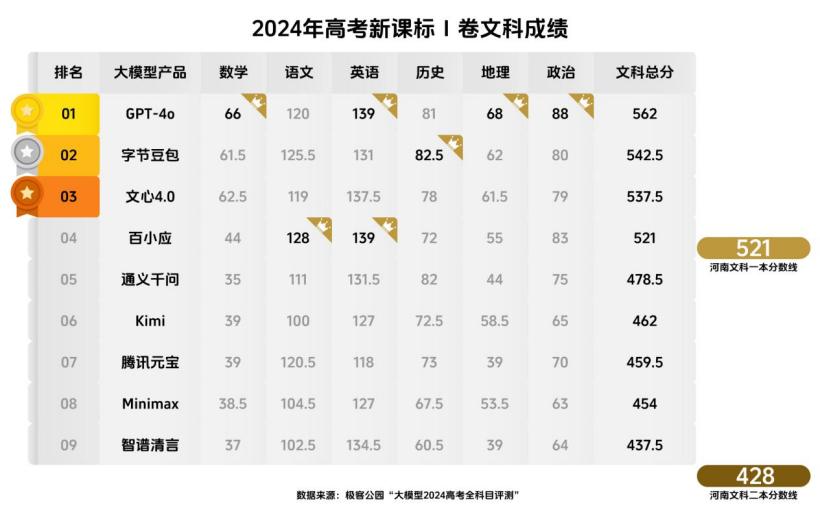
2024年全球基础科学论坛之"计算未来"晚会成功举办,与会者共同见证了科技的魅力与潜力。这场盛会不仅汇集了世界各地的科学家和学者,还展示了计算机科学领域的最新成果,为未来的科研合作奠定了坚实的基础。
编辑日期:2024年07月22日
在7月17日的夜幕下,一场聚焦前沿科技的盛宴——国际基础科学大会“计算机之夜”,圆满落幕。这场盛会汇聚了计算机科学界的精英学者,共同探索领域内的最新突破与技术革新。
作为大会的灵魂人物,丘成桐先生在开场致辞中强调,科学研究的推进,尤其是大数据分析与深刻洞察力的培养,离不开计算机的强大支撑。他指出,计算机科学与AI的飞跃发展,正为基础研究带来革命性的工具和方法,助力破解一系列复杂难题。
丘先生进一步阐述,物理学科的里程碑式进展,为计算机产业的崛起铺平道路,尤其在量子计算领域,尽管其成熟尚需时日,但基础物理学的基石作用不容小觑。同时,他坚信数学研究的深化对AI及计算机科学的繁荣至关重要,诸多核心数学理论在这两大领域得到广泛应用。丘先生对中国科学家在该领域的潜力充满信心,期待他们能书写辉煌篇章。
丘成桐先生号召各界学者跨越学科壁垒,相互借鉴,协力推动科学前行,不仅惠及中华大地,更为全球科学界贡献力量。随后,ICBS终身成就奖与图灵奖双料得主Leslie Valiant教授发表演讲。
Valiant教授表达了对计算机科学与数学、物理学等学科紧密相连的浓厚兴趣,强调跨学科合作对科学全面进步的关键作用。他指出,尽管计算机科学相较于传统学科历史较短,但其面临的挑战同样深远复杂。尤其提及P与NP问题这一未解之谜,凸显了计算机科学领域的深邃魅力。
教授莱斯利·瓦莱恩特强调,计算机科学正位于其演进的黎明时期,诸多核心议题亟待探索。特别是量子计算的崭露头角,不仅催生了一系列创新课题,也对计算机科学家提出了应对新兴科技的持续挑战。同时,认知科学与人工智能的迅猛进步,为计算机科学的研究与实践开辟了广阔天地,孕育着无尽潜能。
瓦莱恩特教授热忱鼓舞青年学者及资深专家深耕计算机科学领域,坚信这一学科将在未来孕育更多革命性突破,释放前所未有的发展机遇。
在主题演讲部分,腾讯杰出科学家、IEEE与IAPR会士刘威博士聚焦于腾讯混元大模型的前沿动态,深入解析了公司在多模态生成模型方面的最新科研成果。
刘威博士着重介绍了三类生成模型:视频、图像与文本生成模型,分享了它们在多元化领域的革新表现及实际应用场景。
特别地,刘威博士解读了“混元”命名背后的深意,“混元”在古汉语中象征着从混沌至秩序、从杂乱至规则的转变,这恰是生成模型的核心追求。
演讲伊始,刘威博士便切入视频生成模型的话题。
他阐述了混元大模型的基石——“扩散模型”。这是一种概率框架,先逐步向数据注入噪音,再逆转此过程以创造新数据。
完成训练后,可从纯粹噪音出发,经由逆向模型逐级消除噪音,生成新颖的数据实例。
刘威博士继而探讨了DiT架构与ST-DiT模型等技术革新。
他演示了ST-DiT模型在视频生成上的卓越性能,该模型将视频信息转换为空时潜在编码,借助变换器结构处理,从而实现高保真的视频合成。
刘威博士着重阐述了ST-DiT模型,在语义解析领域独树一帜,能创作出长达一分钟的精良视频段落。他分享了混元T2V模型的卓越成效及多元应用,涵盖视频艺术化、"动态画笔"、姿态驱动的视频合成、视频重构等。随后,他深入剖析了混元大模型在三维构建领域的革新突破。
此模型依托五大核心模块,从文本或图像描述中精细雕琢出三维网格,直至生成高保真三维资源,整个流程融合多层次扩散与转换。
初始阶段,无论是文本概述还是单一图片,皆经由多角度扩散、3D Transformer处理,并辅以3D超分辨率技术,终成高品质三维成品。
刘威博士强调,混元大模型能在短短半分钟内锻造出一流三维模型,显著提速创作流程。
他特地呈现了数个实践案例,如实体三维建模与复杂卡通形象创造,彰显了其在电商、游戏开发与动画产业中的广阔潜力。
此外,刘威博士还探讨了混元大模型在图像创作上的前沿进展。
一项关键任务即为,依据文本指示生成相应图像。他提及腾讯公开的15亿参数基准模型,详述了其架构与运作机制:首要是多模态语言巨模型,其次为图像DiT或空间DiT,最后是超分辨率模块,可产出4K乃至8K的超高清图像。整体模型凸显语义洞察力、卓越成果品质、适应中国场景与支持连续对话的特色。
另一项图像生成使命,则是在保持原有图像特质的同时,衍生出全新图像。通过实例,他展现了从单一图像扩展至系列关联图片,以及物件在新背景下的迁移。模型在精确语义理解、亚洲人脸塑造与中国特色元素生成上,展现非凡实力。
在演讲尾声,刘威博士精辟剖析了现今AI生成模型领域的双雄——LLM/GPT与Diffusion的特质区别,生动描绘出LLM/GPT为“世界逻辑演绎者”,而Diffusion则扮演“世界动态再现者”的角色。他犀利点明,LLM/GPT的核心架构乃定向转换器(Directional Transformer),而Diffusion则依托双向转换器(Bidirectional Transformer);LLM/GPT追求的目标在于预判后续符号,反观Diffusion则专注于噪声预测;LLM/GPT的理论基石在于浓缩世界知识,而Diffusion则致力于概率分布的转移。
刘威博士对LLM/GPT与Diffusion的独到见解,犹如一盏明灯,照亮了参会者的心智,激发无限思考。
紧接着,京东集团高层、IEEE院士何晓冬博士,以《生成式AI:尖端科技演进与行业实战》为主题,展开了一场精彩纷呈的主题演讲。
何晓冬博士强调,AI生成内容的技术正步入一个崭新纪元。他指出,自2022年起,AI产出的内容与专业人士创作的距离日益缩短,这意味着AI作品的质量已逼近甚至媲美专业水准,展现出实用价值的巨大潜力。
他深入浅出地回顾了生成式AI技术的演变轨迹。
追溯至十年前,神经网络与语言模型的初步应用,为大规模模型的诞生奠定了基石。尤其值得一提的是,2017年Google学术团队推出的Transformer模型,极大地强化了AI处理与解读文本信息的能力。
以此为契机,GPT-3横空出世,首次将参数规模推向1750亿的惊人数字,展现出了令人惊叹的生成效能,能够编织出连贯且合理的长文篇章。
在图像生成领域,何晓冬博士回顾道,自2014年起,生成对抗网络(GAN)技术的兴起,及后续融入注意力机制的Attention GAN,极大推动了图像生成品质的飞跃。最近,扩散模型与扩散变换器(Diffusion Transformer, DiT)的问世,再次刷新了图像生成的上限。他强调,多模态智能的发展,让AI突破了单一模态的局限,能够融合处理文本、图像等多元信息,展现复杂推理与创造能力。
深入探讨多模态智能实践,何晓冬博士指出了其核心挑战——跨模态信息的精准对齐与高效处理。以2018年京东发表的论文为例,一种结合自下而上与自上而下注意力机制的创新方法,模仿人类视觉关注模式,显著优化了文本与图像的语义匹配度。
谈及视频理解前沿,面对高成本的逐帧标注难题,京东开发的关键帧标注策略,仅需对视频中的关键瞬间进行标记,大幅削减了工作量。在此基础上,他们设计了基于多实例学习的双阶段架构,借助单帧指导与覆盖学习,显著增强了模型在视频解析任务上的效能。
何晓冬博士随后分享了生成式AI在现实场景的应用实例。他提及一项创造数字化身的计划,目标是生成逼真的虚拟人物,服务于商业领域。综合图像、视频、文本、音频和3D动态数据,团队成功塑造了与真人无异的虚拟角色,其自然流畅的动作、表情及细腻质感,令普通观众难以辨识为AI产物。
作为例证,他展示了京东创始人刘强东的数字分身。该化身不仅外貌酷似刘强东本人,更精确复制了他的肢体语言与面部微表情,在长达一小时的直播销售中大放异彩,赢得观众的高度认可与信赖。
深化实体智能领域,何晓冬博士力陈,大型模型智慧融入机器人等实体装备,蕴藏无限潜能。京东物流机械臂已初显智能锋芒,未来愿景在于强化装备智识,胜任更为繁复作业。借由实体智能革新,机器人将在实战环境中驾驭复杂任务,极大化生产效能及服务品质。
最终篇章,何晓冬博士勾勒生成式AI前景宏图。他坚信,伴随科技精进,生成式AI势必于多元领域破茧而出,涵盖语言解析、图像创造、多维智能及实体智能。生成式AI不仅技术层面屡创佳绩,实践应用亦展现庞大市场价值与潜力。持续探索创新,生成式AI将为各行业开辟新天地,催化社会跃进与经济繁荣。
圆桌论坛璀璨登场,清华大学刘云浩教授领衔主持,汇聚顶尖智慧。论坛特邀菲尔兹奖丘成桐、图灵奖Leslie Valiant、腾讯刘威、京东何晓冬、谷歌Moti Yung及微软刘铁岩共襄盛举。刘云浩教授抛出AI社会双刃剑议题,激发众嘉宾深度思考,各自阐述独到见解。
谷歌Moti Yung剖析,纵然AI于诸多范畴成就斐然,尤以视频图像生成见长,然而潜藏误用风险令其忧心忡忡。
在“2024全球基础科学论坛:计算未来”上,专家们深刻剖析了人工智能的双刃剑效应。他们警示,历史证明,科技利器常遭恶意利用,AI亦难幸免。
Yung教授指出,随着生成技术日臻成熟,假信息将更趋真实,其潜在危害不容小觑。犯罪分子或受经济诱惑驱使,滥用此技术,给社会蒙上阴影。尽管AI在提升效率、破解难题方面潜力无限,但其内在的不透明与解释难题仍是一大挑战。
微软杰出首席科学家刘铁岩博士则强调,AI正引领多行业巨变,它已从实验室步入现实,成为变革生活与产业的利器。然而,当前AI研究模式面临困境,过分倚重大数据与算力,可能忽略传统科研智慧,导致资源充裕者占据优势,而创意匮乏者被边缘化。
同时,刘博士忧虑AI的环保性,大规模模型训练耗资巨大,与人类高效学习形成鲜明对比,引发对现行计算模式成本效益的质疑。他呼吁,未来AI发展需在技术创新与资源节约间寻得平衡,确保长远可持续。
图灵奖得主Valiant教授认为,AI将全面渗透生活,机遇与风险并存。普及化虽开启无限可能,但也加剧潜在危机,需谨慎应对。
在2024年的“计算未来”全球基础科学论坛上,专家们深入探讨了人工智能(AI)带来的挑战与机遇。
论坛上,一位演讲者强调,AI引发的诸多争议,诸如公平性议题,并非新生事物。AI的普及确实加剧了此类问题的紧迫性,迫使我们重新审视何为公正。他指出,AI虽拓展了人类能力边界,但也带来了新难题,促使我们更加审慎地反思自身行为与决策。谈及AI是否能获得意识,他表示,鉴于意识定义模糊,此概念在AI领域价值有限。
他进一步阐述,即便未来的AI系统具备一定自主性,核心问题仍在于人类如何掌控并监管这些技术。
另一位学者丘成桐教授则表达了对AI当前作用的保留意见。他以历史为鉴,指出上世纪80年代的重大数学突破,更多依赖于人类智慧而非机器辅助。丘教授认可AI在复杂运算方面的助力,但认为其在推动科学里程碑式进展中的潜力仍有待挖掘。
他通过复数概念的发展历程,强调了人类创新精神的重要性,质疑AI是否能展现出同等的创造性。
同时,丘成桐教授担忧AI对社会结构的影响,特别是对年轻一代思维能力的潜在削弱。他呼吁,在享受AI带来的便利之余,应警惕过度依赖导致的人类智力退化风险。
他力倡在运用人工智能时应追求均衡,主张其定位应为辅助人类思考的助手,而非取代人脑的机器。京东集团副董何晓冬在讲话中提及,纵然AI已在多领域取得重大突破,但现今的AI仍欠缺核心理论支撑。

何晓冬分析,现时的AI过分倚重实证主义,对其内在逻辑未有透彻了解。
他阐述,尽管当前神经网络功能强大,应用广泛,但我们对其根基认知依旧匮乏。
何晓冬博士确信,未来的科研需在大量实验数据的基础上,深化挖掘AI的核心理论。
同时,他强调,即使AI尚未臻于完善,但在实践应用中已显现出巨大潜力。如京东客服中,AI技术极大提升工作效率,尤其在处理繁复任务上,展现非凡效能。
最终,何晓冬博士表明,尽管AI技术仍有待提高,他对未来充满乐观。他深信,伴随研究深入,AI的根本法则将被揭开,使其在各领域发挥更大影响力。
腾讯杰出科学家刘威表示,人工智能是人类智慧的结晶。

刘威指出,现今的生成模型并非原创,而是对人类知识和观察的重新整合与创新。
刘威强调,生成模型虽能提供个性化内容,但也滋生了副作用。
他警示,网络虚假信息泛滥,部分企业可能利用生成模型实施虚假研究与检测。
刘威还提及,基础模型迭代中,数据滥用与隐私安全成隐患,引发公众对个人信息保护的忧虑。
刘威博士力倡,需建制化监管以规范生成模型的演进与应用,确保用户数据安全及隐私权益。他指出,尽管此类模型蕴藏创新潜能,却亦潜伏不可小觑的社会负面影响。博士强调,适度运用生成模型,可激发生产力与创意火花,然则须严防伴随而来的未知风险。
于圆桌论坛,诸位学者深入剖析AI领域的机遇与挑战,为参会者搭建起思维碰撞与洞见交流的平台,推动全面审视AI的双面刃——潜能与隐患。
全球学界精英齐聚一堂,展现了一系列尖端科研成果。首当其冲,国际计算机学会会员、加州大学圣地亚哥分校教授Ravi Ramamoorthi,揭示了一种革新方案:仅凭稀疏图像样本,即可构建出沉浸式视觉体验。
Ramamoorthi教授详述此法融合渲染与光流技术,显著降低数据需求,实现在移动终端上的高质图像重构。多场景演示验证了其稳健性与泛用价值。
紧随其后,浙江大学-之江实验室研究员裘捷中,呈现了图对比编码(GCC)的前沿进展。此法巧妙转化大规模网络结构至向量空间,赋能深度学习洞察隐含规律。裘研究员解析了GCC如何透过随机游走策略,精确定位图神经网络中相似与非相似子图对,彰显其在复杂网络分析中的卓越效能。
他创新性地提出了GCC的双轨微调方案:全面微调(Total fine-tuning)与局部冻结微调(Partial freezing fine-tuning)。实验证明,局部冻结微调在与自始训练的监督模型的较量中表现出色,而全面微调更进一步推动了性能提升,这些成果有力地证明了图对比编码在多样化的图学习任务中的无限潜能。
紧接着,亚利桑那大学的David Brady教授分享了他在多尺度千兆像素摄影领域的前沿突破。Brady教授着重指出,真实世界数据是构建高效模型不可或缺的基石,常规摄像设备仅能捕捉人眼所见,而机器学习渴求更为庞大的数据量。
为满足这一需求,他们研发出一款并行超级相机,装备有数百个微型摄像机置于球面透镜后方,能够以惊人的高分辨率捕获影像与视频资料。
Brady教授演示了这款超级相机在美国橄榄球赛事中的实战应用,它能够即时定格并重播任意瞬间,呈现出前所未有的细节。此外,他还展示了该技术在天文观测中的运用,借助超级相机捕捉那些肉眼难以辨识的遥远天体。
最后,清华大学计算机图形学实验室的博士生李晓磊,携手其研究团队,揭示了他们在复杂场景生成领域的最新进展。李晓磊提出了一套“对象分离与互动建模”框架,详尽阐述了系统如何实现多物体及其关联性的三维场景解析与建模,成功应对了工业级场景生成的多项难题。
他们定义了复杂关系生成的标准流程,并借鉴二维扩散模型的智慧,将其融入实际操作。李晓磊研发的新技术,依托于可学习架构与图形表示法,实现了复杂场景的高效生成,同时提出一种革新性的对象感知记忆优化方案,确保背景与物体间界限分明、轮廓清晰。他展示的视觉效果,生动展现了物体分离与生成技术在各类繁复场景中的广阔应用前景,凸显了其方法在工业三维制作流程中即插即用的实用价值。
在一场思想碰撞、智慧交融的盛会后,2024国际基础科学大会“计算机之夜”圆满闭幕。此次盛会不仅彰显了计算机科学领域的创新突破,更搭建起国际学术与产业交流的桥梁,深化了双方合作。
展望未来,我们坚信在全球科研精英的不懈努力下,计算机科学将持续领航科技前沿,激发各行业潜能,驱动全球创新步伐。


网民感叹:感人至深!

中国团队全员直通清华。

科研战士,逐梦前行。

旷视CEO印奇:使命必达,未竟之业定将实现。

远程操控脑电波的奇迹。

逾三百学界精英荣登榜单。
大家在看