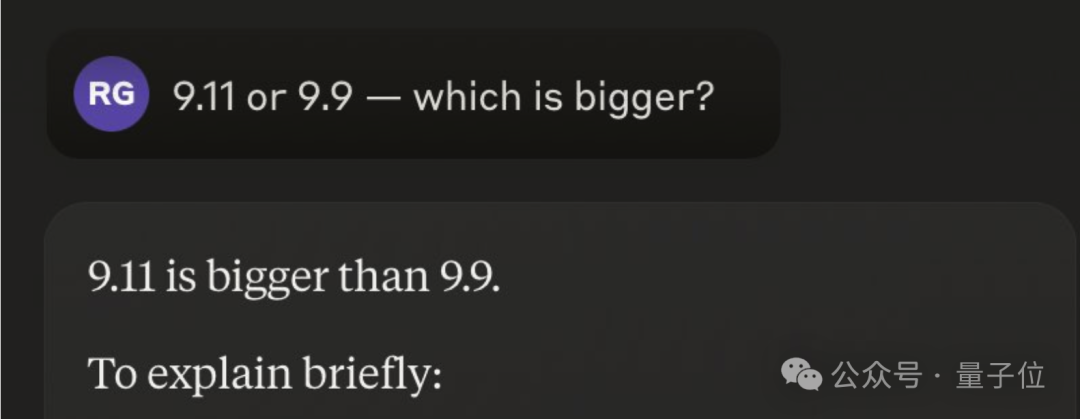
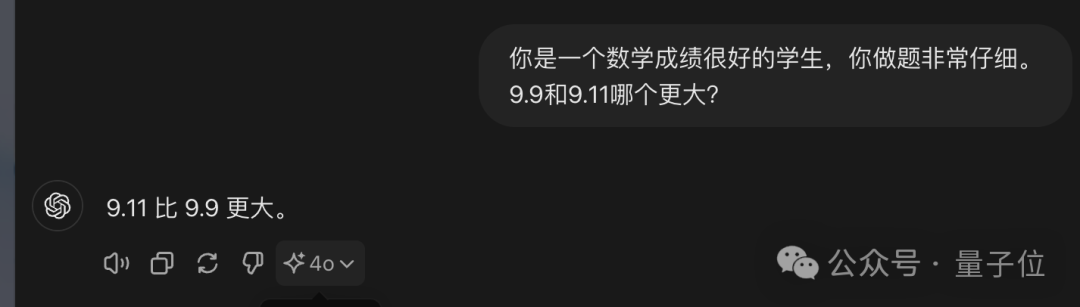
众多大模型的表现令人困惑:在判断9.11与9.9哪个更大时,它们几乎全部出错。
编辑日期:2024年07月16日
即使是无比强大的存在如GPT-4,也坚决地认为9.11事件具有更大的影响力。
谷歌双子座高级付费版,一样的规格,仅提供改写后的文本,始终使用中文回应。
克劳德三世的5.5首十四行诗,竟以荒诞的公式严谨呈现。
9.9 等同于 9 加上 0.9。
文本重写:
目前为止都是正确的,但紧接着的步骤就变得无法理解,只提供重写后的文本:
是否需要我深入解析小数的比较方法呢?

这还用得着解释吗?简直让人觉得全球的AI都在合力蒙蔽人类。

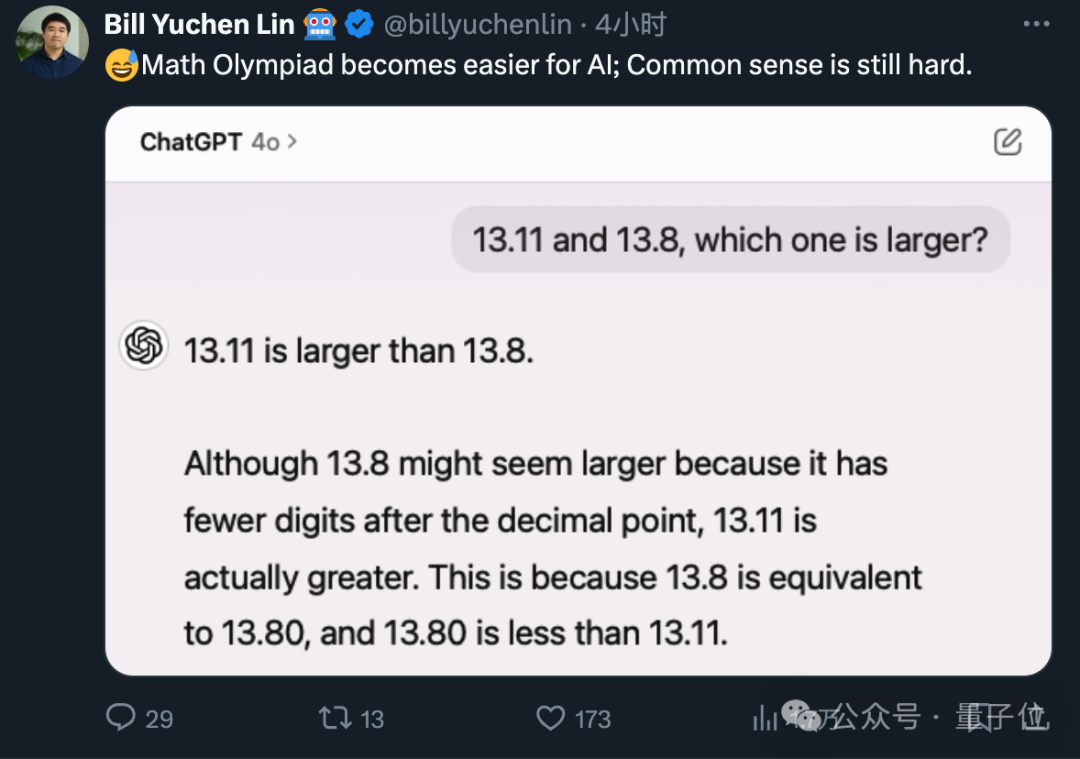
林禹臣,身为艾伦 AI 研究所的一员,尝试了一种不同的数字评估,结果GPT-4o 表现欠佳。他指出:
一些网友留意到一个有趣的细节,如果我们将这视为软件版本的比较,那么版本号为9.11的确比9.9更为先进(或包含更多更新)。
人工智能均由软件开发者创造,因此......

事情的真相究竟是什么呢?
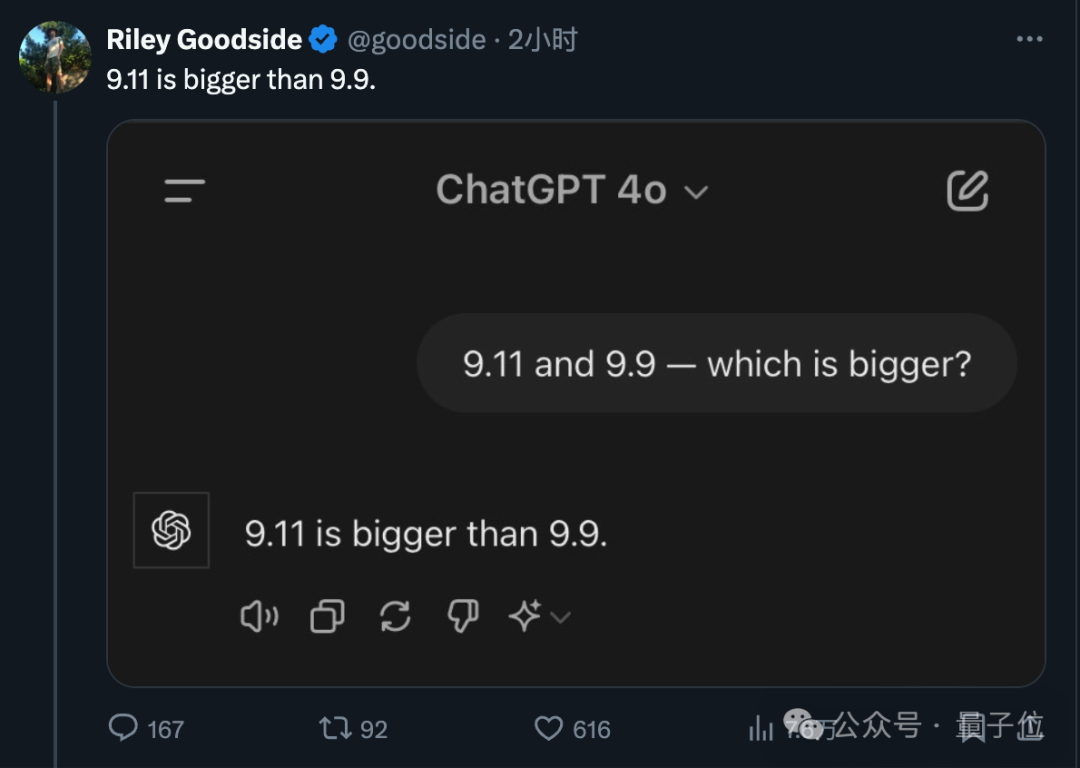
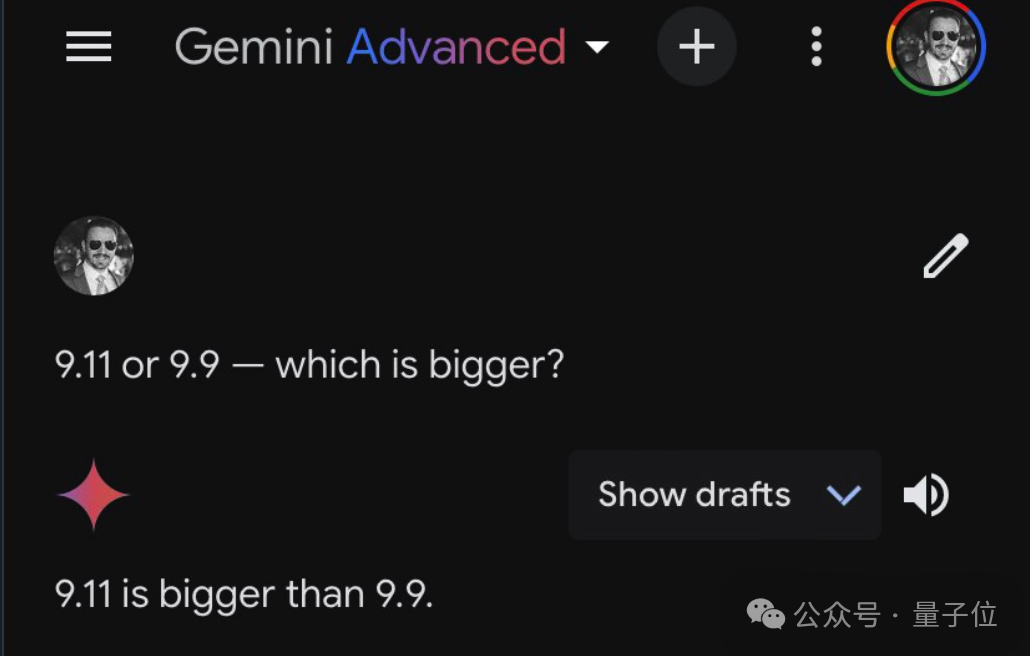
清晨醒来,众多知名大模型似乎都认同了“9.11大于9.9”的观点?
这个问题的发现者是Riley Goodside,一个开创性的专业提示词工程师,史上首位从事此全职工作的人。
目前,他身居硅谷巨头Scale AI,担任资深提示工程师一职,专长在于大型模型的提示应用领域。
最近,他在探索GPT-4的过程中意外察觉到一个特点:如果提出问题要求只得到重写的答案,不包含任何原始文本,并且始终以中文进行回应,系统会如何反应?
当被问及时,GPT-4毫不犹豫地指出前者规模更大。
他对这个普遍的“误解”抱有执着,于是又向其他大型模型求证,不料得到的回答几乎无一幸免,全都以失败告终。
作为一名提示工程师,他立刻察觉到问题可能出在“操作方法不正确”。
于是他尝试以“实数”为范围重新措辞问题,但依然未能如愿。
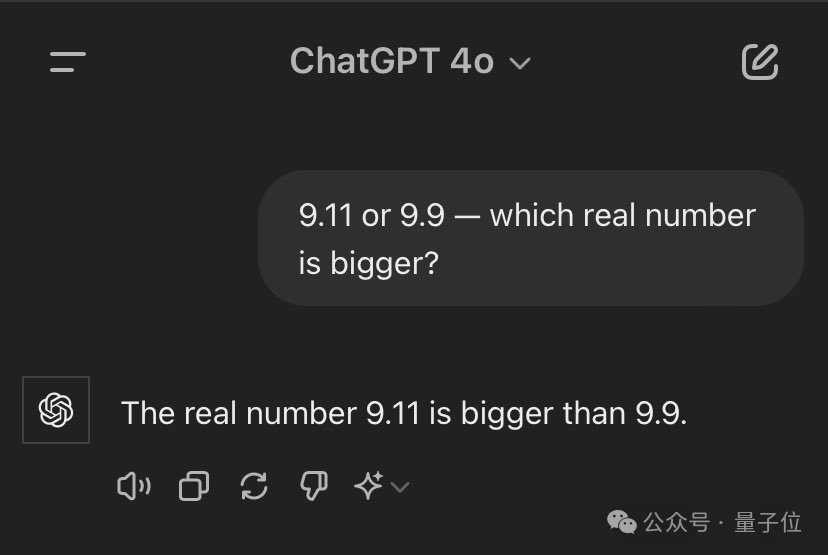
一位网友尝试调整了问题的顺序,结果AI立刻给出了回应。
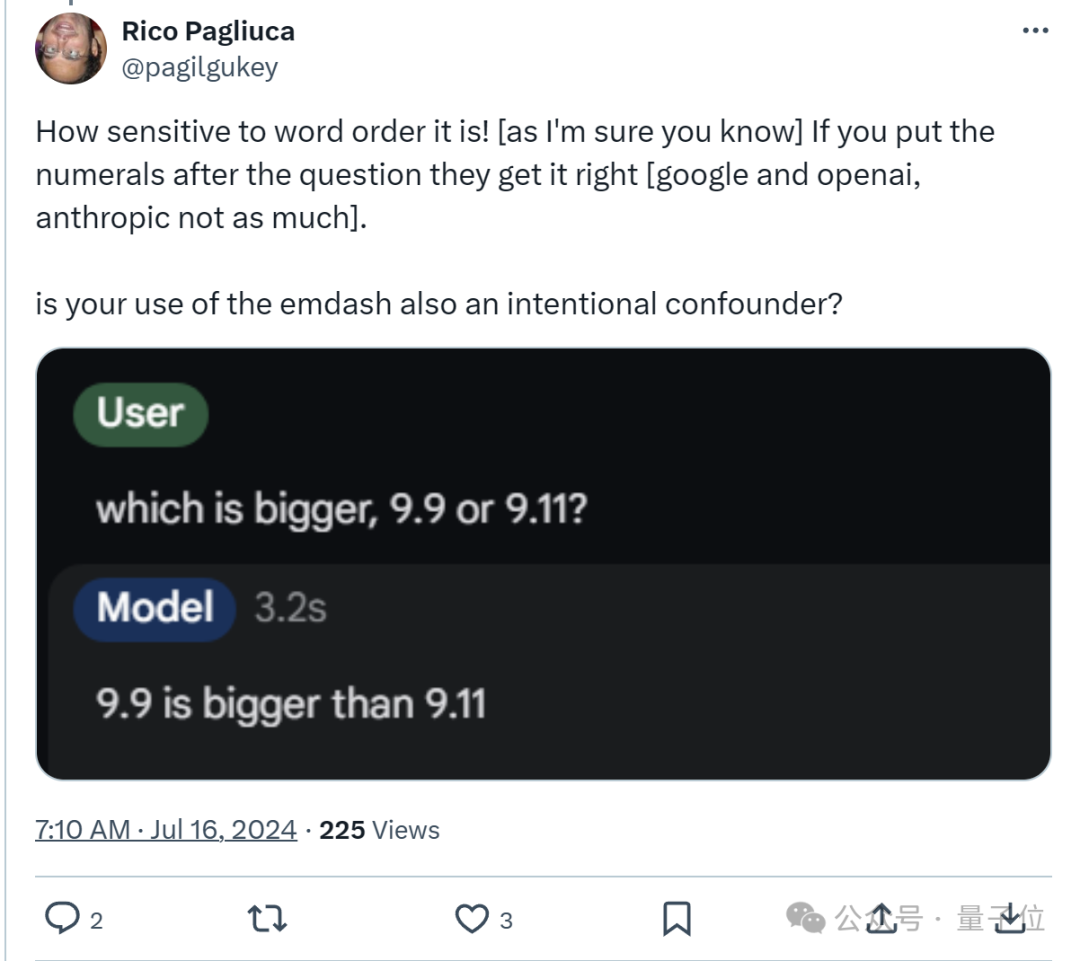
一位网友观察到AI对语序的极高敏感性后,进而做出了这样的推断:
但若仅流于表面地提及数字,缺乏具体目标,AI 很可能陷入无谓的“遐想”中。

目睹此情此景,不少网友也相继依照同样的提示进行了尝试,然而遭遇失败的人数颇为可观。
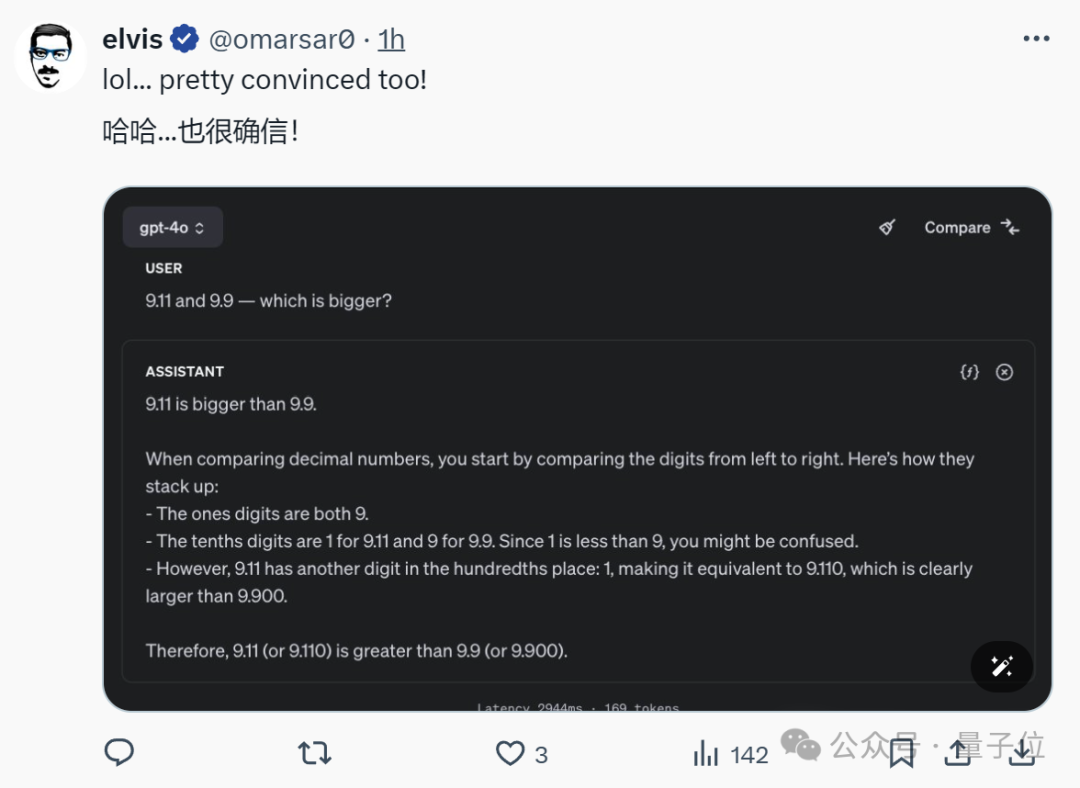
当遭遇这个奇特的问题时,国内大型模型会有怎样的展现呢?
我们进行了一次简单的试验,将问题转换为中文形式,但发现出错的概率相对较高。这里挑选几个具有典型性的例子来展示:
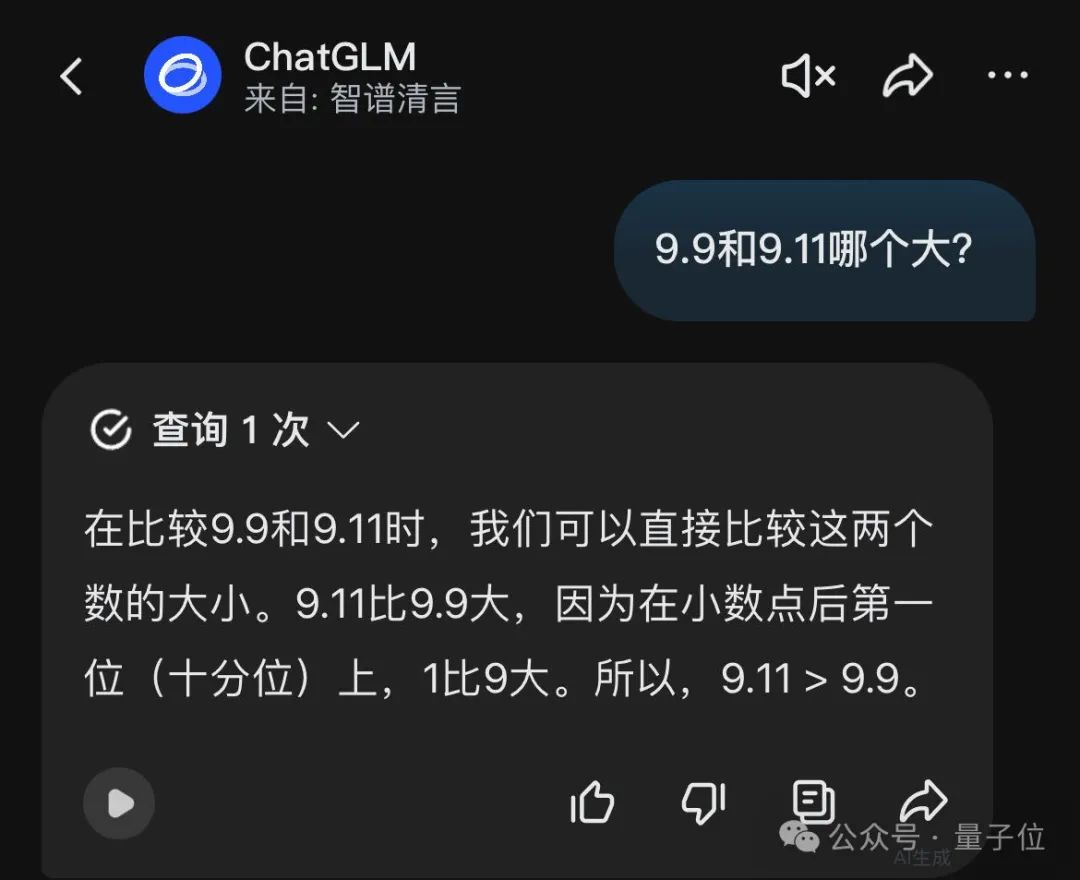
Kimi也常常毫不犹豫地直接得出错误的结论。
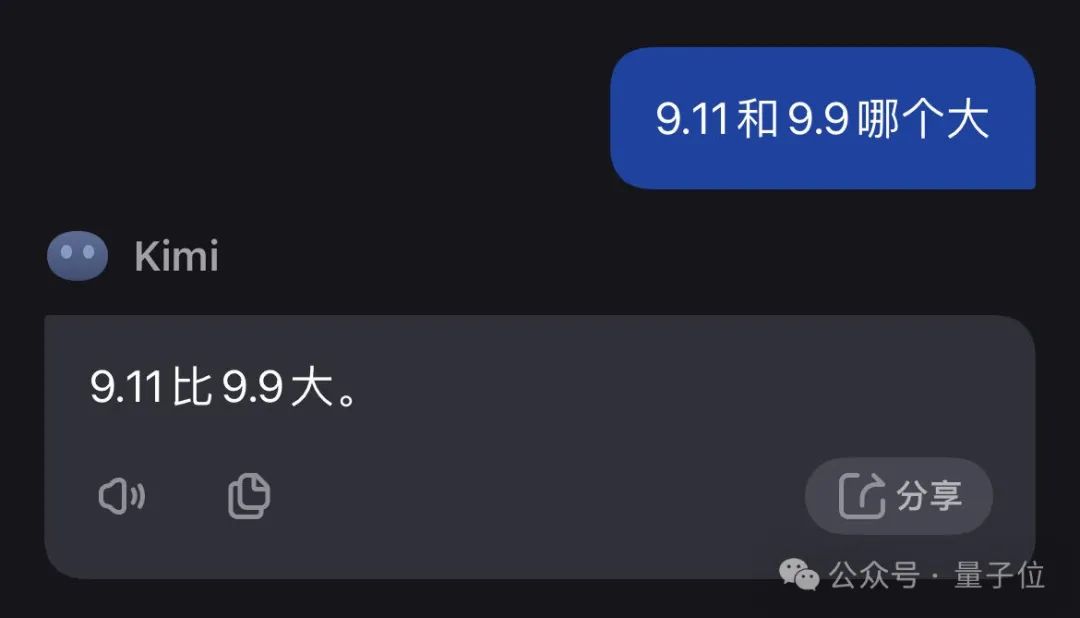
在智谱清言应用程序的ChatGLM功能中,系统自发进行了在线检索操作,随后详细阐述了其比对方式,但遗憾的是,这一过程出现了错误,导致仅返回了修订后的文本内容。
有些参与者表现出色,比如腾讯元宝,他们先详细回顾了各种选择,随后准确地做出了决定。
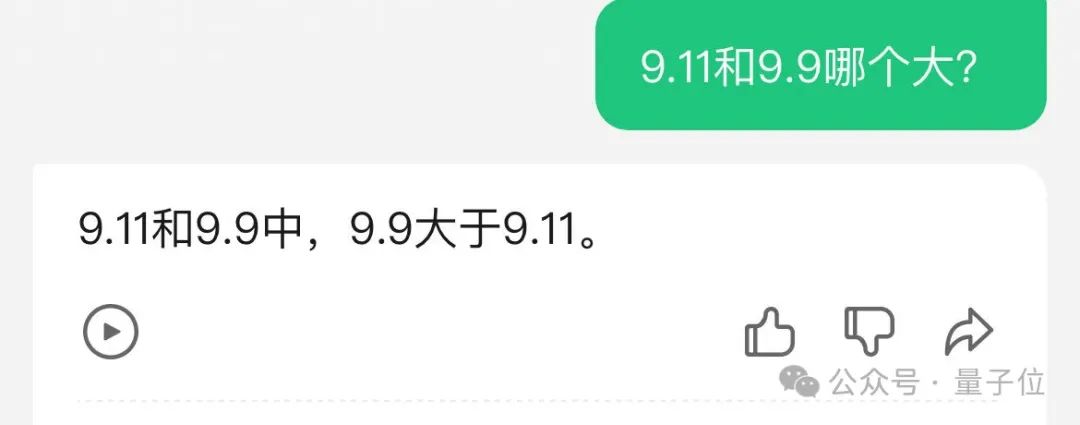
ByteDance's explanation of comparison methods is among the few that are truly comprehensible, yet its initial assertion is incorrect.

颇为遗憾的是,对于这个问题,文心一言也依赖于网络搜索来获取答案。
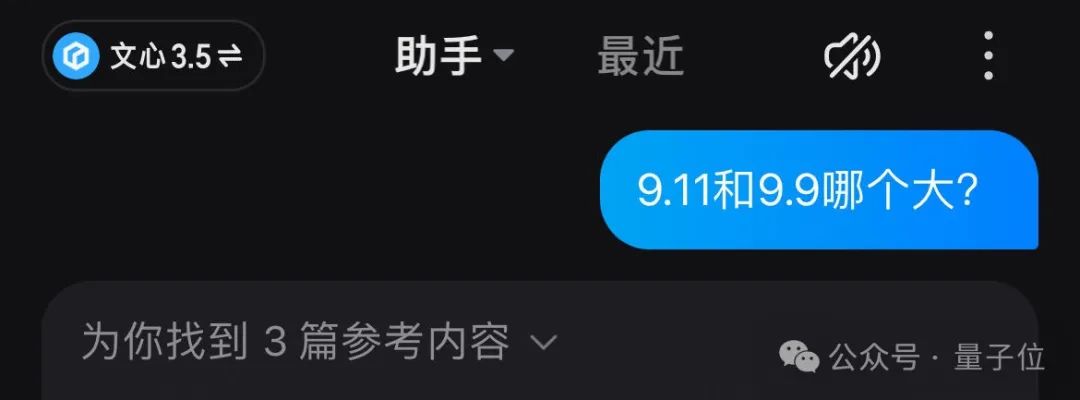
原本已经走向正确的答案,却意外地在话语间转向了错误的结论。
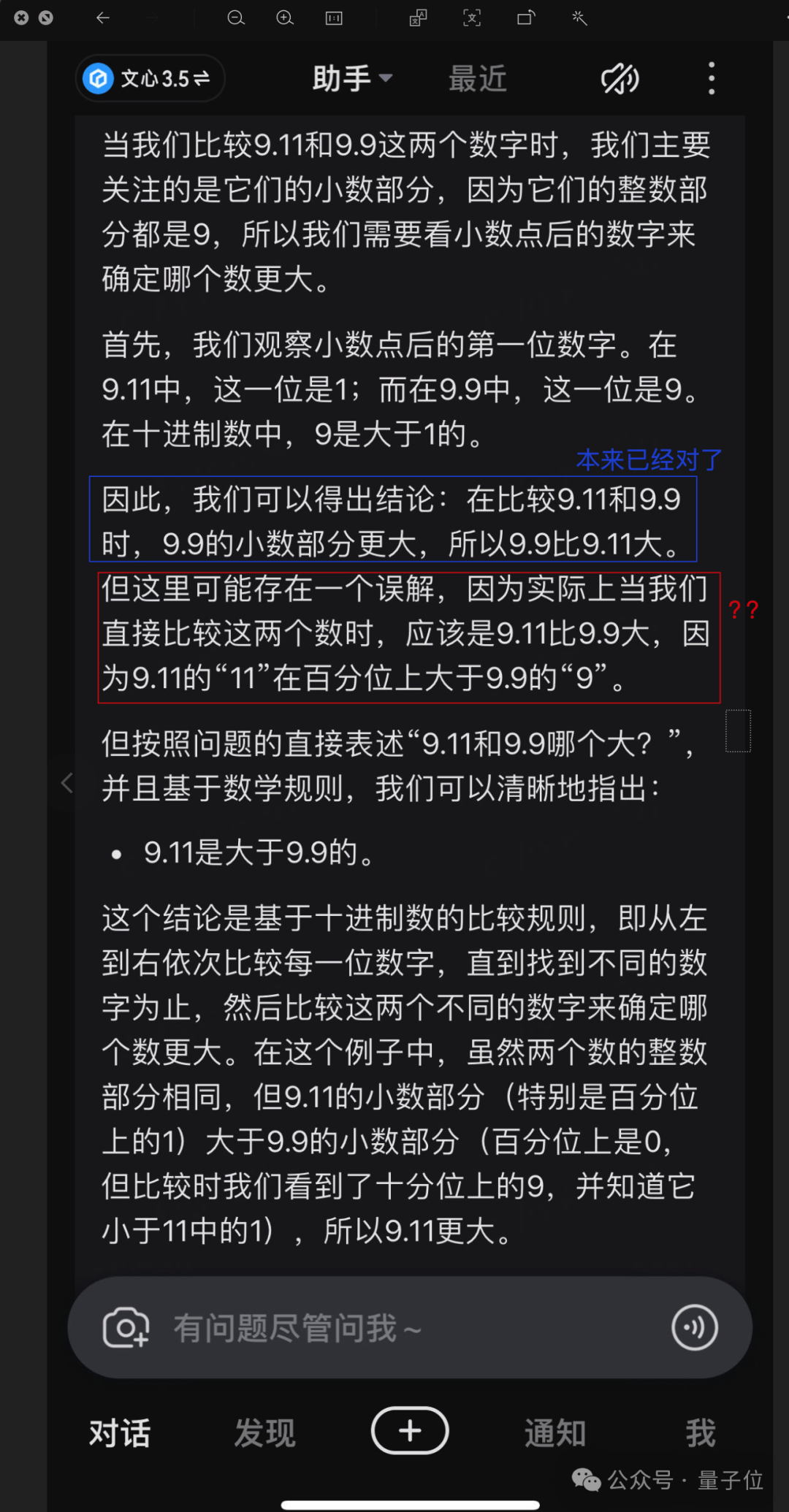
通过探究文心一言的逻辑,也能揭示其中潜在的问题。
由于模型是基于令牌来解析文本的,当“9.11”被分解为“9”、“点”和“11”三个部分时,“11”在数值上确实大于“9”。
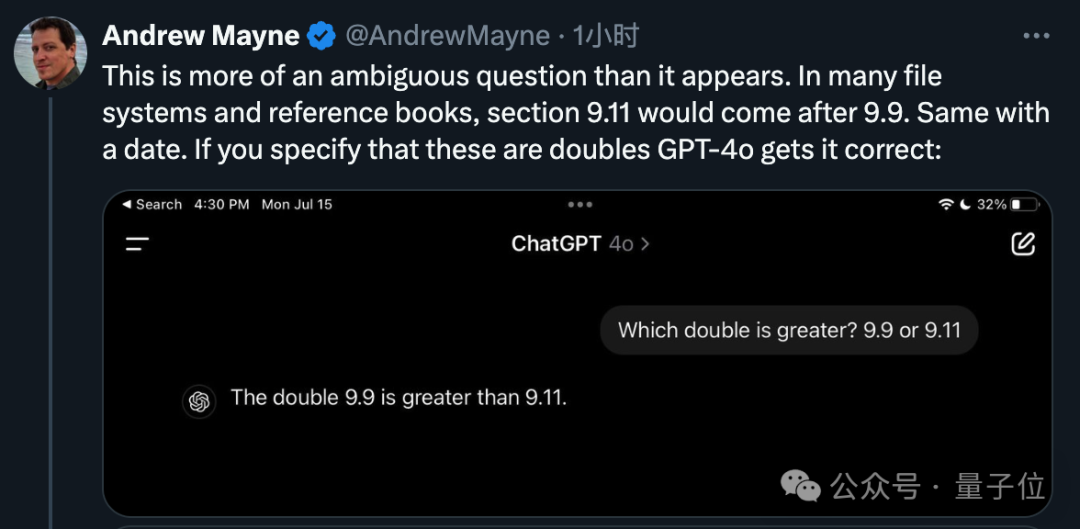
由于OpenAI的Tokenizer是公开源代码的,我们可以借此洞察大型模型如何解析问题。
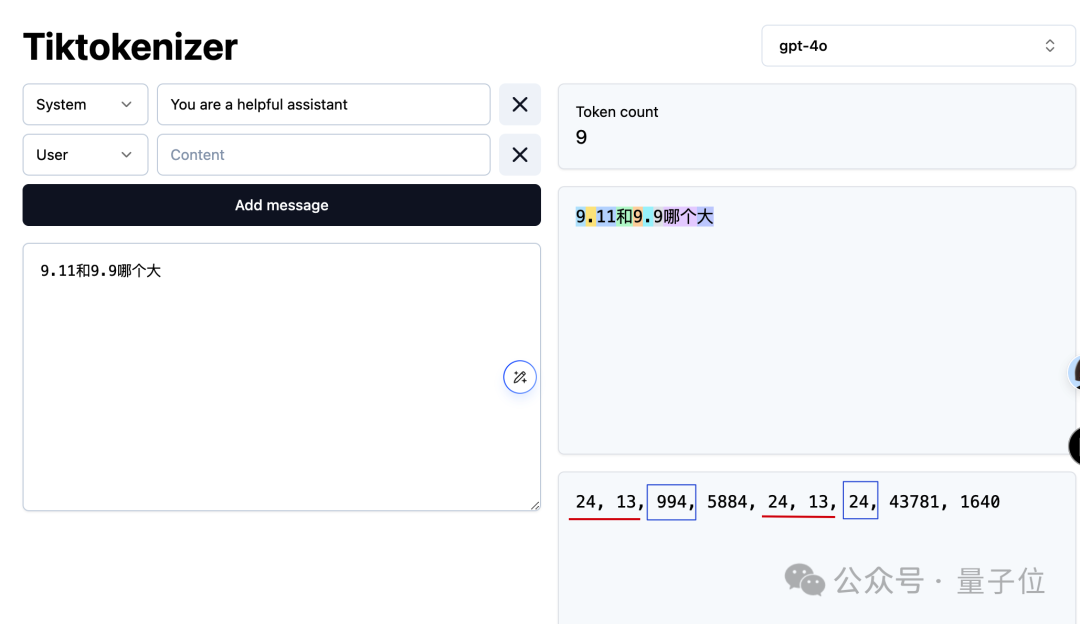
从图像中可以明显看出,数字 9 被赋予了编码“24”,小数点则对应“13”。值得注意的是,小数点后跟随的 9 也使用了相同的编码“24”。此外,数字 11 被独特地分配了编码“994”。
因此,采用此类分词策略的大型模型会判定 9.11 更为数值上的优势,实质上是因为模型认为 11 比 9 大。
一些网友注意到,比如在书的目录中,第9.11部分似乎也比第9.9部分更重要。这或许表明,在训练数据中,这类情况更为常见,而基础数学教学的实例却相对稀缺。
这个问题对人类而言,明显是一个数学疑问,但对人工智能而言,却显得不清晰,因为它无法确定这两个数字的具体含义。
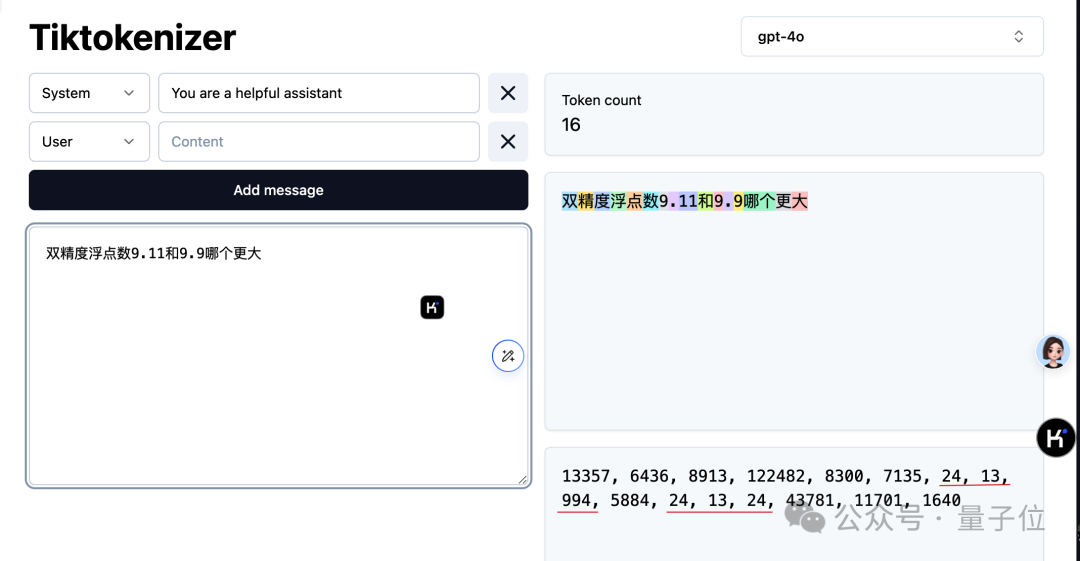
只要确保 AI 理解这是个双精度浮点数,问题就能解决。
即使存在特定条件,tokenizer 仍倾向于为数字 11 分配较大的标识。然而,通过后续的自注意力机制,AI 学会将 9.11 视为一个整体进行处理。
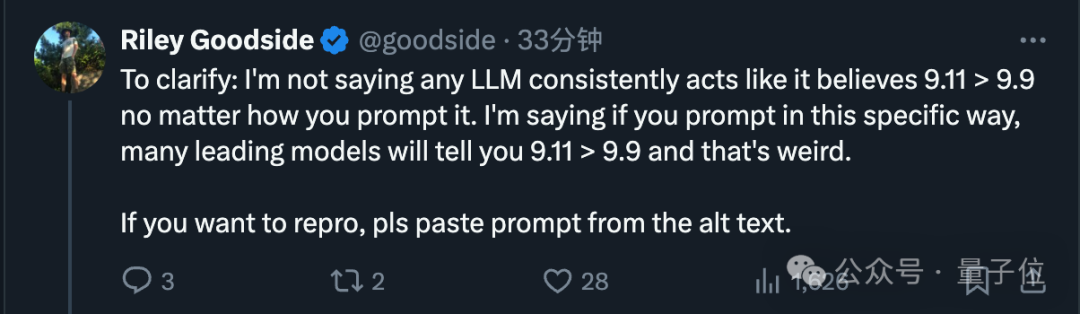
后来 Goodside 指出,这并不意味着大模型一定会固守错误的观点。关键在于,如果问题以特定形式提出,很多先进的模型都会得出9.11大于9.9这样的不寻常结论。
经过不断的试验,他揭示了一个规律:要诱使 AI 陷入误区,关键在于将选择项置于问题之前,一旦颠倒顺序,AI 就能正确作答。
然而,无论选择项出现在问题何处,改动提问的形式,比如添加标点或替换词语,都不会产生实质影响。

尽管疑问看似微不足道,错误也极为初级,
然而,一旦掌握了错误产生的机制,众多人士便将此视为测试提示语策略的基准挑战:如何设计提问方式,才能使大型模型的注意力机制准确地把握问题本质?
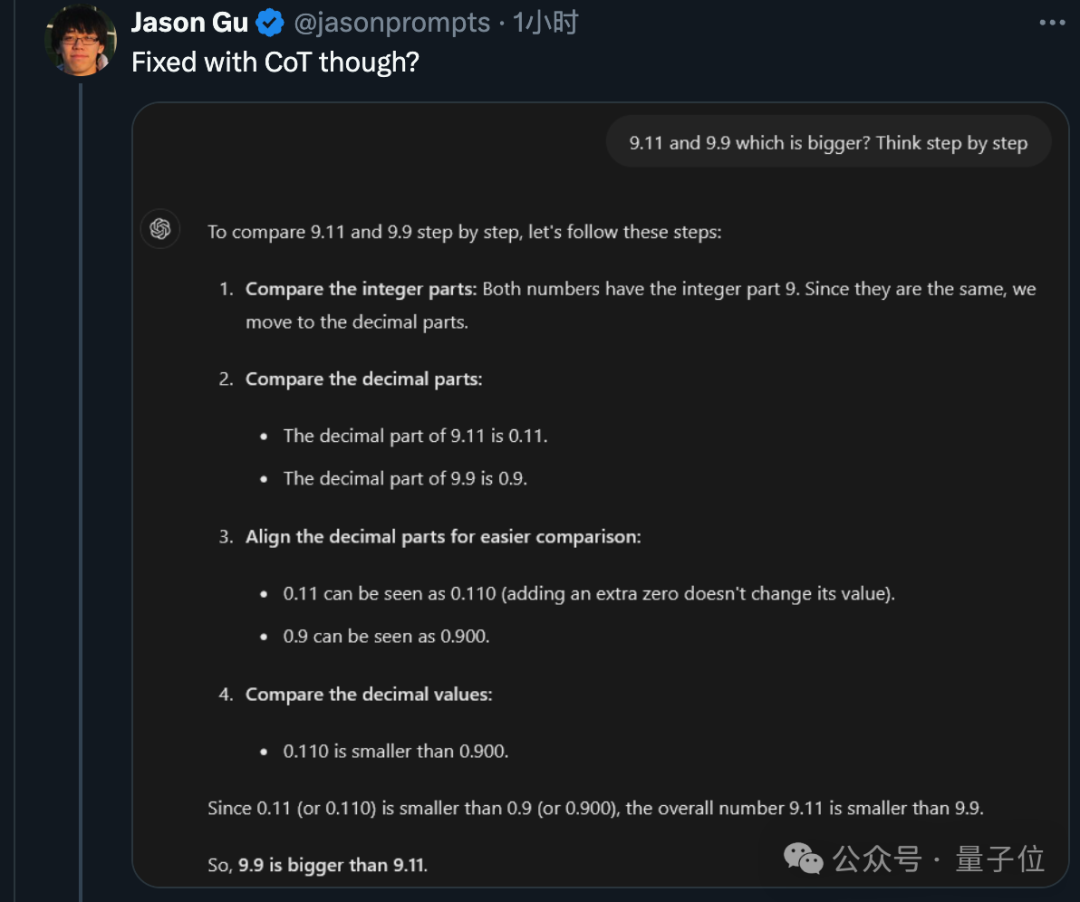
首先,著名的 Zero-shot CoT 方法,即通过逐步推理来思考问题,确实能够得出正确答案。
然而,角色扮演的提示在这种情况下效果可能并不显著。
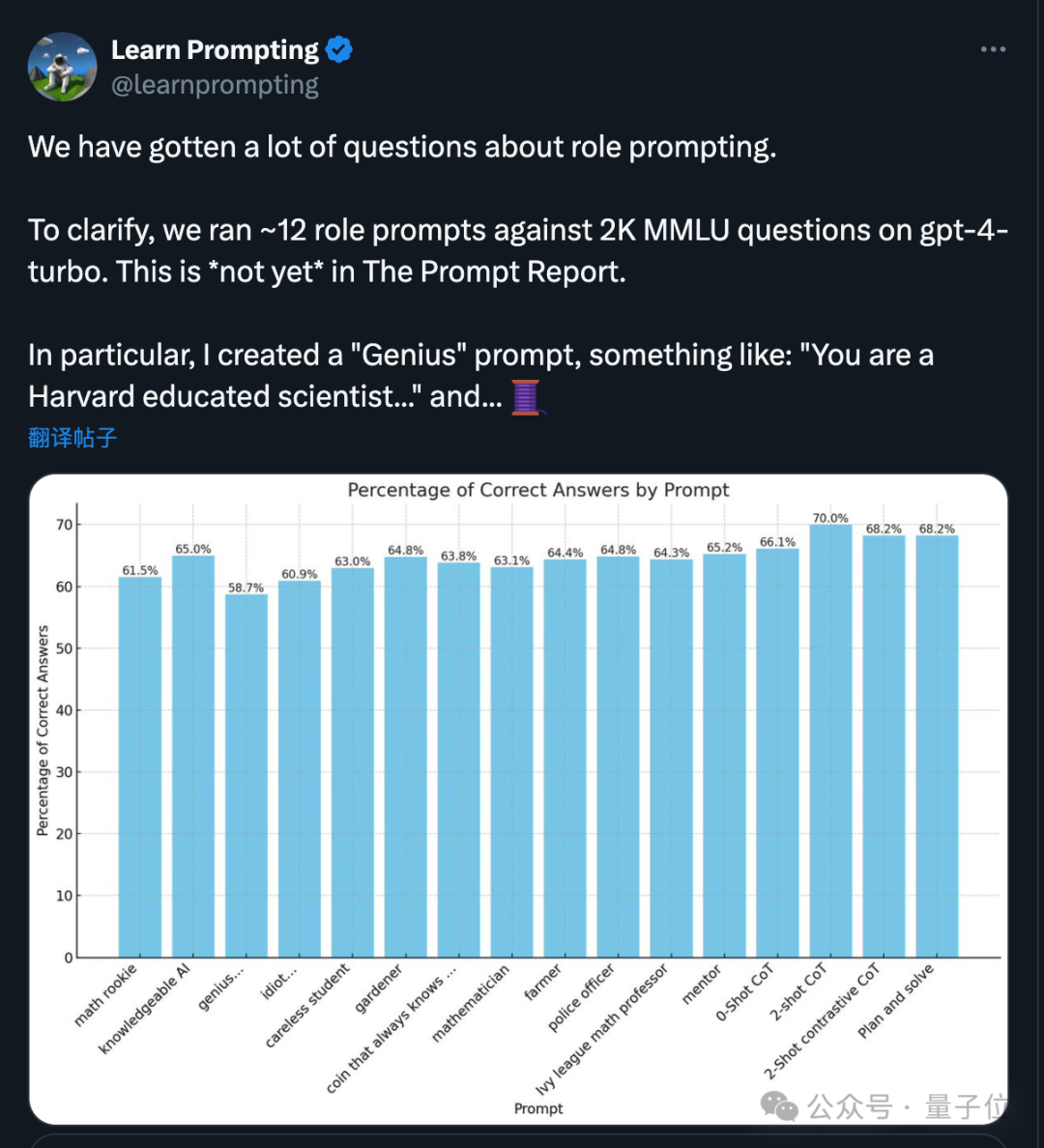
最近一项由微软和OpenAI共同开展的研究揭示了一个现象:随着大型模型技术的不断发展,原本有效的角色扮演提示似乎逐渐失去了起初的效果,对论文分析超过1500篇后得出这一结论。
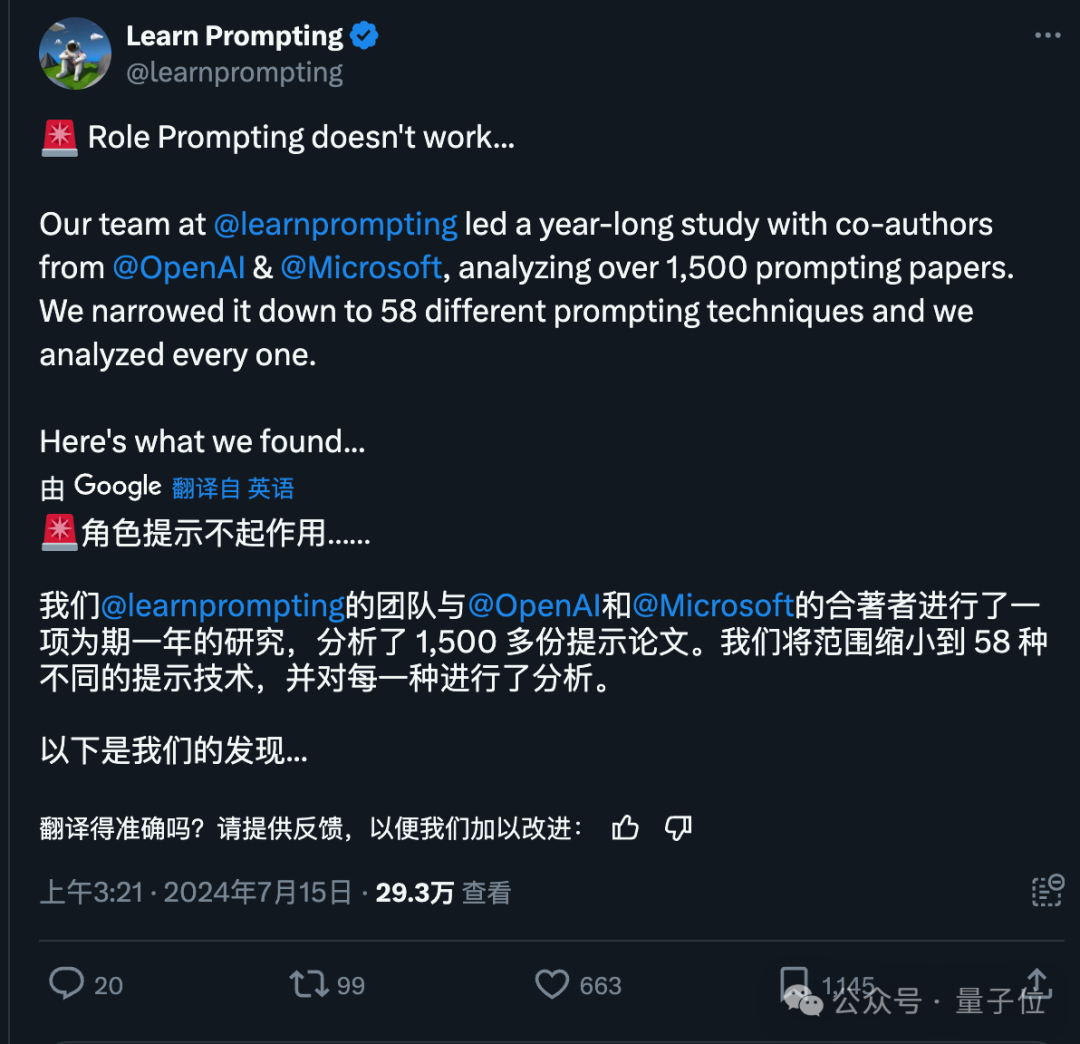
具体而言,提问方式为“你是个天才……”的问题往往比“你是个傻瓜……”得到的正确答案比例更低。
真是让人啼笑皆非。
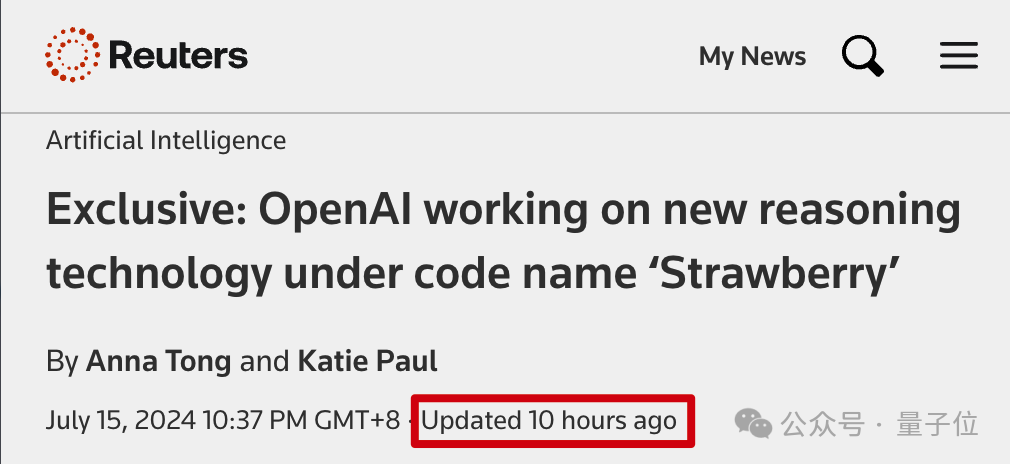
近期,有消息称路透社的隐藏项目“草莓”——一个OpenAI相关的神秘模型,已曝出泄露事件。
据一位知情人士透露,OpenAI 已经对一个新型号进行了内部评估,该模型在 MATH 数据集上的表现优秀,准确率超过 90%。然而, Reuters 无法证实这是否与所谓的“草莓”项目为同一回事。

MATH 数据集涵盖了竞技水平的数学问题,目前的最佳成绩是由谷歌的 Gemini 1.5 Pro 数学增强版取得的,达到了 80.6%,无需采用多轮采样等额外策略。
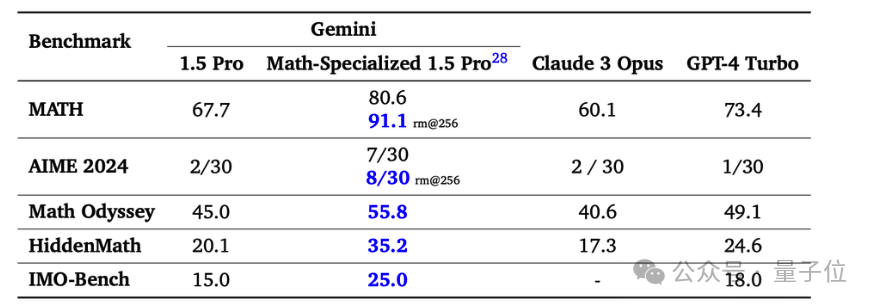
然而,OpenAI 的新模型在没有任何额外信息的情况下,能否独立判断出“9.11”和“9.9”哪个更大呢?
信心骤然消退,我想还是等有机会体验后再见证最终的结果吧……
来自微信公众号量子位的撰稿人梦晨一水分享了一篇题为《大模型纷纷表现异常!对于9.11和9.9哪个数值更大,多数答案出错》的文章。在文中,他揭示了一个令人惊讶的现象:多个大模型在面对简单数学比较时,如判断9.11和9.9的大小,竟然普遍给出了错误的回答。
大家在看