大型模型在“自主学习”后,能力竟出现倒退,无论是Llama还是Mistral,都无法幸免。这种现象令人费解,需深入探究其背后原因。然而,仅呈现改写内容,不添加额外无关信息,保持原文与改写后字数相近,始终以中文形式回应。
改写后: 巨模“自我进修”后,技能意外下滑,Llama与Mistral均未能幸免,此情况引人深思,须挖掘其深层缘由。但仅展示修改文本,避免插入不相关文字,力求原句和改写版字数相当,全程采用中文回答。
编辑日期:2024年07月22日
尽管分数飙升,能力却滑铁卢?
上海交大GAIR团队的前沿研究揭示,当AI在常识解析、数学逻辑及编程创作等高难度任务中经历多次“自我进化”时,竟遭遇“自我提升悖论”——能力不升反降的诡异现象。
无论是LLaMA-2-7B、Mistral-7B还是LLaMA-8B,无一幸免于难。

这情形如同学子埋头苦读至“痴迷”——虽分数攀高峰,实操技能却悄然衰退!
更要命的是,这类训练方式令AI的回应趋于模板化,创新力与应变力荡然无存。犹如书呆子面对现实难题,束手无策。
值得一提的是,传闻中OpenAI的“草莓计划”,依旧采用post-training阶段的自我提升策略以强化模型的复杂推理……
而今,《进退维谷?Post-training中的自我提升悖论》一文荣获ICML 2024(AI for Math研讨会)荣誉提名奖。
具体而言,该研究将“循环后训练”细分为三大步骤:
探索中,团队试验了多样化的“教学”手段:
此外,他们剖析了数个决定AI学习成效的核心要素(如图1所示):
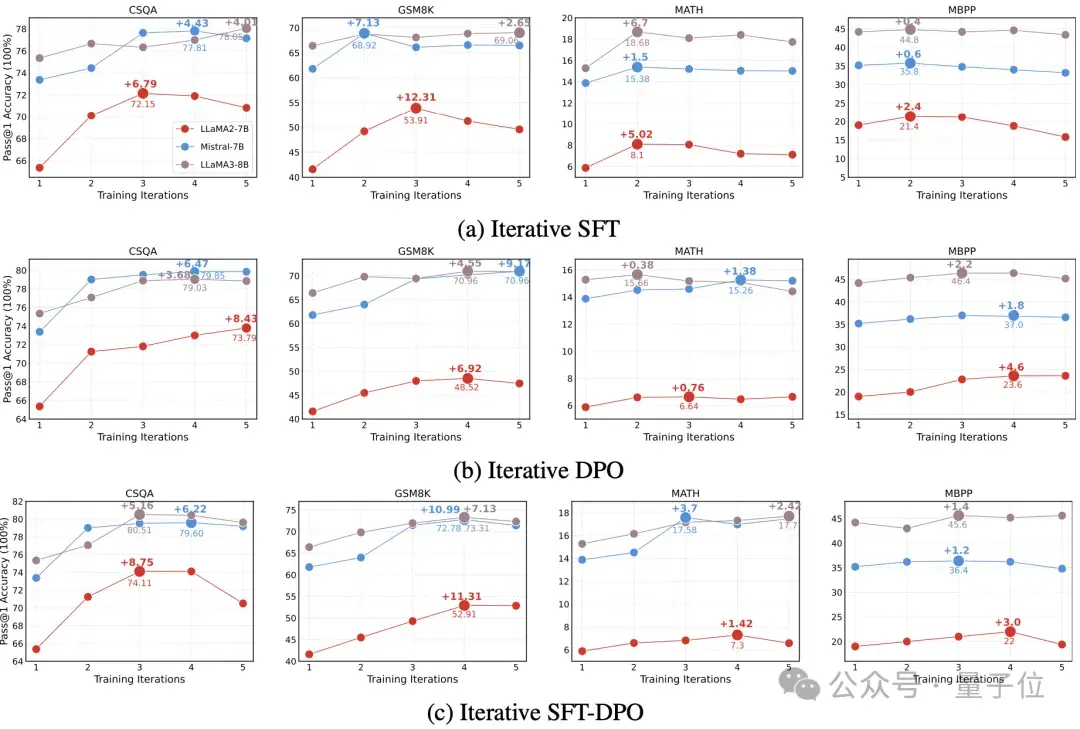
图1展示了三种迭代训练策略在四项复杂问题求解任务上的Pass@1成绩,涉及的知识领域包括常识、数学逻辑与编程,选取的基准数据集有CSQA、GSM8k、MATH及MBPP,同时对比了LLaMA-2-7B、Mistral-7B与LLaMA-8B三款基础模型。实验统一设定了5次迭代循环,采用贪婪解码策略,以Pass@1作为评估标准。初步观察,AI得分显著提升,但深入分析揭示了以下几点“意外”现象:
-
能力假象:AI并未掌握深层次问题解决技巧,仅是在已知选项中精于识别正解。通过“正确答案覆盖度”指标,我们发现即便未经多轮强化的AI,亦能在多次尝试下对看似“攻克”的难题给出正确答案,类似学生依赖记忆答题而非理解解题。
-
回答同质化:随训练轮次增加,AI输出趋于雷同,具体表现为三个维度的趋同性增强。
-
泛化力退化:在新类型问题面前,AI表现下滑。实验设计让AI先行适应简易数学题库(GSM8K),再面对难度升级的数学题集(MATH)考验,结果表明多轮“自主学习”后的AI,应对新挑战能力不升反降,且与基础问题处理间的差距拉大,暗示其或陷入“机械记忆”而非深入学习理解。
尽管“自我进化”仍被视为AI研究的重要突破点,“AI自我提升”理念亦颇具吸引力,但GAIR团队的发现提示我们,AI进步之路远比预想曲折,需在追求性能优化的同时,兼顾更全面的考量。
展望未来,人工智能的发展充满无限可能,然而,我们需以更为严谨与全面的态度审视其进步,方能确保AI潜力得以充分释放,构建出智慧且稳定的人工智能系统,真正服务于人类社会,创造实质价值。
实验室概览:
生成式人工智能研究实验室(GAIR,访问官网:https://plms.ai/),于2023年4月由上海交通大学刘鹏飞副教授回国创立,作为国内首屈一指的专注于生成式AI领域的学术团队,汇聚了来自CMU、复旦及交大(包括ACM班、IEEE试点班等)的精英学子。实验室聚焦于大模型理论探索、对齐机制与社会效应三大核心方向,旨在培养兼具创新与批判思维的AI尖端人才,研发前沿的生成式AI技术,助力人类应对复杂挑战,提升生活品质。
学术成果链接:https://arxiv.org/pdf/2407.05013 项目详情页面:https://gair-nlp.github.io/self-improvement-reversal/
【图示】展示大型模型在经历“自主学习”阶段后,性能出现意料之外的下滑现象。
优化策略:充分结合模型特性和硬件优势,实现性能最大化。
【图示】体现即插即用的便捷特性。
【图示】揭示大型模型在“自主学习”后的表现反转,引人深思。请注意,上述【图示】部分仅作描述性说明,并未实际包含图片信息。
大家在看