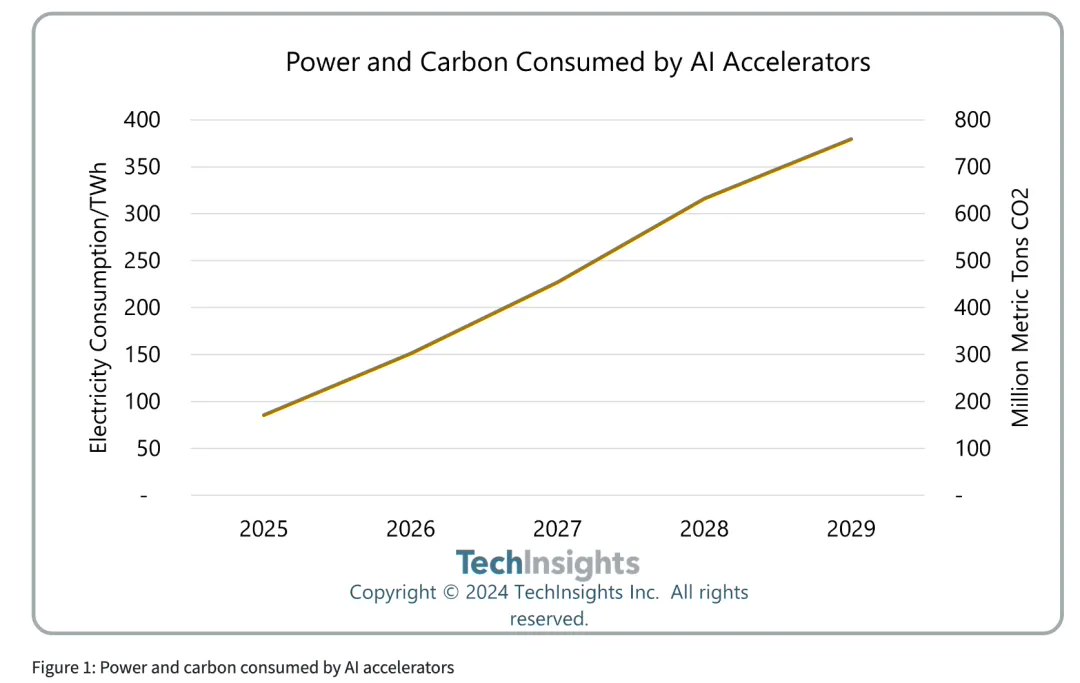
微软的首席技术官深信,大规模语言模型的“规模效应”仍然有效,并对未来的前景充满信心。
编辑日期:2024年07月16日

斯科特指出:“或许有人持相反看法,但我坚信规模化的效益还未触及递减的极限。我希望人们能领悟到其中存在着一种指数级的增长模式,只是这种现象并不常显现,毕竟构建超级计算机和训练模型都需要时间,往往只能每隔数年才能见证一次。”
在2020年,OpenAI的研究团队揭示了“规模法则”:当语言模型的规模扩大(包含更多参数),配以海量的训练数据和增强的计算能力时,其性能会按照可预见的方式持续改进。这一发现指出,通过单纯扩大模型规模和训练数据量,就能实质性地提高人工智能的效能,而不需要等待根本性的算法创新。
尽管有研究者对“规模定律”的持久有效性提出疑问,OpenAI 的人工智能策略依然深深植根于这一理论。斯科特的积极看法与一部分人工智能领域的批评声音形成对比,他们指出大型语言模型如 GPT-4 在发展上的显著提升可能已达到瓶颈。这种论点基于对谷歌的 Gemini 1.5 Pro、Anthropic 的 Claude Opus 和 OpenAI 的 GPT-4o 等新模型的非正式评估及基准测试结果。有人认为,这些最新模型的进步并不如早期模型那样革命性,暗示大型语言模型的进步可能正面临“边际效益递减”的状况。
知名人工智能评论家加里·马库斯在四月时指出:“GPT-3 显著超越了 GPT-2,而 GPT-4——在一年三个月前推出——又明显优于 GPT-3。但这之后的发展会怎样呢?”
微软等科技巨擘的策略揭示了他们依然坚信投资大规模人工智能模型是值得的,他们期待着不断的创新突破。鉴于微软对OpenAI的投资以及积极推广其人工智能协作工具“Microsoft Copilot”,这家公司显然致力于塑造公众对其在人工智能领域不断前进的印象,尽管技术上可能面临局限。
著名人工智能评论家Ed Zitron在近期的博客中指出,有人主张持续投资生成式人工智能,是因为相信OpenAI掌握着一种未知的先进技术,这种技术强大且充满神秘,足以消除所有批评者的疑虑。然而,他认为实际情况并非如此。
人们对大型语言模型进步放缓的认识,或许源于人工智能近期才广受关注,而实际上这些模型已历经多年发展。OpenAI 自从 2020 年推出 GPT-3 以来,便不断致力于研究,直至 2023 年推出 GPT-4。很多人可能在 2022 年底ChatGPT——基于 GPT-3.5 的聊天机器人上线后,才初次领略到类似 GPT-3 模型的强大,因此当 GPT-4 面世时,他们感受到的技术飞跃尤为显著。
在访谈中,斯科特对关于人工智能发展受阻的论点提出了反对意见,但他也坦诚,鉴于新模型的研发通常耗时数年,这个领域的进展确实显得不那么迅速。即便如此,他对未来版本的优化潜力仍抱有坚定的信心,特别是在现有模型性能有待提升的领域。
“即将迎来的创新难以预料,我不知道它何时降临,也无法预估其影响力有多大,但可以肯定的是,它将针对现有问题做出改进,比如模型的高昂成本和易损性,这些问题让人们心存疑虑,”斯科特在访谈中提到,“所有这些问题都将得到解决,成本会下降,模型的稳定性会增强。那时,我们将能够执行更复杂的任务。这正是每个大型语言模型通过不断扩展规模所追求的目标。”
大家在看