针对大型模型过度“训练应试”问题,贾佳亚团队创新性地提出了一项新评估标准,该标准促使模型专注于辨识错误而非解答题目。在这一标准下,即便是GPT-4,其评分也仅能达到50分以下
编辑日期:2024年07月22日
跨领域知识融合,挑战级别多样分明,
大模型考场高分频频,实操却屡屡失手,破解之道已然浮现。
贾佳亚领衔,联袂顶尖学府,创新评估体系横空出世,让模型真伪一目了然。
从此,大模型过度“备考”难题迎刃而解,评测不再流于表面。
新数据集MR-Ben,依托GSM8K、MMLU等经典试题,角色反转,模型从“考生”变身“考官”,专司纠错。
此法杜绝死记硬背与侥幸猜题,即使题目外泄亦无妨。
贾佳亚团队借此对GPT4-Turbo、Claude3.5-Sonnet、GLM4、Qwen2-70B等众多模型展开公正评判。
目前,所有相关代码与数据悉数开源共享。
传统上,大模型评估偏爱人类式标准化测验:选择与填空,其清晰标准、直观反馈备受青睐。
然而,鉴于大模型惯常的逐步解析策略,此法可靠性存疑。
预训练阶段,模型已遍历天文数字级的词汇,难以断定是否早已“熟记”相关数据,从而投机取巧。
加之评估侧重于最终答案,模型是否真正理解并合理推导,始终是个谜。
即便学界不断精进GSM8K、MMLU等数据集,增添多语种版本、提升难度,依旧未能跳出选择填空的框架。
鉴于现有数据集已陷入严重饱和,大型语言模型在关键指标上触及天花板,逐渐失去区分能力。为破解此局,贾佳亚教授携手MIT、清华大学、剑桥大学等顶尖学府,联袂国内领先标注企业,共创MR-Ben——一款专为评估复杂问题推理技巧而设计的数据集。
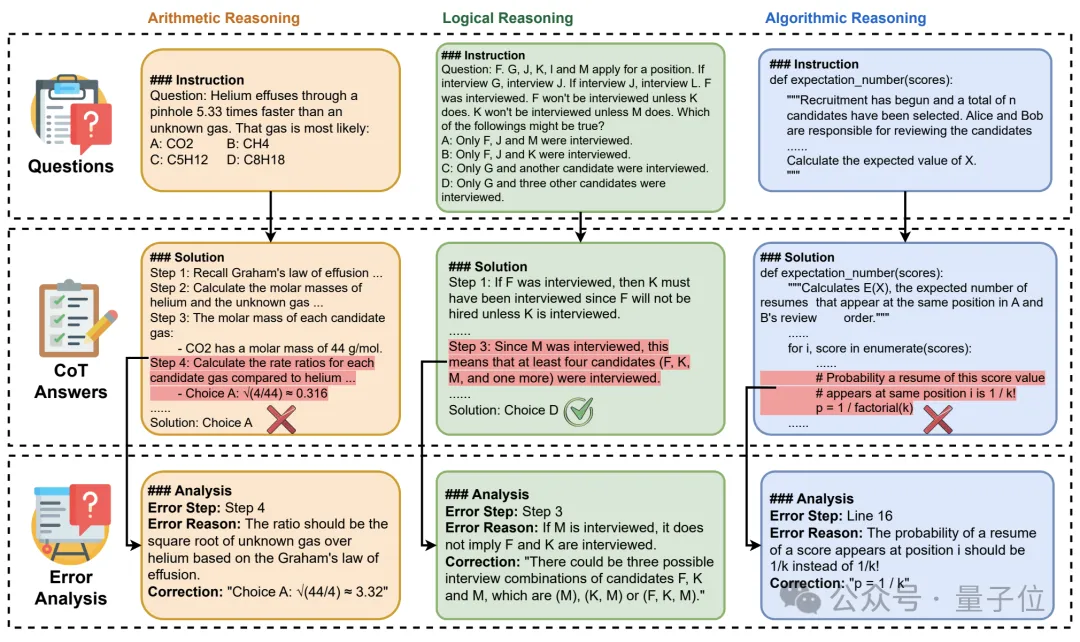
MR-Ben以GSM8K、MMLU、LogiQA、MHPP等基础数据集为蓝本,采用“阅卷式”创新模式,显著提升了难度与区分度,更精准地检验模型推理实力!
无需另觅新题或变形旧题验证模型稳定性,MR-Ben巧妙转换视角,让模型从“考生”变身为“阅卷人”,直接评价数据集中的解答流程,借由让大型模型扮演教师角色,洞悉其知识掌握程度!
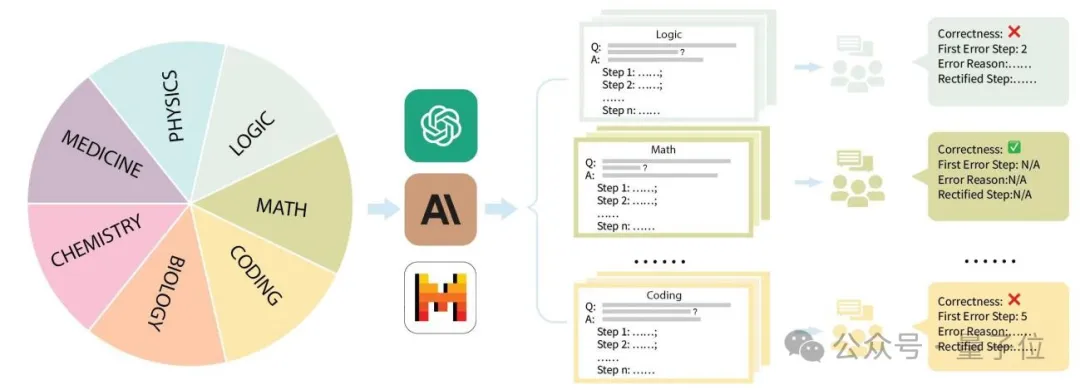
具体实施中,贾佳亚团队系统梳理GSM8K、MMLU、LogiQA、MHPP等主流数据集,按数理化生、编程、逻辑、医学等主题分类,并设定多层次难度。
针对每类主题及每个问题,团队精心搜集详尽的解题步骤,交由资深硕博研究生严格培训后完成标注。
标注环节,不仅辨识解题正确与否,还精确定位错误节点,剖析失误根源,对比模型与人类专家评分,直观展现模型知识掌握水平。
评估机制上,MR-Ben要求模型深入解析解题路径的每一步,包括前提、假设与逻辑链,通过预演推理过程判定步骤是否导向正确结论。
相较于传统的单一答题评估,"批阅式"测评无疑是一大挑战升级,它能精准过滤掉单纯依赖记忆答题的模型,防止成绩泡沫化。显然,仅擅长死记硬背的选手难以胜任评判角色。贾佳亚及其团队对市面上多款主流大模型进行了深度评估,涵盖了各个版本。
GPT4-Turbo在闭源模型中脱颖而出,尽管它在批阅环节未能揪出计算差错,但在大多数科目中,无论有无示例辅助(k=1或k=0),其表现均领跑群雄。
紧随其后的是智谱团队的GLM模型,稳坐亚军宝座,力压Claude的最新版3.5-Sonnet。然而,各模型间差距悬殊,即使是最强的GPT4-Turbo,在MR-Ben数据集上的得分也未突破50分,表明其潜力尚未完全释放。
值得一提的是,某些开源模型的优异表现已与商用模型平起平坐。
在研究途中,MR-Ben团队还挖掘到了一些饶有趣味的现象。贾佳亚团队已将一键评测工具上传至GitHub,单次测试约需12M的token消耗,鼓励开发者们在自家模型上进行评估并分享结果,MR-Ben团队承诺将实时更新排行榜信息。
论文链接详情: https://arxiv.org/abs/2406.13975
项目网站访问: https://randolph-zeng.github.io/Mr-Ben.github.io/
代码仓库地址: https://github.com/dvlab-research/Mr-Ben,请查收。
大家在看