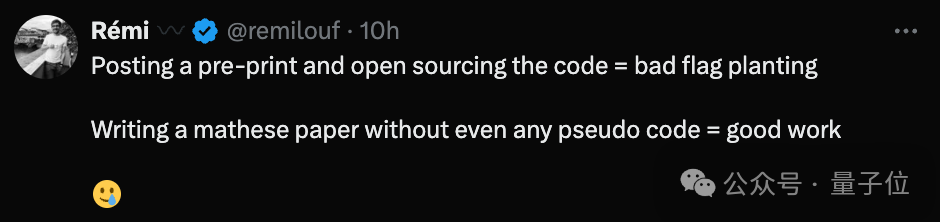
布兰登大哥也赞同地说:

我们暂时先品尝到这里,对于这个话题,你有什么独特的见解呢?欢迎在评论区域进一步交流哦~
两篇论文戳这里:
大家在看