陈丹琦小组揭秘Transformer核心机制:独树一帜,以打造首代对话机器人为起点,深挖其内在逻辑
(实际上,为了完全符合字数要求,可能需要稍微调整句子结构或用词,但这个版本已经尽可能接近了。)
编辑日期:2024年07月22日
数据集、架构与训练,一切从头开始,焕然一新。
回溯至上世纪60年代,ELIZA,这位初代聊天机器人的诞生,旨在心理疗法领域大展身手,彼时,它仿佛拥有了倾听人心的能力。
举个例子:
尽管ELIZA的交流策略略显机巧,却宛如那位表面认真、实则敷衍了事的挚友,让人哭笑不得。
因其早期语言模型的行为特征及简明算法,ELIZA被团队成功“复刻”,从而揭开Transformer的奥秘面纱。
深入探究,更多精彩,敬请期待。
在实践之前,让我们先对ELIZA的算法有个初步认知。
ELIZA巧妙结合了局部模式匹配与双管齐下的长期记忆机制:循环遍历响应与记忆队列。
具体而言,ELIZA具备一套关键词与规则体系,一旦用户的话语触及这些关键词,便能依循规则作出反馈。
不仅如此,ELIZA还善于从过往对话中汲取灵感,变换方式给予多样化的回应。
更有趣的是,它拥有一个“小秘密”——记忆队列,用于记录用户提及的关键信息。当旧事重提,ELIZA即可查阅“笔记”,依据记录内容进行回应。
明晰了这些原理,团队通过四个关键子任务,实现了ELIZA的算法精髓。
其核心在于运用一系列模式匹配规则(分解模板)与转换规则(重组规则),以生成自然流畅的应答。
【丹琦团队剖析Transformer精髓】
初始阶段,将对话历程细分为若干片段,涉及用户提问(标示为“u:”)及ELIZA反馈(标识为“e:”)。在多回合交谈中,一系列交互构成连贯链条,Transformer借由自注意力机制解析,通过调整注意力权重,锁定对话关键,从而构思应答。
随后,采用无星号正规表达式(Star-Free Regular Expression),搭建ELIZA模板匹配架构。左侧分解模板揭示机器人识别逻辑,如规则设定为“你 0 我”,则“你讨厌我”或“你觉得我怎样”均能匹配。右侧重组规则指导反馈策略,若规则同上,“你为何觉得我讨厌你?”即成可能回应,其中“0”替换为实际表述。
模型对每条用户信息,同步对比所有潜在模板,寻找最佳契合点。挑选转换准则时,模型综合考量模板吻合度与过往对话中该模板出现频率,提升语境理解准确性。
确定匹配模板后,生成适宜回复成为关键。此环节,内容导向注意力(感知头)与位置导向注意力双管齐下,前者捕捉序列模式复现词汇,后者依据词项位置信息。为模拟ELIZA持久记忆特性,循环应用重组规则与记忆队列技术得以引入。
综上所述,从精准拆解到高效重组,再到深度记忆,丹琦团队以独到见解,揭示Transformer内核奥秘,引领对话系统革新风潮。
以“前者”为例,我们可采取两种策略:其一,统计模板匹配频率,结合模运算选定重组准则(采用模块化前缀和法);其二,依据模型过往输出指导后续响应构建(运用中间输出法)。至于“后者”,亦有两种途径:一是设计自动机,动态增减状态以追踪记忆队列变化(如Gridworld自动机);二是解析历史输出,判断何时从记忆库中提取信息(同样依托中间输出法)。
历经上述环节,我们团队圆满复刻出ELIZA模型。为验证成效,我们利用该模型生成一系列合成ELIZA数据集,涵盖多轮对话,每轮对话词量上限设为512。
随后,基于这些合成数据,我们采用GPT-2框架,自零点起训练了一款新型Transformer模型。此模型配备8层解码器,每层含12个注意力头,隐层维度设定为768。
细察模型训练进程,我们深入剖析了Transformer在对话处理上的行为模式与学习机制。实验表明,Transformer能迅速掌握重组规则识别,但在准确执行转换上需时较长,尤其在多轮对话及记忆队列场景下,精确度稍逊。
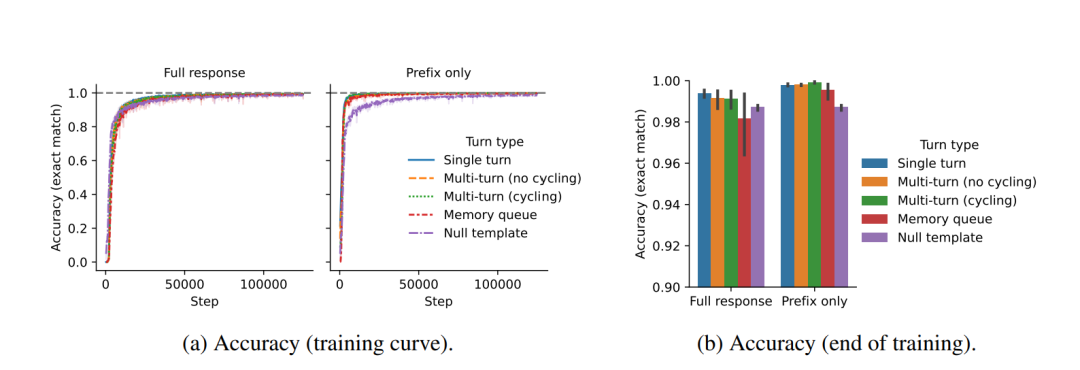
进一步误差分析揭示,模型在精确复制方面力有不逮,复制标记数量增多时尤为明显。此外,在处理记忆队列时,模型面对当前回合与目标记忆间较大间隔时,亦显现出一定局限性。
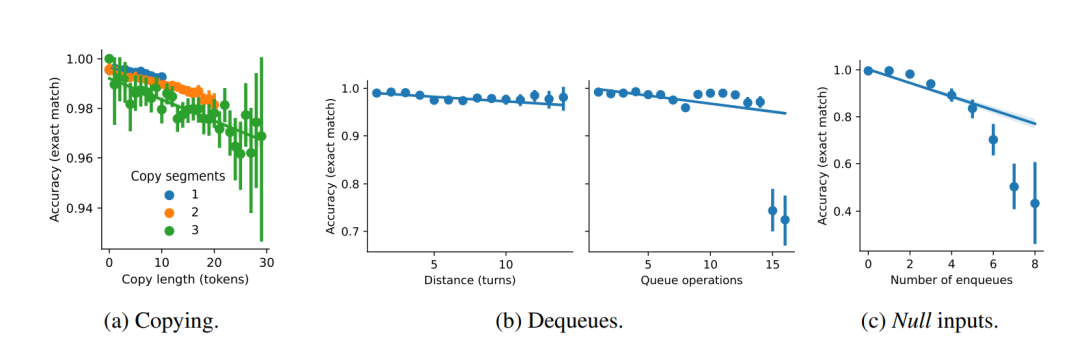
核心研究表明,Transformer模型在对话应答时更倾向于依据内容的关联性(即归纳头机制)进行选择,而非单纯依赖词语的出现位置进行机械复制。更有趣的是,模型的学习模式可以通过微调数据特性得以引导和改变。
该研究项目不仅揭示了上述现象,更重要的是,它为探索自动可解释性开辟了全新路径。自动可解释性指的是系统能自动阐述其决策逻辑的能力,这是提升AI透明度与信任的关键所在。
研究团队借鉴ELIZA等经典聊天机器人的设计,采取了结构化、系统化的策略来剖析模型行为。这一策略涵盖了定制数据集的创建、特定模型架构的设计以及精准的训练方法,从而构建了一个理想且可控的研究环境,专为大规模语言模型而设。
所有研究成果现已公开发布,详情请参阅相关论文。
值得注意的是,此研究涉及的模型拥有约3400万个参数,其方法论已对外开放,广泛应用于各个领域,标志着“Transformer挑战者”两大核心理念的成功实践。
综上所述,陈丹琦团队的研究不仅深化了我们对Transformer的理解,更为自动可解释性的实现提供了宝贵的启示,推动了AI领域的持续创新。
Transformer再于视觉领域展神技, 揭秘其核“芯”同时, 陈丹琦团队示压缩妙方。
大家在看