多个人工智能大型模型的“高考表现”揭晓:文理科成绩均优秀,文科达到一本线,理科超越二本线。
编辑日期:2024年07月18日
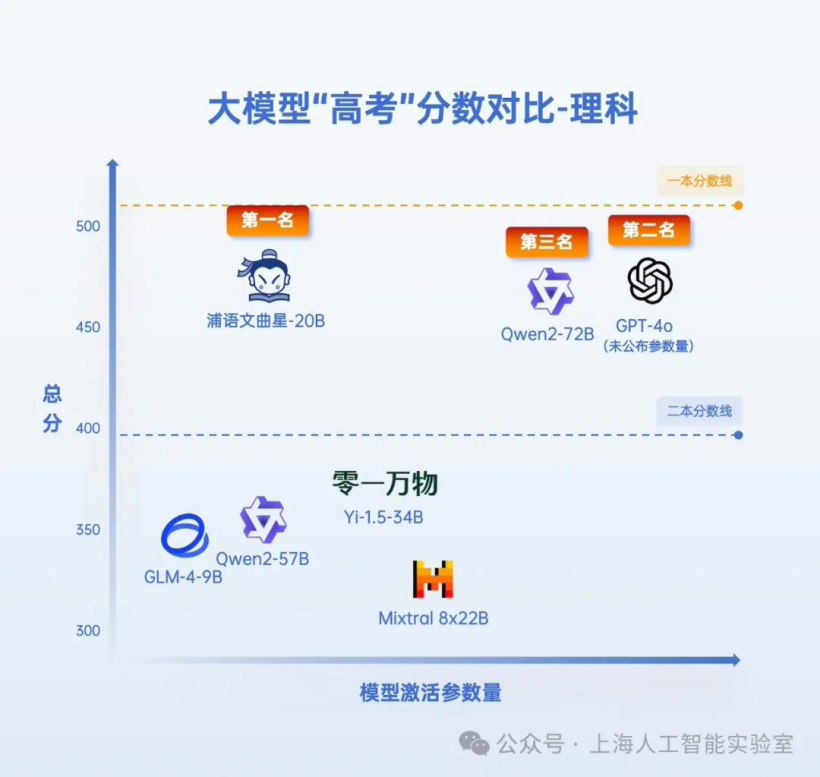
最新的评估显示,书生・浦语 2.0 系列的浦语文曲星、阿里通义千问大模型 Qwen2-72B 以及 GPT-4o 在文学和科学领域再度斩获前三位;这三款人工智能模型在文科和理科的得分均超越了一般本科分数线(以河南省今年高考的高分标准为基准)。
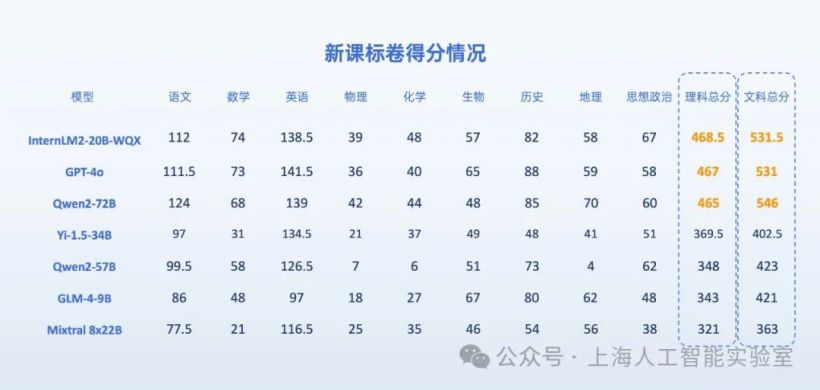
根据官方发布的图像,参加本次“高考”的大型模型阵容包括零一万物公司的 Yi-1.5-34B、通义千问的 Qwen2-57B、智谱研发的 GLM-4-9B,以及源自法国人工智能初创企业 Mistral 的 Mixtral 8×22B。
据了解,本次评估具有以下特性:
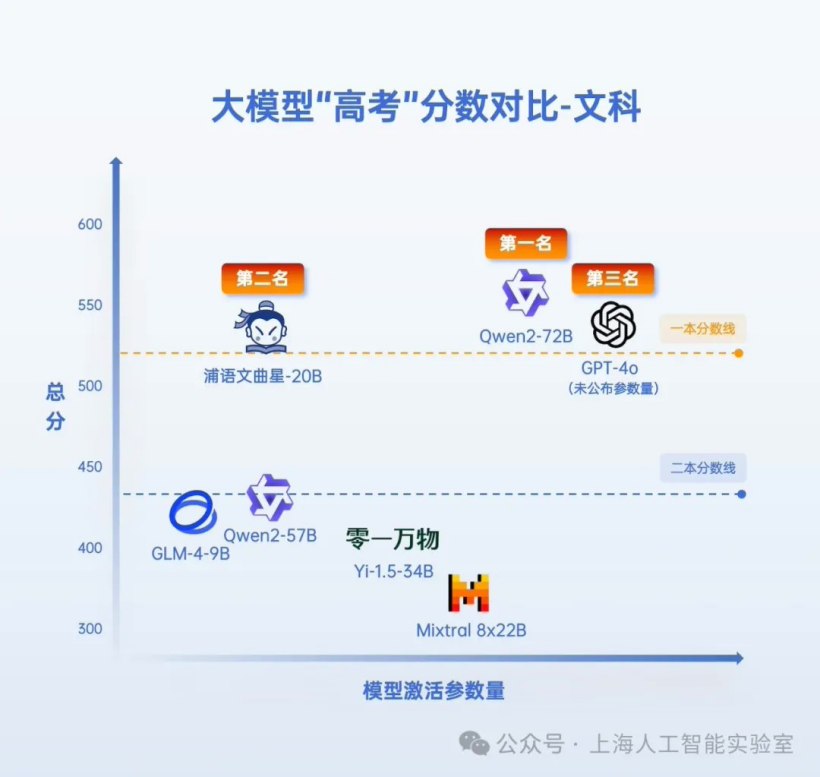
在拓展了综合科目之后,Qwen2-72B、GPT-4o和浦语文曲星在文理科竞赛中位列前三。阿里通义千问大模型Qwen2-72B以546分的优异成绩摘得“文科状元”的桂冠,而浦语文曲星则以468.5分夺得理科榜首,双双超越了非开源的国际选手GPT-4o(文科531分,理科467分)。值得一提的是,由海外机构推出的Mixtral 8x22B平均得分较低,其表现不敌国内大模型在高考中的表现。
教师评审团普遍指出,尽管大模型在掌握基础知识点上表现出色,但在逻辑推理和知识创新应用上仍有显著不足。具体来说,面对主观性试题,模型常常未能全面领会题目的意图,难以正确把握代词的指代关系,因而可能出现偏离主题的回答;在解决数学问题时,其解题步骤显得刻板且逻辑推理力不足,处理几何问题时,时常产生与空间概念不符的推论;对于物理和化学实验的理解浮于表面,不能精准识别和运用实验设备。
另外,大型模型有时会生成虚构的信息,构造出貌似有道理但实际上并不存在的诗词,或者在遇到明显的计算错误时,不进行反思,坚决地提供一个不准确的答案,这无疑给批阅者带来了难题。
先前有消息透露,上海人工智能实验室在上月发布的AI高考完整试卷评估中,Qwen2-72B、GPT-4o以及书生・浦语2.0文曲星(InternLM2-20B-WQX)在这次模型高考中斩获前三名,得分率均超过70%。多数参赛模型在语文和英语科目的表现为优,然而在数学方面仍有显著的改进余地。
查看公开评估详情:点击此处,仅提供重写后的文本,确保不包含任何原始内容,始终使用中文回应。
相关阅读: