Reddit 据报阻挡了多个搜寻引擎及 AI 网路爬虫,官方表示此举与谷歌合作无关联。
编辑日期:2024年07月25日
最新消息显示,Reddit已禁止其他搜索引擎抓取其网站内容。此消息最先由404 Media报道。据报道,Reddit已更新其robots.txt文件(注:这是网站与网络爬虫之间的协议文件),以阻止所有机器人抓取网站上的任何内容。
查阅 Reddit 的 robots.txt 文件后发现,该平台声明“Reddit 支持开放的网络环境,却反对滥用公共内容。”其“Disallow”指令设定为“/”,意味着禁止爬取网站根目录下所有文件。
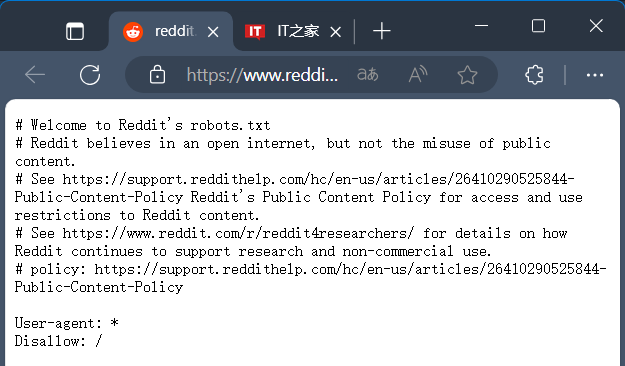
今年6月,该文件首度修订。Reddit表示,此举旨在应对商业实体对平台内容的大量抓取及滥用现象。
据9To5Google报道,Bing、DuckDuckGo、Mojeek及Qwant等搜索引擎出现异常。在使用“site:reddit.com”查询时,要么缺失新帖结果,要么显示不全,无法完整呈现网站内容。
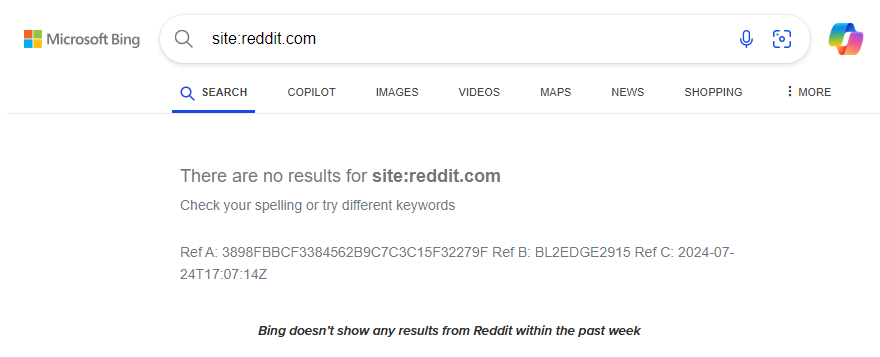
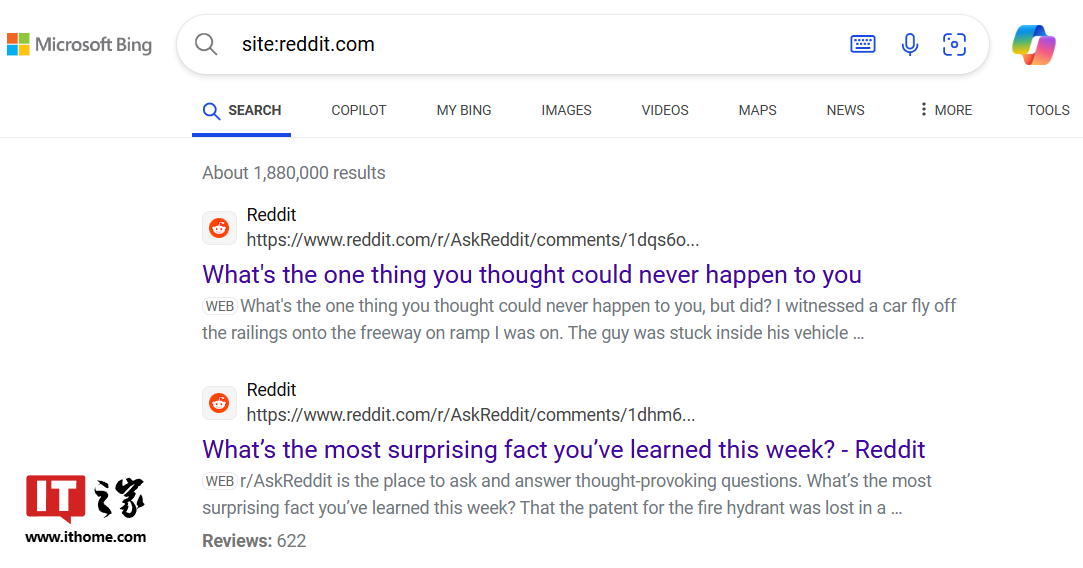
但在最近的测试中,Bing 和 DuckDuckGo 已恢复显示“site:reddit.com”的搜索结果。
Reddit 的发言人 Tim Rathschmidt 向 The Verge 表示:“此事与我们近期和谷歌的合作无关。我们持续与多家搜索引擎洽谈,但未能与所有达成共识。部分搜索引擎未能或不愿对其使用 Reddit 内容的行为(包括用于 AI 训练)做出可执行的承诺。”
大家在看

AI安装教程
AI本地安装教程

微软AI大模型通识教程
微软AI大模型通识教程

AI大模型入门教程
AI大模型入门教程

Python入门教程
Python入门教程

Python进阶教程
Python进阶教程

Python小例子200道练习题
Python小例子200道练习题

Python练手项目
Python练手项目

Python从零在线练习题
Python从零到一60题