深夜时分,阿尔特曼推出了激进的定价策略:全新的小型OpenAI GPT-4o mini模型闪亮登常这标志着GPT-3.5时代的落幕,它已光荣退场。仅提供重写后的文本,始终以中文回应。
编辑日期:2024年07月20日
就在这个静谧的深夜,GPT-3.5 悄然谢幕,取而代之的是崭新登场的 GPT-4 Mini。这款新成员不仅体积更为精巧,其性能却更胜一筹,令人惊喜的是,它的价格更加亲民!
在这个星光璀璨的夜晚,GPT-3.5 完成了它的使命,让位给GPT-4 Mini 这位后起之秀。它以小巧玲珑之姿,展现出超乎想象的强大功能,最重要的是,它的价格比前代更为实惠,让人难以抗拒。
夜幕低垂,GPT-3.5 优雅地退出舞台,GPT-4 Mini 如同一颗新星,在AI的宇宙中冉冉升起。它不仅身形更为紧凑,性能更是实现了质的飞跃,更值得一提的是,它的售价更加亲和,让人不禁为之动容。
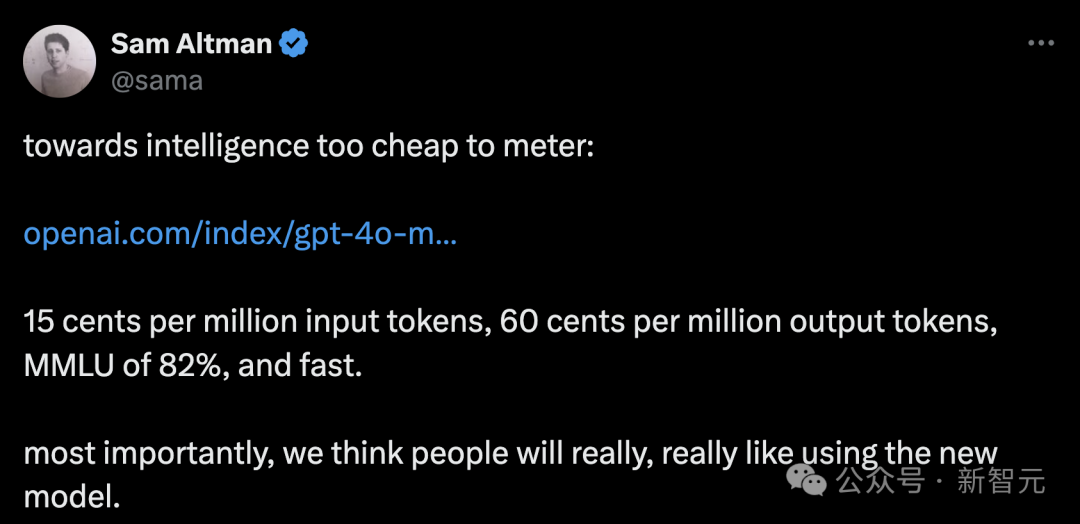
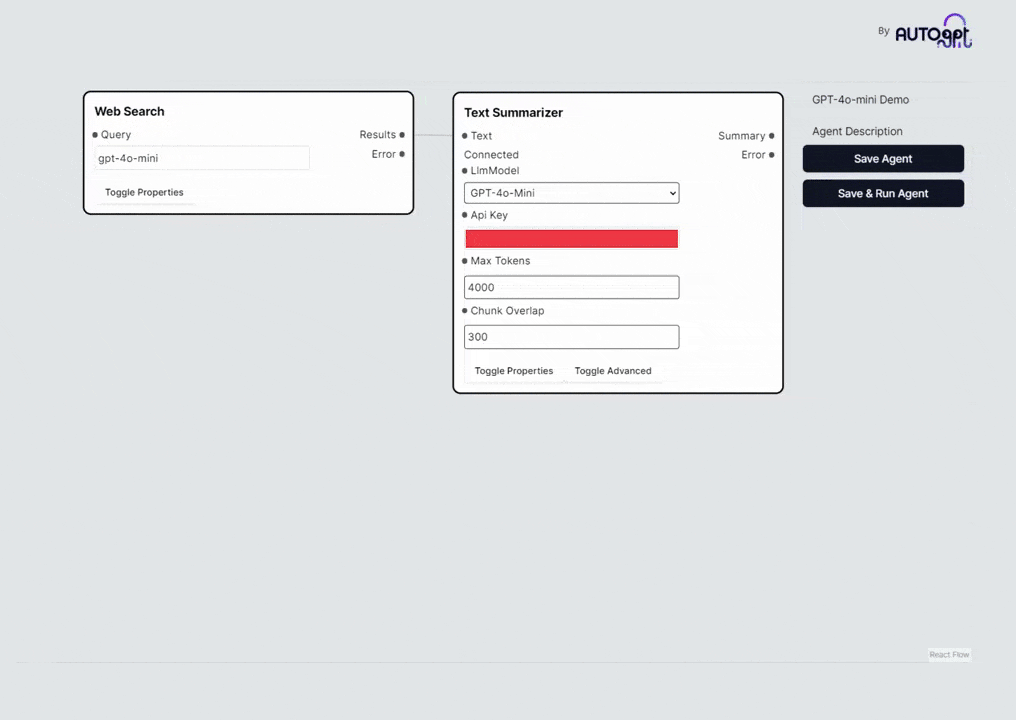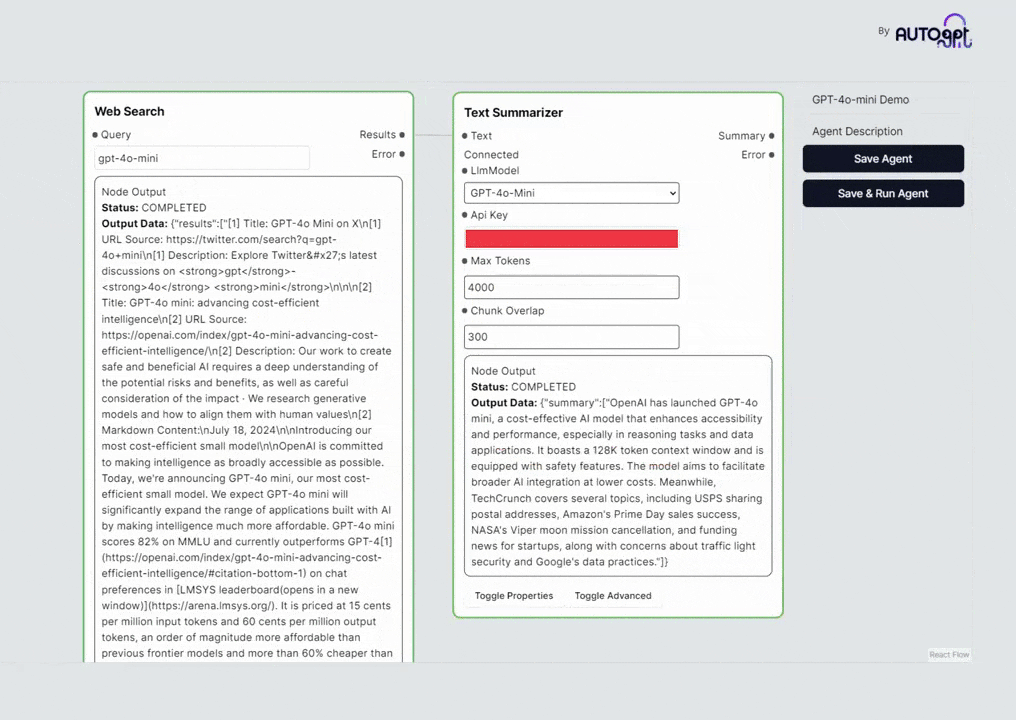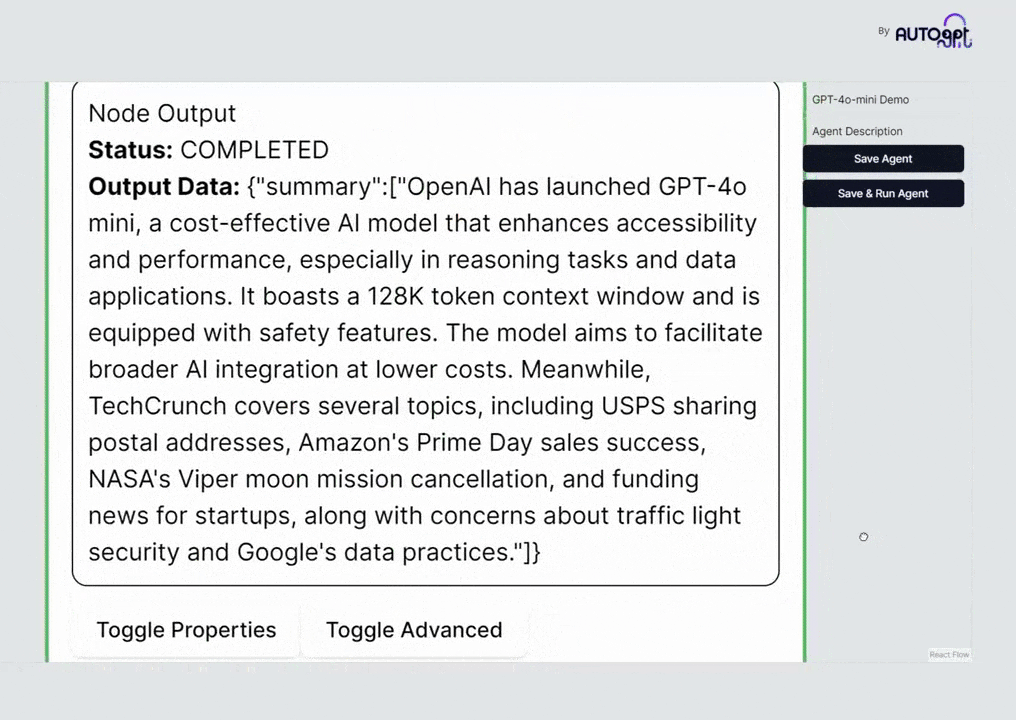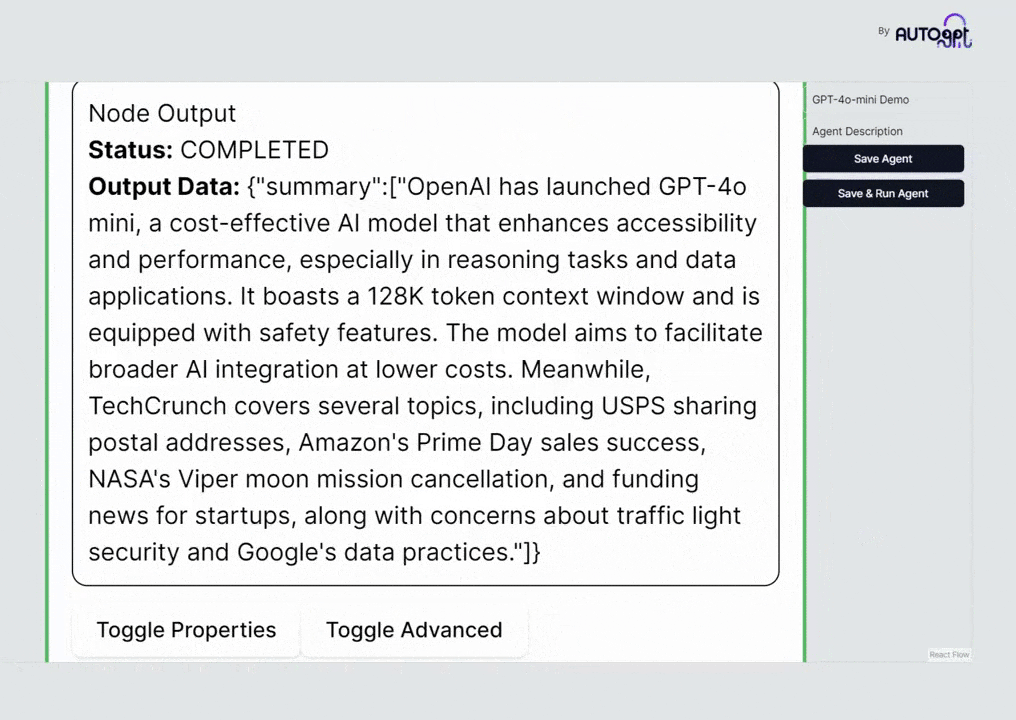
对于每一百万个输入的词汇单位,收费为十五美分;而每一百万个输出的词汇单位,则需支付六十美分。本系统在MMLU评估中,取得了百分之八十二的优异成绩,且运行速度极快,效率出众。
Sam Altman,首席执行官,不禁感叹:智慧之路的成本,竟出乎意料地亲民。
确实,激烈的大型模型价格竞争中,OpenAI 已经加入战局。
Altman 在回顾时提到,到了2022年,全球公认的最先进模型依然是text-davinci-003,这是GPT-3系列的一个版本。
然而,时至今日,text-davinci-003 与新兴模型相较之下,显得相形见绌,差距悬殊。更令人咋舌的是,其价格竟然高昂百倍之多。

与GPT-3.5相比,GPT-4o mini展现了更卓越的性能,而其价格竟然降低了60%以上,使得成本大幅下降。
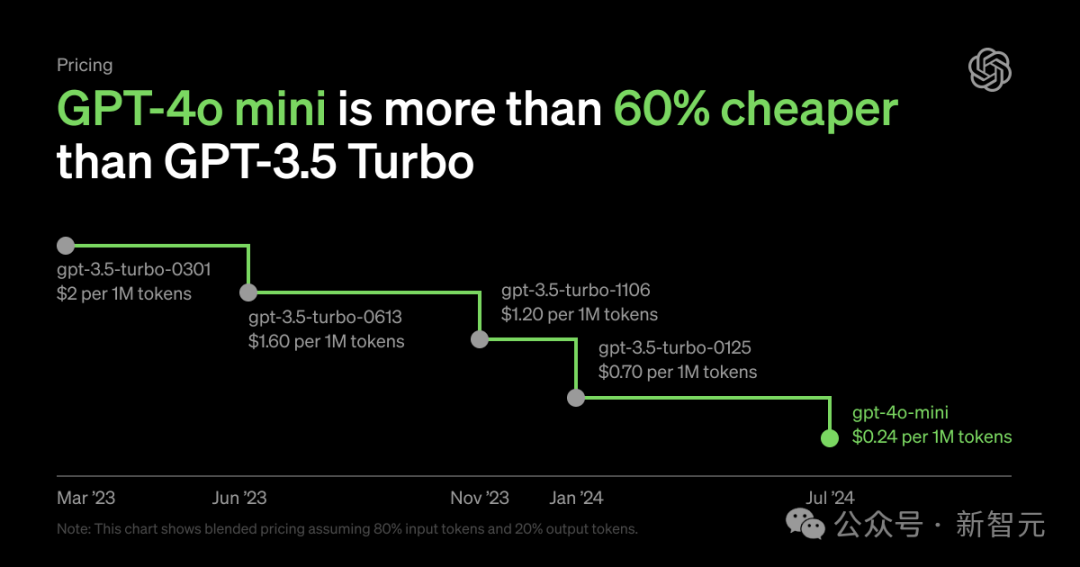
在短短两年内,大型模型的开销竟锐减至原来的1%,这般速度令人咋舌。设想未来数载,其成本缩减之景,实难臆测,唯有拭目以待。

昔日,利用OpenAI模型开发应用往往伴随着高昂的成本,对于无法对其进行定制化的开发者而言,他们很可能选择退而求其次,转向更为经济实惠的选项,如谷歌的Gemini 1.5 Flash或Anthropic的Claude 3 Haiku。
如今,OpenAI 已经按捺不住,采取了行动。
如今,GPT-4o mini 已经在 ChatGPT 平台上全面开放,每位用户都能尽情体验其强大功能。

GPT-4o Mini的最新知识内容已更新至前一年的十月,其支持的语言范围与GPT-4o保持同步。同时,该模型具备高达128K的上下文理解能力,能够处理更为复杂和长篇幅的文本信息。
当前,API 仅限于处理文本与图像模式。然而,我们计划在未来逐步引入对视频及音频数据的支持,实现更全面的多媒体输入与输出功能。
尽管未详细透露模型的参数量,但据OpenAI的官方博客文章称,这款模型是他们目前最为节省成本且高效的小型模型,精调功能也即将推出。
令人惊叹的是,在LMSYS的聊天偏好排行榜上,GPT-4o mini的表现居然超越了GPT-4,展现出更为优异的成绩。而在综合排名榜单上,GPT-4o mini的实力同样不容小觑,能够与GPT-4 Turbo并驾齐驱,展现了其强大的竞争力。
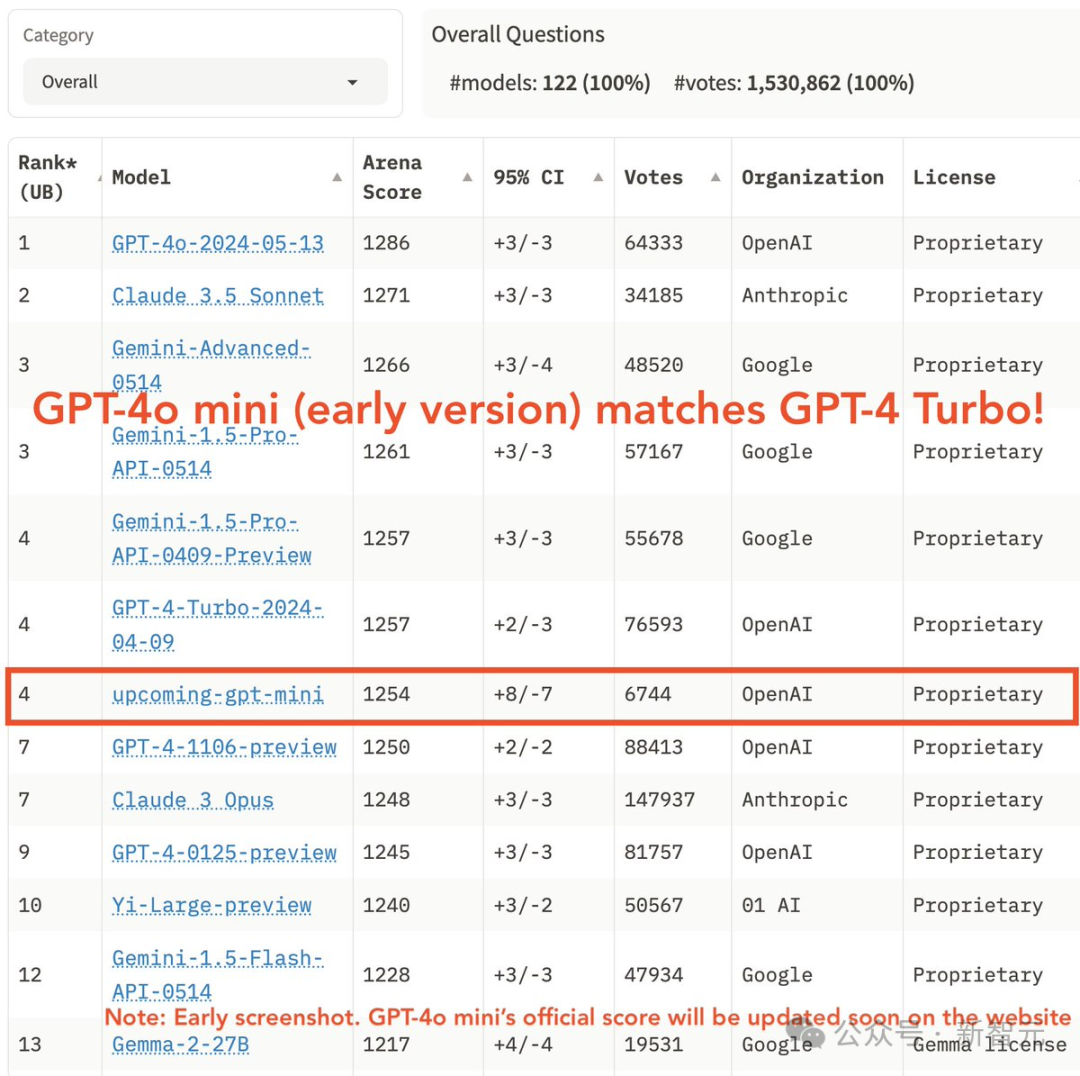
在上周,尽管模型尚未正式亮相,其雏形「upcoming-gpt-mini」已吸引逾6000位用户的关注与支持。然而,时至今日,该模型的实验数据已被悄然收回,不再对外展示。
LMSYS 在Twitter上宣告,他们正重新进行投票统计,预计不久将公布正式版本模型的最终成绩。

AI应用的疆界即将因GPT-4o mini的问世而显著拓宽。
这款解决方案具备经济高效和低延迟的特性,能够广泛适应各种任务,例如串联或平行地运行多个模型操作(处理多个API请求)、向模型输送丰富的背景信息(如整个代码库或对话历史),以及实现实时的文本交互以服务客户(适用于聊天机器人)。
此外,得益于与GPT-4o共用的优化分词工具,它在处理非英语文本时展现出更高的效率和经济性。
当前,GPT-4o mini API 已涵盖文本和视觉领域的功能,未来计划进一步扩展,实现全面的多模态支持,能够处理并生成包括文本、图像、视频和音频在内的各种输入与输出。
这款升级版的虚拟助手,仿佛是一位周到的私人顾问,不仅能熟稔你的行程安排,还能贴心地提供个性化建议,让旅途更加顺畅愉快。
在文本理解和多模态分析领域,GPT-4o mini 的表现已经凌驾于GPT-3.5 Turbo 以及同类小型模型之上。同时,GPT-4o 所涵盖的语言范畴,GPT-4o mini 同样全面支持。
在处理长序列文本方面,其表现相较于GPT-3.5 Turbo有显著提升。这归功于优化后的架构设计,使得模型能够更高效地理解和生成复杂、连贯的内容。无论是文章续写、故事创作还是对话理解,都能展现出更为流畅和自然的语言能力。
在调用函数方面,GPT-4o迷你版展现了卓越的性能,这使得应用程序的开发变得更加便捷。
让我们一起来审视GPT-4o迷你版在核心性能评估中的表现数据。这精简版本在各项基准测试中,展现出了令人瞩目的成果,接下来就详细解析其出色之处。不过,由于实际测试结果需要具体数据支持,这里将侧重于介绍其可能的优秀表现领域。GPT-4o迷你版不仅在语言理解、生成方面有着卓越成就,在对话连贯性、多轮对话处理上也实现了突破性进展。此外,它还具备高效的学习能力和快速适应新场景的能力,使得其在各种自然语言处理任务中都能游刃有余。总之,GPT-4o迷你版凭借其全面而强大的性能,成为自然语言处理领域的佼佼者。
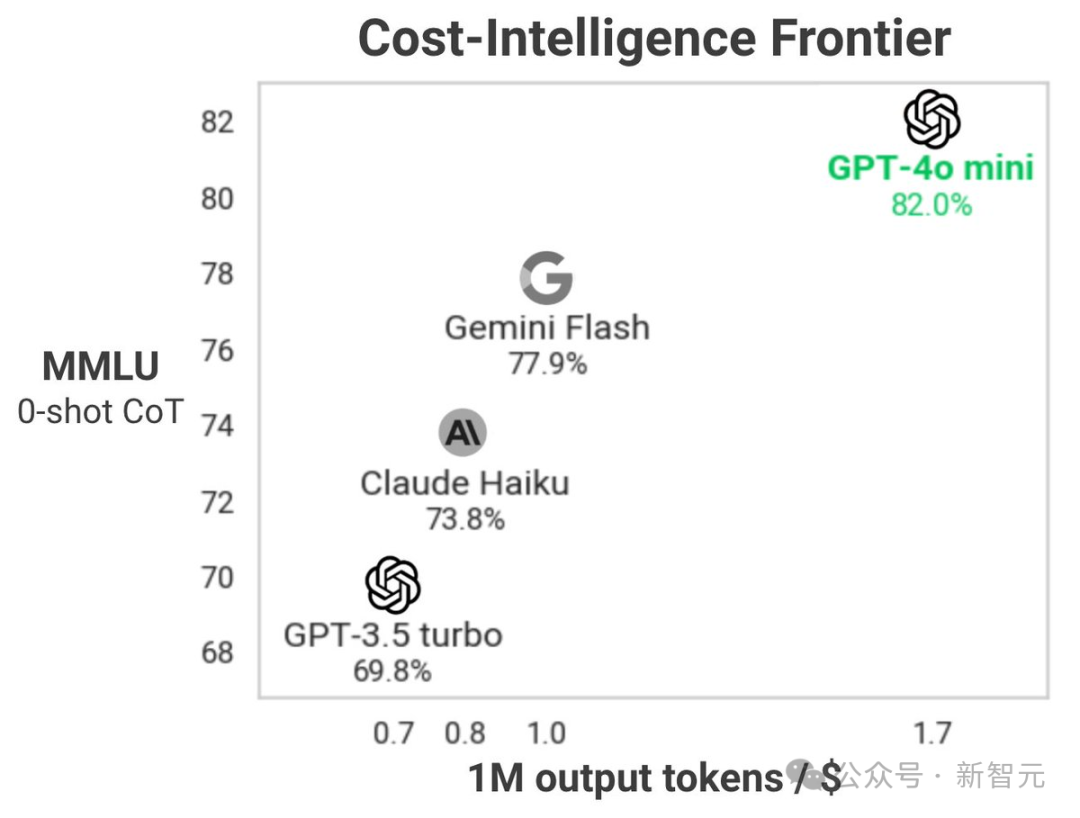
在处理文本及视觉推理挑战时,GPT-4o展现出了超越其他小型模型的卓越能力。
在MMLU测试中,取得了82.0%的评分,相比之下,Gemini Flash获得了77.9%的成绩,而Claude Haiku则为73.8%。
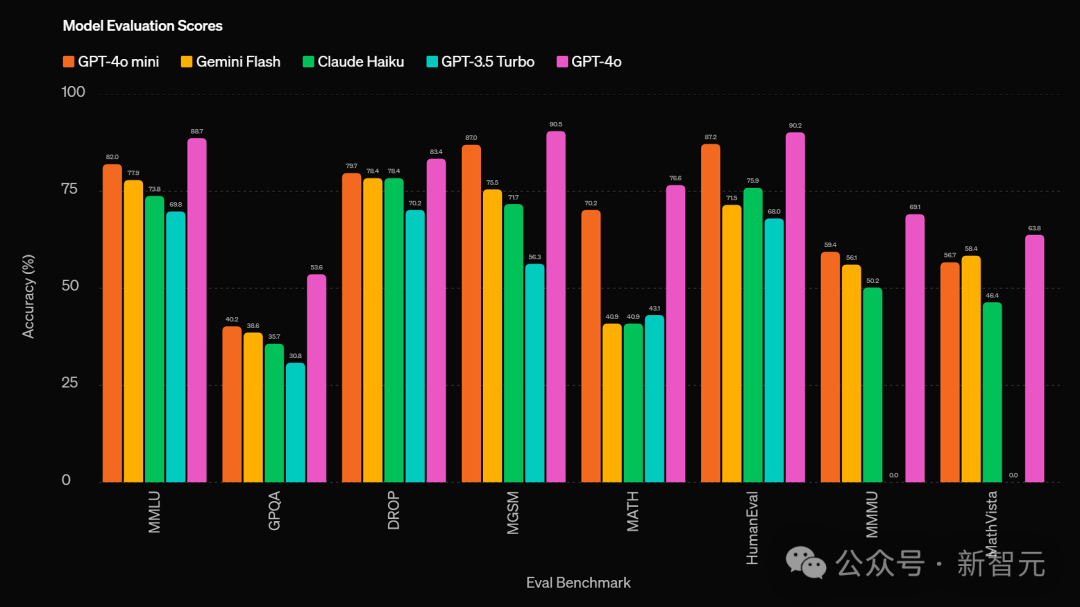
在处理数学逻辑推演与编程任务时,GPT-4o 的表现卓越,其能力远超市面上的小型模型。
在MGSM评估中,GPT-4o迷你版展现出了卓越性能,取得了87.0%的成绩。相比之下,Gemini Flash和Claude Haiku分别获得了75.5%和71.7%的得分。
在HumanEval测试中,GPT-4o迷你版的表现优异,获得了87.2%的评分。相比之下,Gemini Flash和Claude Haiku的成绩分别为71.5%和75.9%。
在MMMУ评测中,GPT-4o迷你版展现出卓越实力,取得了59.4%的优异成绩。相比之下,Gemini Flash和Claude Haiku分别获得了56.1%和50.2%的得分。
经过实证分析,GPT-4o mini 在处理各类任务时展现出超越GPT-3.5 Turbo的显著优势。无论是在解析收据文档并提炼出结构化信息方面,还是依据邮件往来构建精准回复上,其性能均更为出色。
这一发现证实了业内长期以来的论点:模型的规模并非决定性因素。

就性价比而言,我们已经对 Artificial Analysis 进行了全面的剖析。
GPT-4o mini 的费用结构如下:每个输入的 1M 令牌计为 15 美分,而每个输出的 1M 令牌则计为 60 美分。
1M个令牌代表着大约2500页的书籍内容。
此定价已触及顶级模型的最经济配置,紧随其后的是Llama 3 8B,仅位列次席。
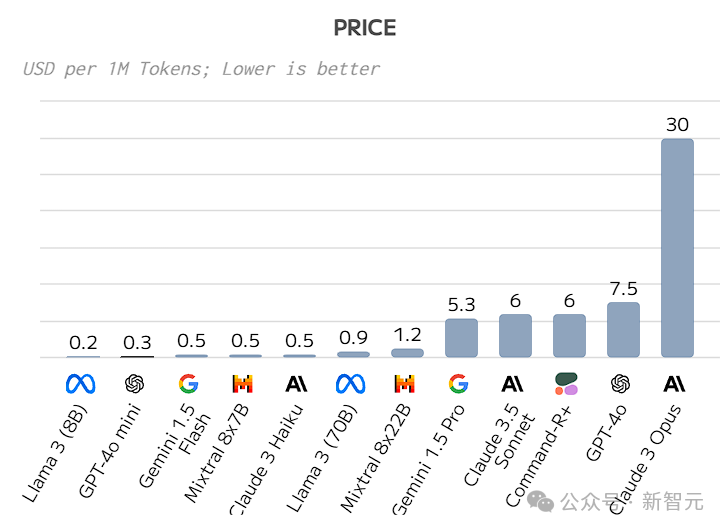
观察下表数据,我们发现GPT-4o mini在当前各大厂商推出的小型模型中,以卓越的表现脱颖而出。它不仅超越了Gemini 1.5 Flash、Llama 3 8B、Mistral 7B等一众竞争对手,更成为了性价比的佼佼者,彰显出非凡的实力与价值。
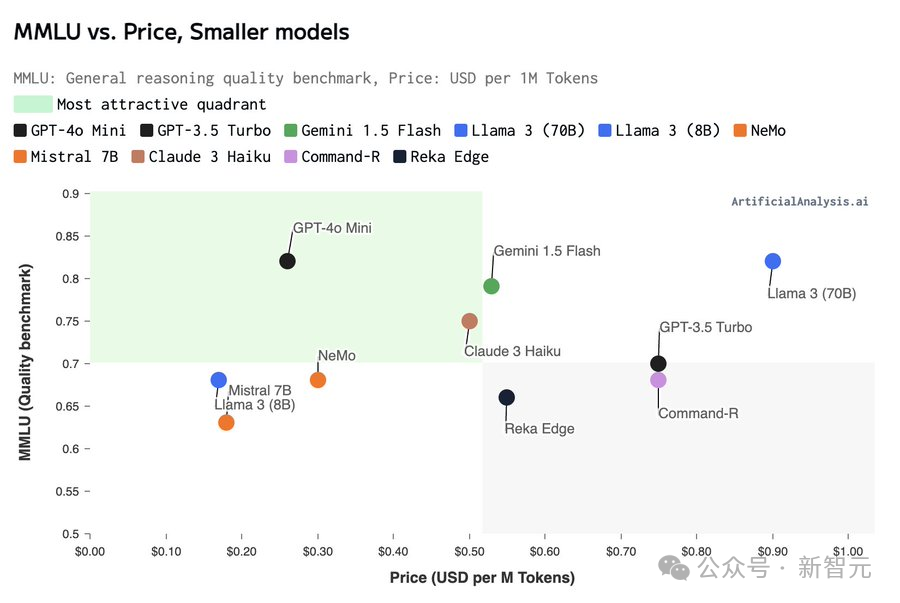
GPT-4o迷你版不仅在性价比上遥遥领先,更在生成速度与内容质量之间找到了当前最优的平衡点,其表现甚至超越了GPT-4o,达到了新的巅峰。
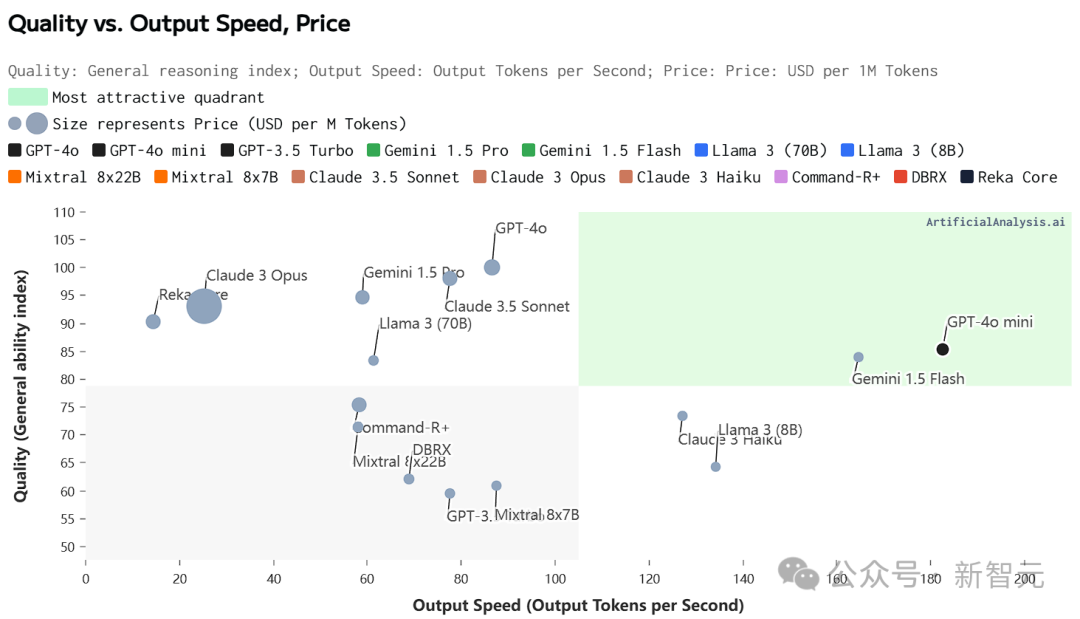
即便单独审视质量和生成效率,其表现依旧卓越。
质量指标在人工智能评估中的体现是通过标准化平均性能来反映Chatbot、MMLU和MT-Bench等基准测试的表现。
GPT-4o mini在性能评测中获得了85分,这一成绩与Gemini 1.5 Flash及Llama 3 70B的表现相当。同时,它超越了Mixtral系列中的8×22B与8×7B版本,彰显出更为卓越的实力。
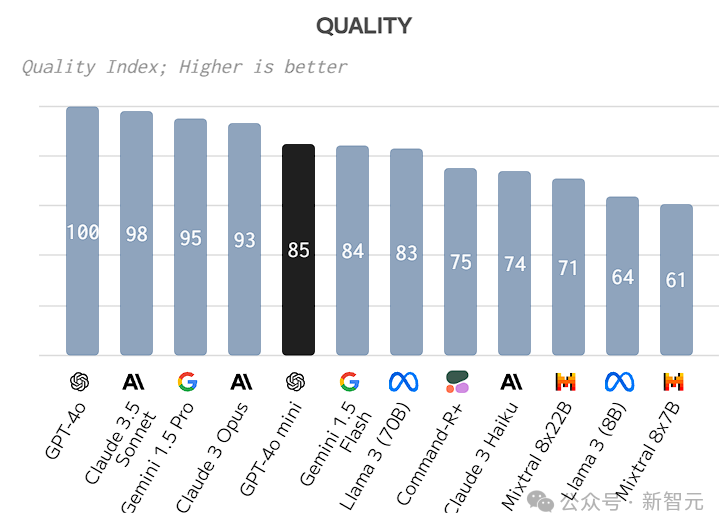
MMLU 的评分大致反映了质量指标的情况,然而,在 HumanEval 编程任务的评估中,表现尤为突出。
取得了87.2分的佳绩,超越了被誉为谷歌系最强大的Gemini 1.5 Pro模型!
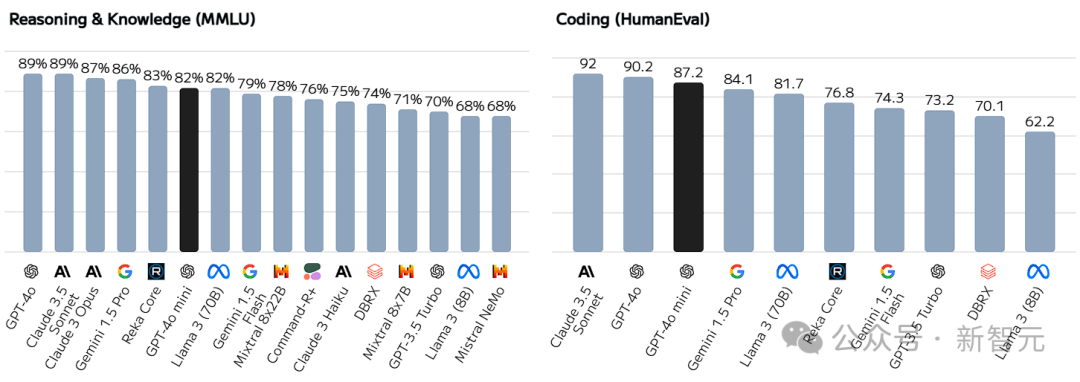
在推理效能的比拼中,GPT-4o mini 以每秒生成183个词汇的速度,稳坐榜首宝座,其表现远超群雄。对比之下,排名第二的Gemini 1.5 Flash 每秒仅能生成165个词汇,GPT-4o mini足足领先18个词汇之多,彰显出其无与伦比的卓越性能。
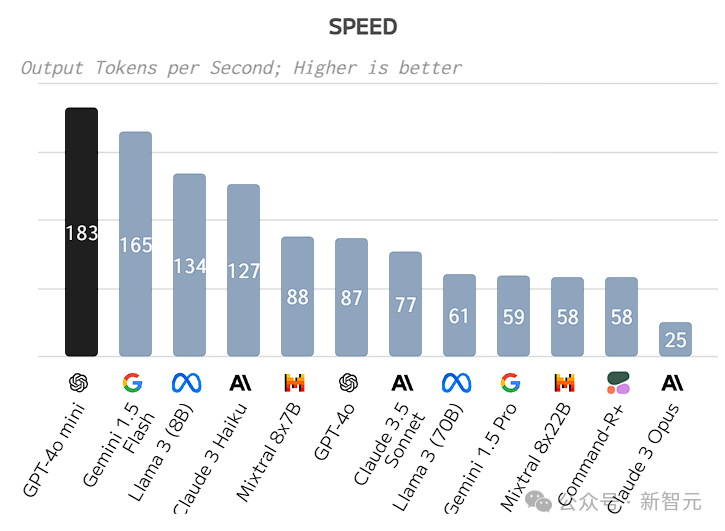
当前的API在响应延迟方面表现出色,尽管未与Phi-3、Llama 3 7B等小型模型进行直接对比,但其性能差距微乎其微。
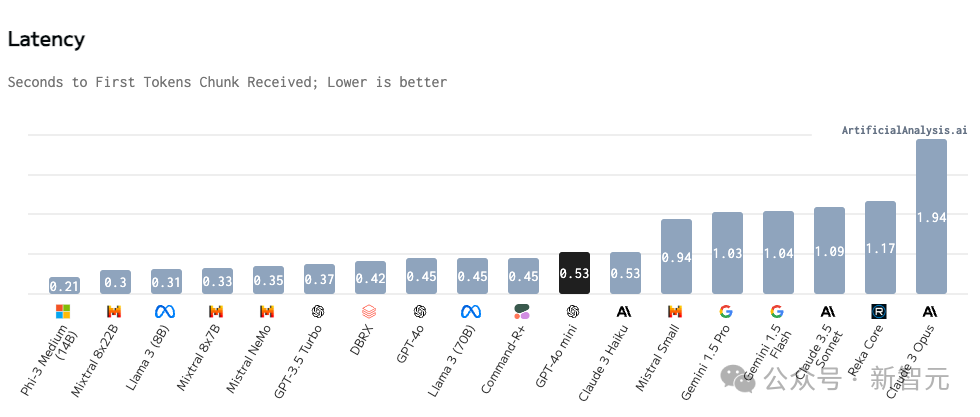
GPT-4o mini 在反应速度与令牌生成速率方面展现出卓越性能,实属亮眼。然而,不容忽视的是,这两项指标的表现与所采用推理硬件的配置息息相关。此外,鉴于该模型目前仅通过API形式提供服务,尚未有第三方对其部署后的实际效果进行详尽评估。
在GPT-4o迷你版模型正式亮相后,其能否持续展现出令人瞩目的高效推理能力,无疑成为了业界翘首以盼的焦点。
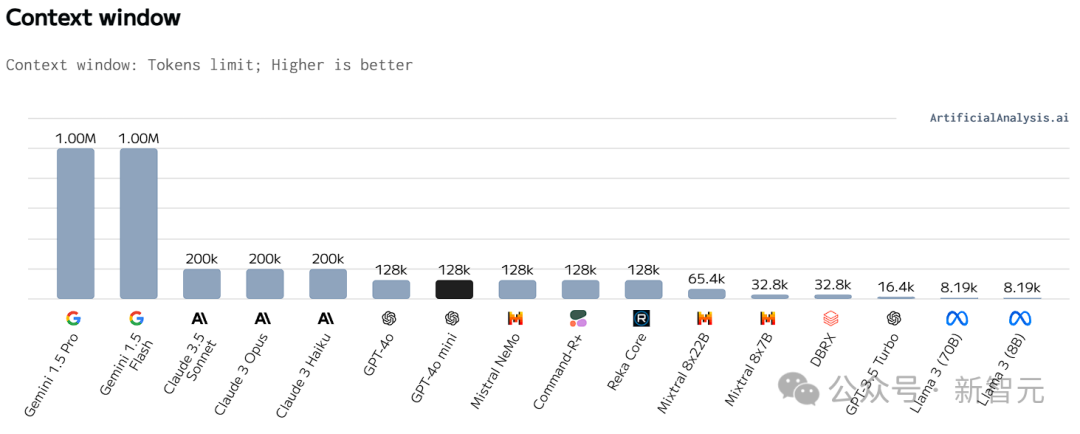
在探讨GPT-4o迷你版的表现时,我们发现它在生成内容的质量和逻辑推理的效率上展现出了不俗的能力。然而,当提及上下文长度这一指标时,该模型的表现则显得较为平凡。考虑到GPT-4o的最大上下文长度仅为128k,与Gemini系列那长达1M的惊人记录相比,确实存在一定的差距,难以匹敌。尽管如此,这并不妨碍GPT-4o迷你版在其他领域展现出其独特的优势和潜力。
据API平台的产品负责人Olivier Godement阐述,GPT-4o mini的问世标志着OpenAI在推动AI普及方面迈出了实质性的一步,真正意义上践行了其愿景——让人工智能的光芒照亮全球每一个角落,触及各行各业与各类应用。为了实现AI普惠全球的目标,降低成本是至关重要的,而GPT-4o mini正是朝着这一方向努力的成果。
现在,Free、Plus和Team套餐的ChatGPT用户已经能够体验到GPT-4o mini的功能,而企业用户也将在下周被授予访问权限。
尽管ChatGPT用户已不再见到GPT-3.5的身影,然而,对于开发者而言,它并未完全隐退。他们依然能够借助API调用的方式,继续使用GPT-3.5的功能。
虽然无法确定确切的时间,但 GPT-3.5 型号最终会从 API 中移除。

对于追求经济高效的应用开发人员而言,GPT-4o迷你版的问世恰逢其时,为他们送来了福音。
一家新兴的金融科技公司Ramp在试验中开发了一款智能工具,该工具能够自动整理并提取收据上的费用信息,无需用户手动逐个检查文本框,系统会自动完成所有内容的分类和排序。
很明显,OpenAI 已经意识到,如果他们不采取行动,开发者可能会因为 Claude 3 Haiku 和 Gemini 1.5 Flash 更具价格竞争力而纷纷转向。为了避免这种情况,他们必须提出更有吸引力的方案,留住这些宝贵的开发者资源。
然而,人们不禁要问,OpenAI 为何会耗费如此漫长的时间呢?这个问题引人深思。或许,在追求卓越与创新的道路上,每一步都需要精心考量和反复打磨,这正是 OpenAI 一直以来所坚持的原则。时间的沉淀,往往能孕育出更为惊艳的成果。
Godement指出,这实际上是一个关于“优先级设定”的议题。
以往,OpenAI 的研究重心始终围绕着如 GPT-4 这般的庞然大物。然而,伴随着时光流转,他们逐渐洞察到开发者群体对于小型模型的热切期盼。正是这份认知,促使 OpenAI 转变策略,毅然决然地将资源倾注于满足这一需求之上。
我们深信,GPT-4o mini 必然会备受青睐。
规模定律引发竞争,小型模型也不例外。
清晨时分,OpenAI 推出了精简版的 GPT-4o mini,与此同时,Mistral 与英伟达合作发布了一款120亿参数的小型模型 Nemo,其性能表现超越了 Gema 和 Llama-3 的80亿参数版本。
Karpathy 指出,当前的趋势是大型模型的参数量持续攀升,但其实质性的进步方向却在发生逆转。

当前大型语言模型之所以体积庞大,原因在于我们训练过程中的资源消耗极为奢侈——我们迫使它们将整个互联网的信息尽收眼底,而令人震惊的是,这些模型确实不负众望,能够复述出诸如常见数字的SHA哈希值,或是鲜为人知的生僻知识。实际上,在记忆能力上,大型模型的表现卓越,其精准度与持久性远超人类,往往只需一次学习,便能牢固掌握海量细节,并长久保持记忆鲜活。
这种现象揭示了大模型在信息存储上的惊人潜力,它们不仅能够记住广泛的数据,还能在需要时迅速检索并准确呈现。这背后的技术突破,让模型得以在处理复杂任务时展现出类人的智能,甚至在某些方面超越了人类的记忆极限。然而,这也引发了对资源效率和模型实用性的深入思考,促使研究者探索更加高效、精简的训练方法,以实现性能与成本之间的最佳平衡。
然而,试想一下,倘若你置身于一场闭卷考试中,被要求仅凭记忆复述出互联网上随机选取的一段文字,而这正是当前模型在预训练阶段所面临的挑战。问题的关键在于,训练数据中思维过程与知识内容错综复杂地交织在一起。这意味着,模型必须经历一个先扩张再精简的过程,其背后的原因在于我们需借助它们的力量,对原始训练材料进行重组和重塑,以达到理想的信息整合形态。
这种训练方法的核心在于,模型首先需要通过扩大规模来吸纳和理解复杂的思维与知识结构,随后再逐步优化和精简自身,以实现更高效、更精准的信息处理能力。这一过程不仅考验着模型的学习和适应能力,同时也揭示了在构建高级人工智能系统时,如何平衡规模与效率,以及如何有效整合多元信息的深层挑战。
这是一个逐步优化的进程,宛如层层递进的阶梯——每一阶段的模型都会为下一阶段的模型孕育出更为精炼的训练素材,直至我们构建出理想中的“完美数据集”。当这套数据集被用来滋养GPT-2,其结果将是一个在当今衡量标准下,展现出了非凡实力与智慧的模型。然而,或许在MMLU(多模态机器学习理解)的考验下,它的表现会略显逊色,原因在于它无法做到对所有化学知识的过目不忘,偶尔仍需借助外部资料来确保信息的精准无误。这种对准确性的追求,恰恰体现了它在知识掌握上的严谨态度。
本周,HuggingFace 的创始人宣称,「聚焦于小型模型的时代已经来临。」
OpenAI的研究员郑亨元强调,尽管团队对训练大型模型情有独钟,但他们同样精通于培养小型模型的技巧。这表明,无论模型大小,OpenAI都能游刃有余地进行训练。

人们对目前最顶尖的地表模型售价进行了综合整理:


以美国为例,假如你打算分析该国在24小时内所有对话中的每个词汇,这项浩大的工程其实只需不到两百万人民币的成本。当然,这仅仅是个估算值。


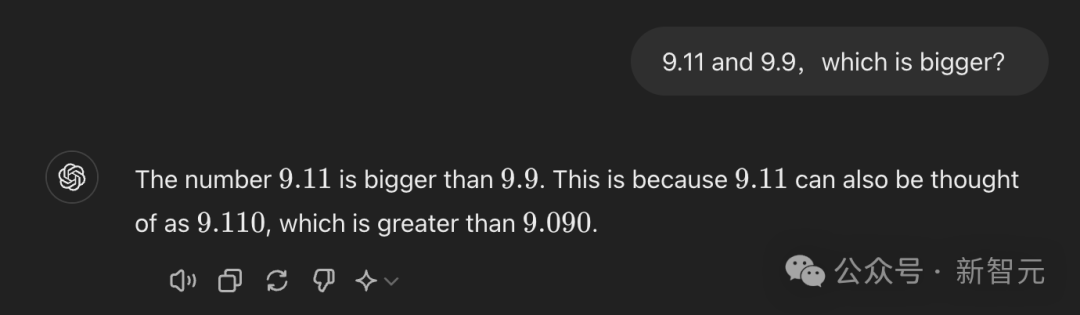
近期,一道引发热议的谜题——比较9.11与9.9的大小,即使是对GPT-4o迷你版的智能挑战,它也未能给出正确解答。这道看似简单的题目,却让进阶版的人工智能陷入了困惑。
日前,进化后的AutoGPT已正式启用,现可无缝对接GPT-4o mini,提供全面支持。

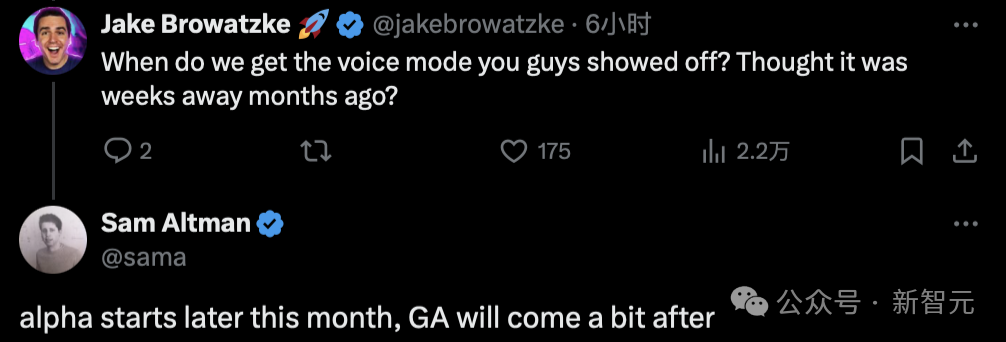
Altman在评论区透露,GPT-4的语音功能Alpha版预计将于本月底正式发布。
自然地,大众的热切期盼聚焦于GPT-5的问世。


在OpenAI的构想中,未来的模型将无痕地融入每个应用和网站之中。
如今,GPT-4o mini 的问世为开发者开辟了新的途径,使得构建和扩展功能强大的 AI 应用程序变得更加高效且成本效益更高。
我们目睹了人工智能正逐步变得愈发普及与稳定,悄然渗透进每个人的日常生活之中。在这个进程中,OpenAI 将持续扮演领航者的角色,推动 AI 技术不断向前发展。
GPT-4的作者列表之冗长,同样令人赞叹。
该项目的主管是陈米安娜。

陈米娜曾就读于普林斯顿大学,荣获学士学位。随后,在2020年,她在宾夕法尼亚大学的沃顿商学院深造,并取得了MBA学位。

在加入OpenAI之前,她于2015年踏入谷歌工作,大约历时三年。期间,她转投了一家初创企业Two Sigma,而后又重返DeepMind,担任产品主管超过一年。
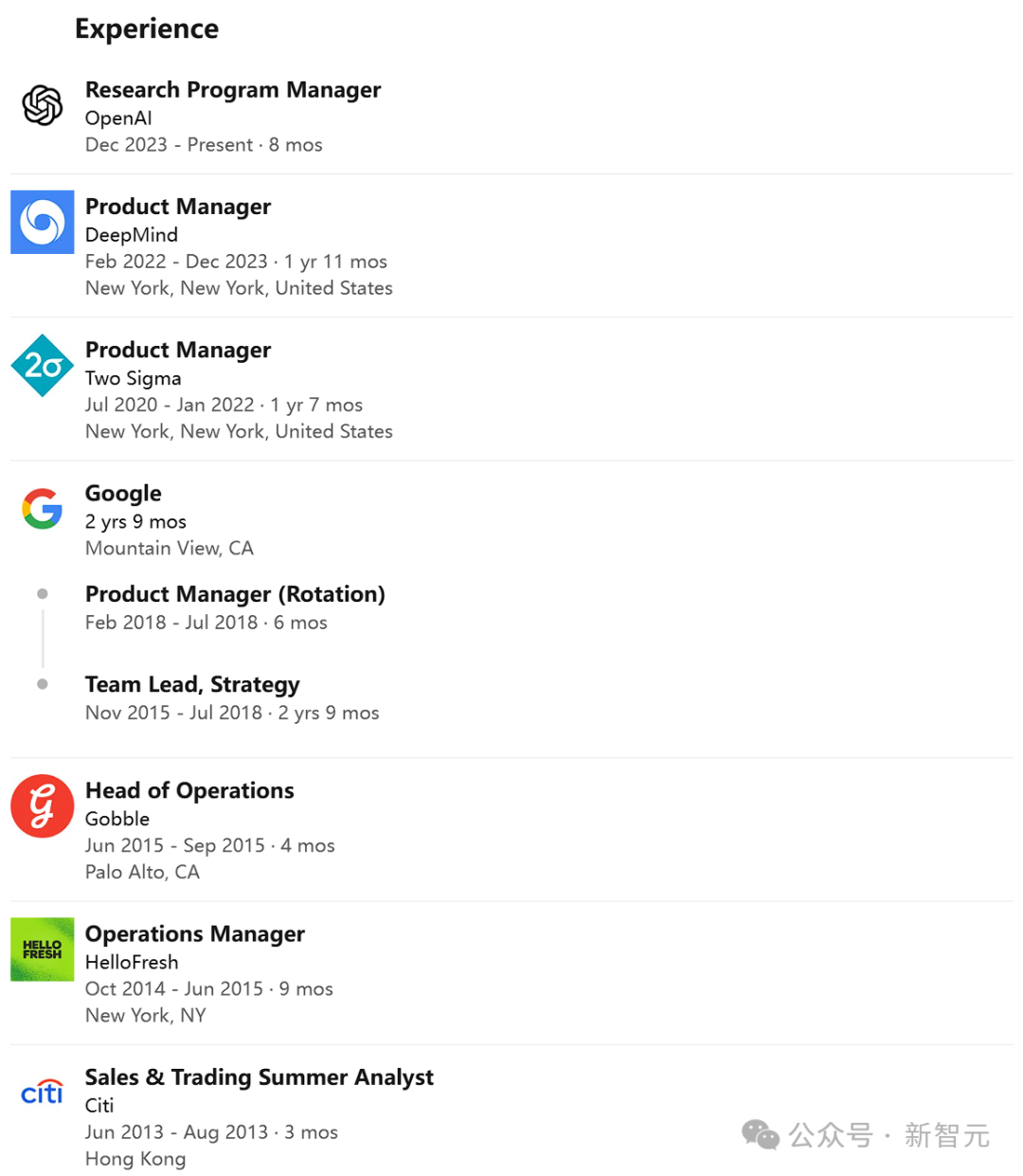
其他关键人物包括:Jacob Menick、Kevin Lu、郭盛佳(Shengjia Zhao)、Eric Wallace、任鸿宇(Hongyu Ren)、胡海堂(Haitang Hu)、Nick Stathas 以及 Felipe Petroski Such。这些人都是项目的核心成员。

Kevin Lu 拥有加州大学伯克利分校的电子工程及计算机科学学士学位,他曾与Pieter Abbeel及Igor Mordatch共同致力于强化学习和序列建模的研究。

在求学期间,他还有幸担任助教一职,并在伯克利的人工智能研究机构中出任本科生研究员。
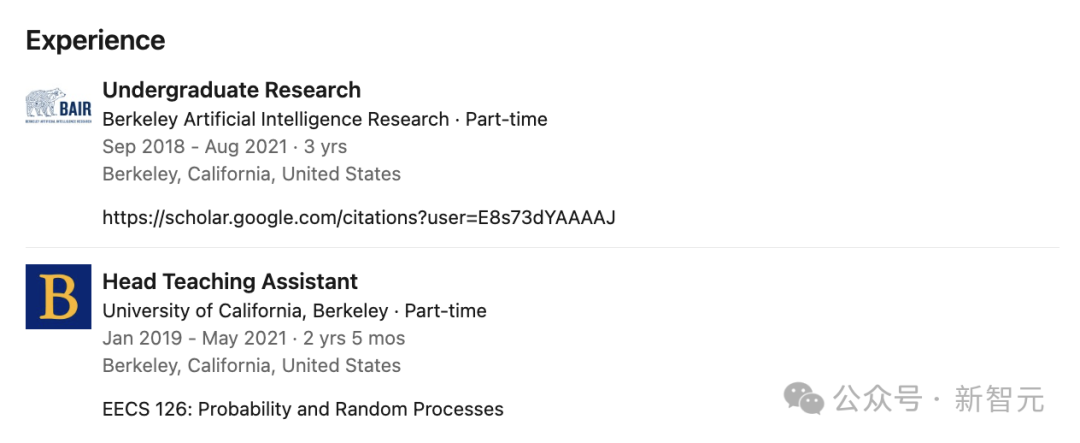
如今,他已加入OpenAI,担任研究员一职。

赵升佳,拥有斯坦福大学计算机科学博士学位,本科阶段在清华大学完成学业。

在取得博士学位后,Shengjia Zhao 立即投身于 OpenAI,成为了一名技术研究员,至今他已经在这个角色中积累了超过两年的经验。
目前,他的主要任务聚焦于大型语言模型的训练与优化,致力于ChatGPT的相关研发工作。

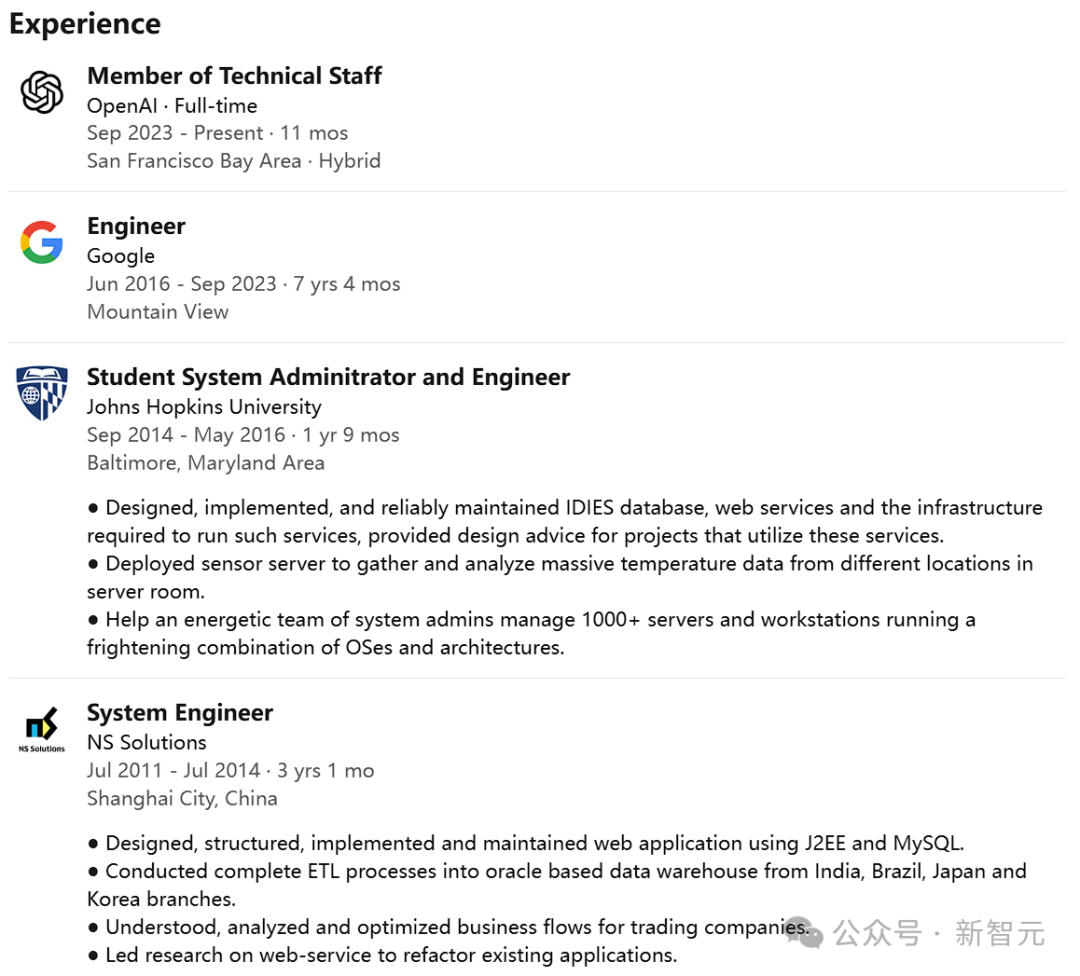
胡海棠先于同济大学修得计算机科学与技术的学士学位,后又在美国约翰·霍普金斯大学深造,最终获得计算机科学的硕士学位。
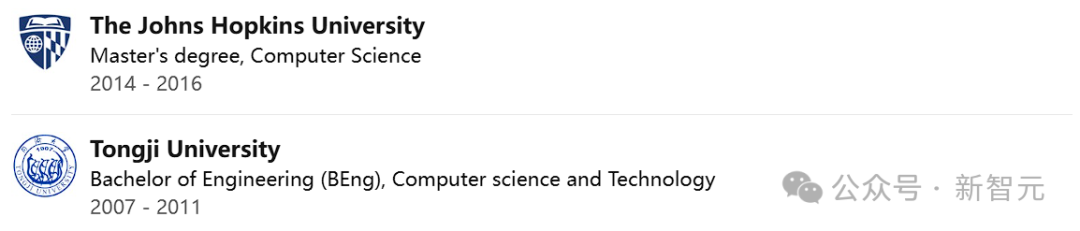
在他顺利完成本科学业后,便踏入了职场,成为了NS Solution公司的一员,在那里,他作为系统工程师勤勉工作了三年时光。接下来,为了进一步深造,他选择了前往享誉世界的霍普金斯约翰大学继续他的学业之旅。
在2016年荣获硕士学位之后,胡海堂随即踏入谷歌的大门,担任工程师一职长达七载。直至2023年9月,他迈出了职业生涯的新步伐,正式成为OpenAI的一员。
大家在看