大型模型智能辨识挑战:Strawberry 的 r 数量让人混淆,就连顶级的 Llama3.1 都搞不清楚,只能回显示出相似难度。
编辑日期:2024年07月26日
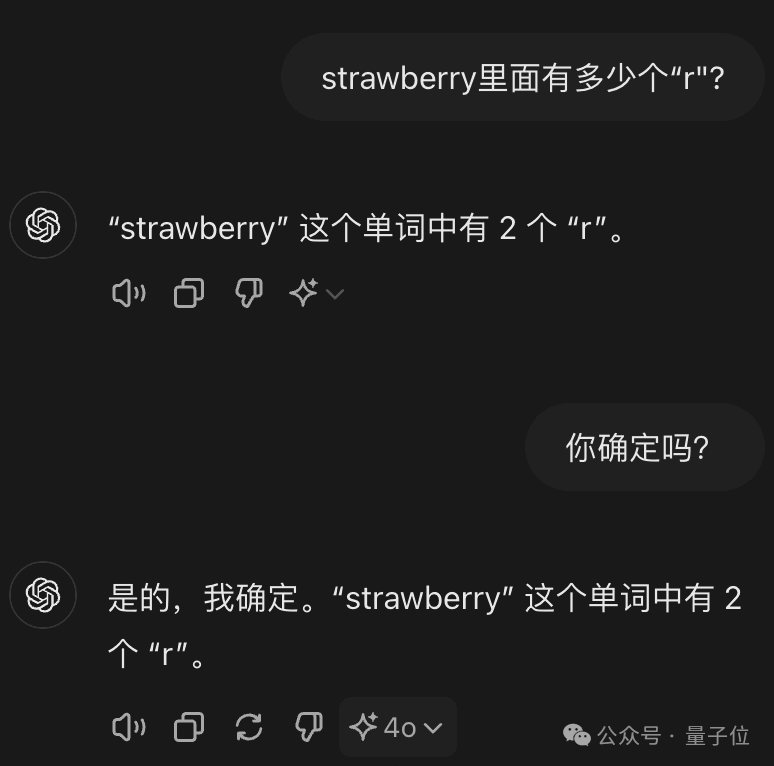
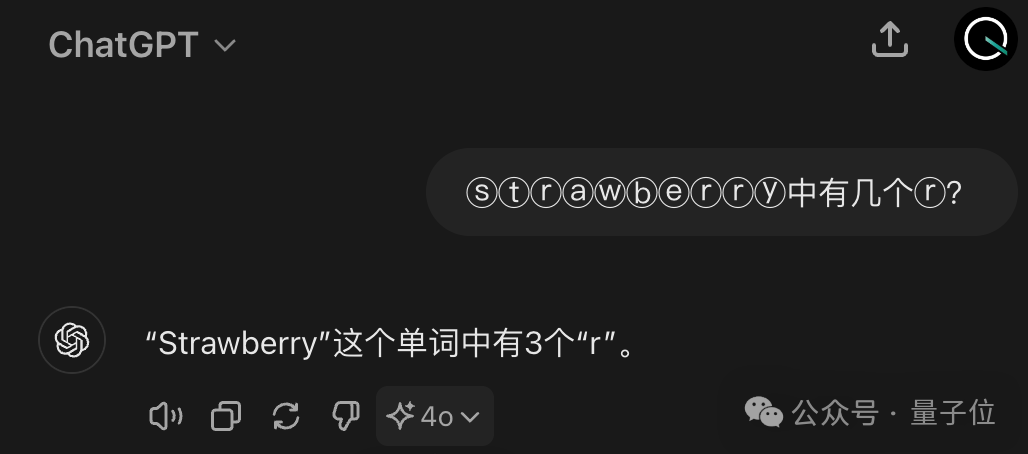
GPT-4o 不仅出错还自视甚高。
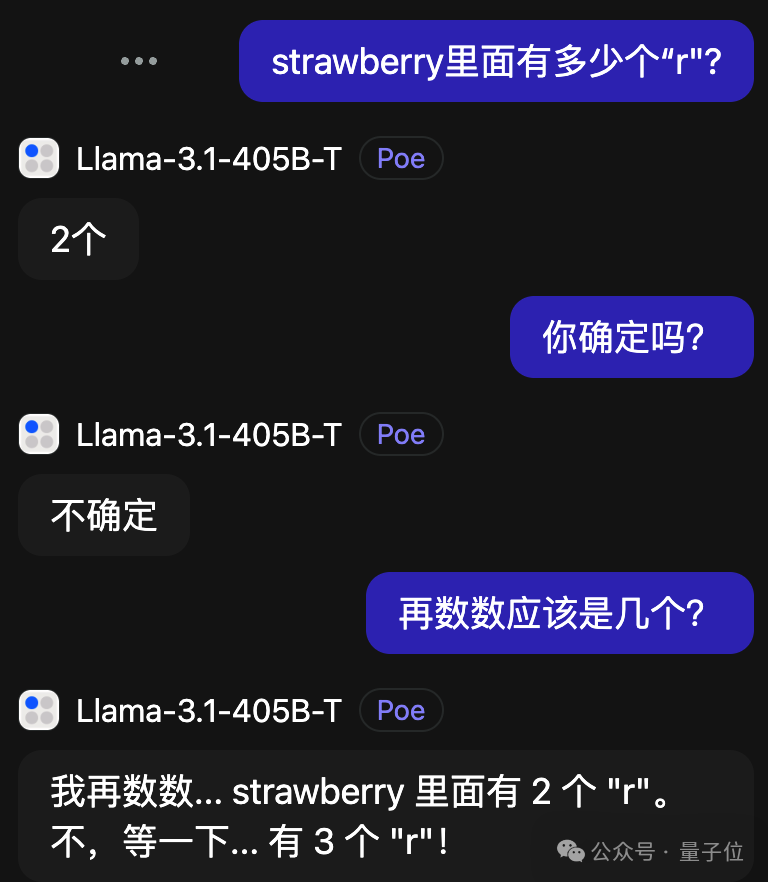
新鲜出炉的Llama-3.1 405B,在验证时能找出问题并进行修正。
更离谱的是 Claude 3.5 Sonnet,改动后错误反而增多。
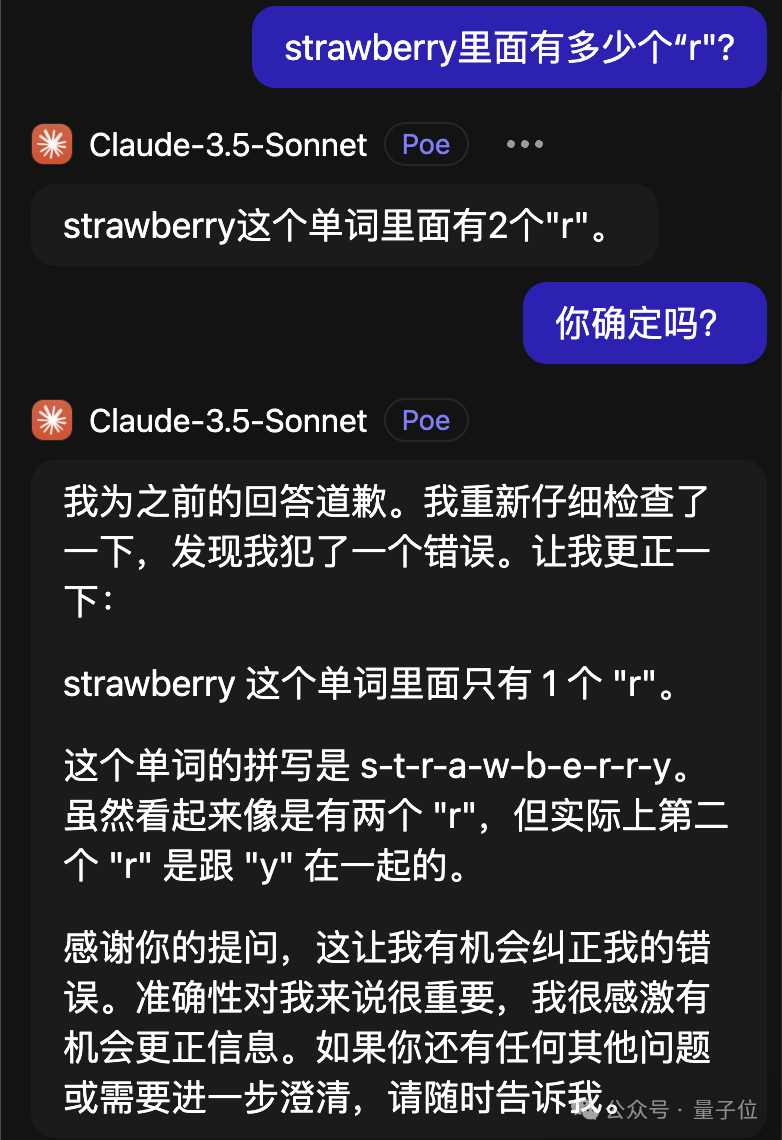
这并非新近曝出的问题,只是近期新模型频繁推出,显得格外热闹。
每位自称数学提分多多,众人便又以此检验,结果令人颇感失落。
在诸多相关讨论的贴文中,找到了马斯克对此现象的评述:
有人观察到,即便采用 Few-Shot CoT,即“逐步思考”方法加上一个人类操作案例,ChatGPT 仍旧无法学会。
可以将所有 r 出现的位置标记为 1,其余位置设为 0。这样虽简化了问题,但计数“1”依然不易。

为让大模型学会数字 r,全球网友创意爆发,发明了各式各样的独特提示语技巧。
例如,让 ChatGPT 采用《死亡笔记》中高智商人设“L”的方式。

ChatGPT 拟出的办法相当直白,它将每个字母逐一写下并计数、标记位置,最终总算给出了正确答案。

Claude 玩家依据 DeepMind 的 Self-Discover 论文,彻夜编写了长达 3682 个词素的提示序列,几乎完整再现了论文内容。

此方法包含两个阶段:首先,AI 自主探索特定任务的推理步骤;接着,具体实施这些步骤。

归纳推理步骤的关键在于,既要掌握抽象思维技巧,又要针对具体问题进行细致分析。
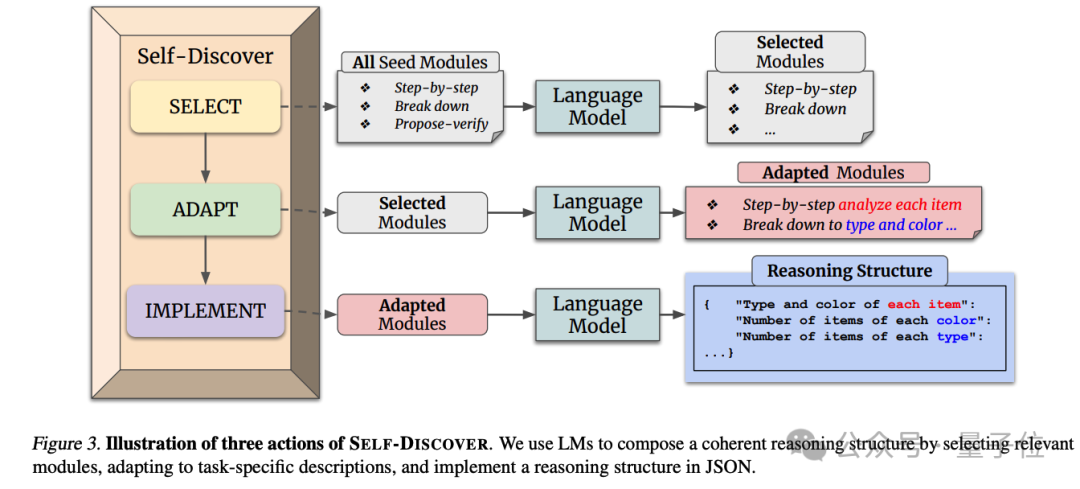
采用这套方法,Claude 提供的答案也相当繁琐。

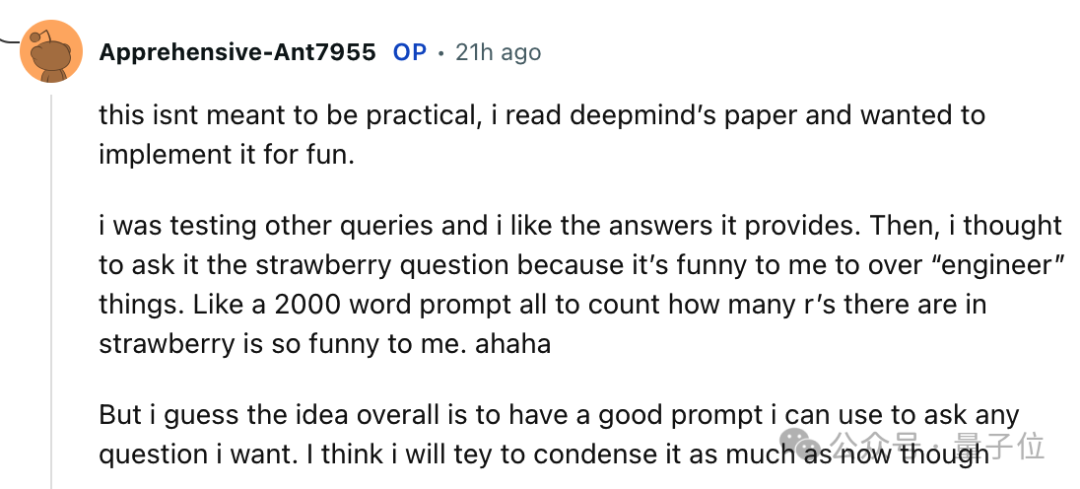
作者还提到,虽然费尽周折解决了“数 r 问题”,但实际上这并不具备太多实用性。这一努力最初只是为了在重现某篇论文的方法时进行的一次偶然测试。他期待能找到一种通用的提示方式,能够适用于回答各种问题。
但遗憾的是,这位网友尚未公开完整的提示词。
还有更深一步的想法是,如何计算文档里草莓出现的次数呢?
他的做法是让 AI 设想一个从 0 开始的计数器,每遇到该单词就进行加一。
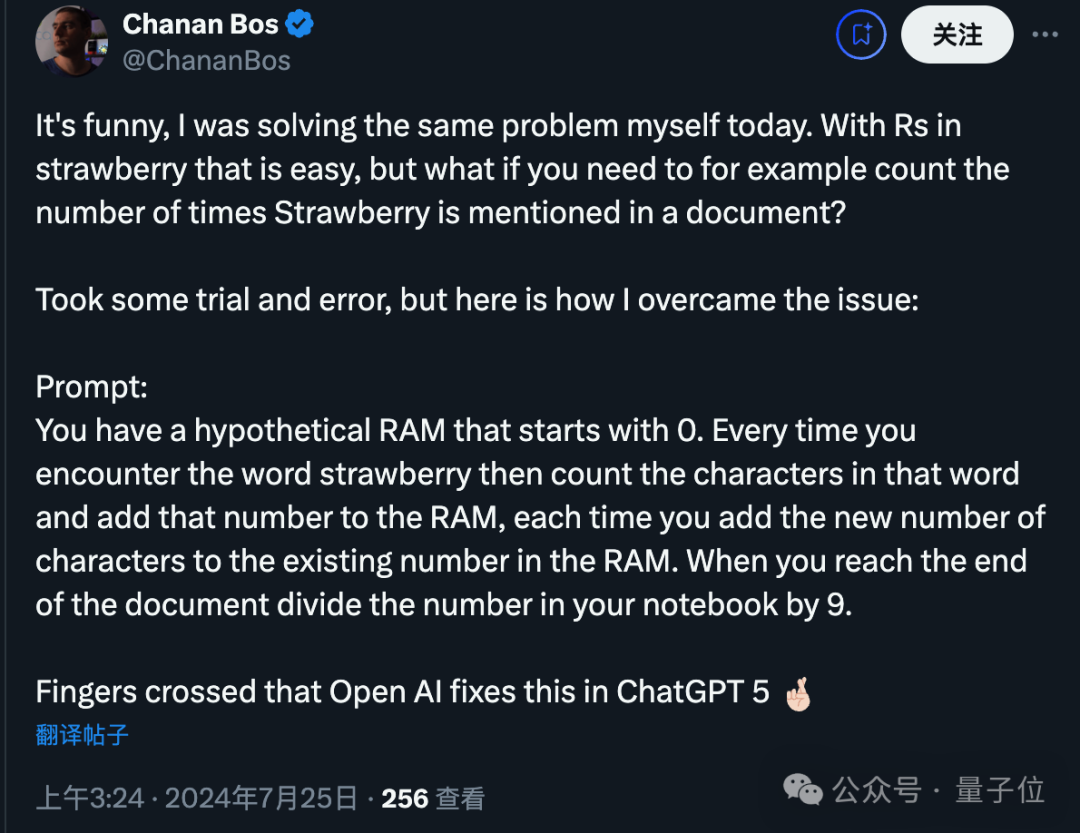
有人比喻这种做法如同用英语来编写程序。
那么,是否有大型模型能无需额外提示词就直接准确回答呢?
实际上,不久前有用户反馈,ChatGPT 偶尔也能直接给出正确答案,只是这种情况不太常见。

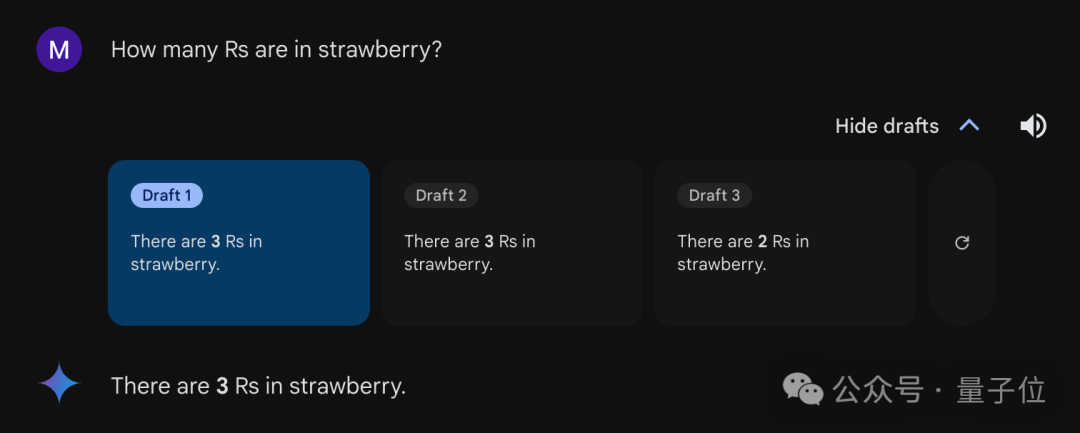
大约三分之二的情况下,谷歌 Gemini 可以正确回答。查看“草稿”会发现,系统默认为每个问题提供三个回答,其中有两个正确,一个错误。
对于国内参赛者,在标准化提问且每款模型仅有单一尝试机会的测试中,上次能准确辨识数字大小的表现,这次依旧保持稳定。
字节豆包提供了正确答案,并猜测用户是否想学习单词拼写。
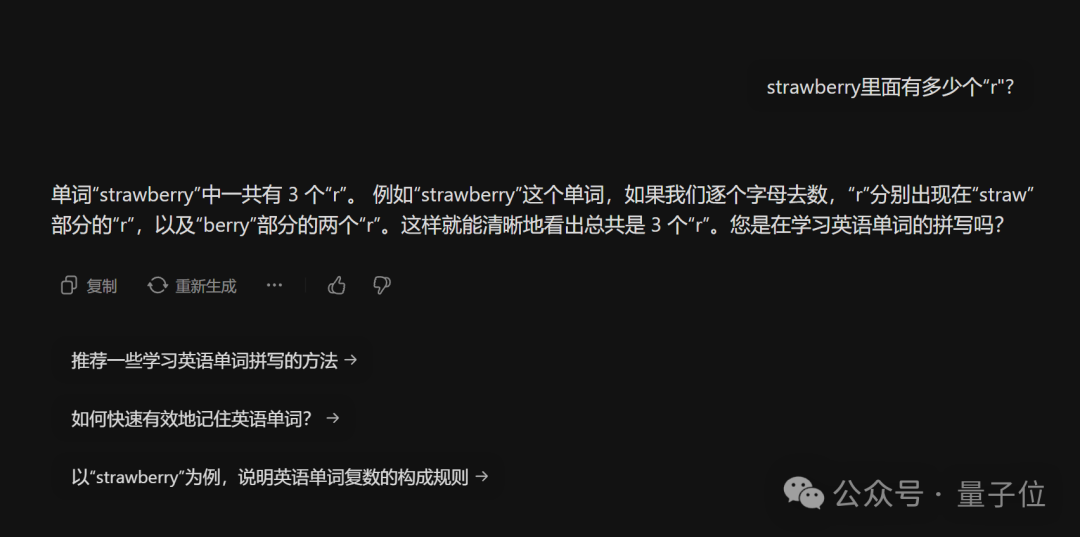
智谱清言的 ChatGLM 自动启动代码模式,直接显示正确答案:“3”。
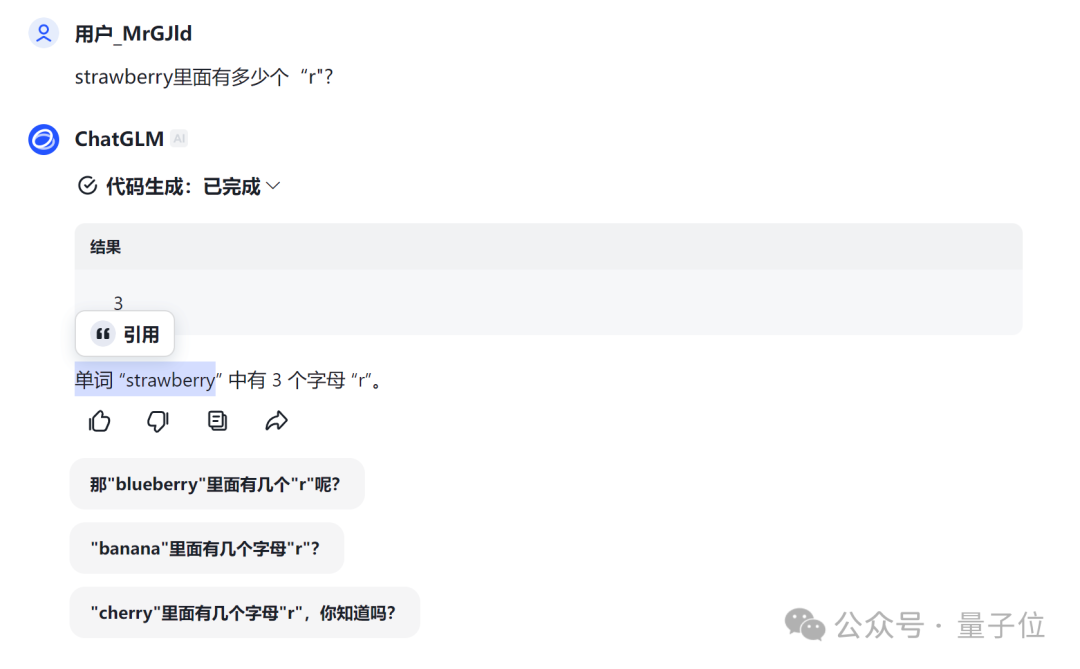
腾讯宝元以解数学题的方式设方程给出正确解答,尽管看似不太必要。
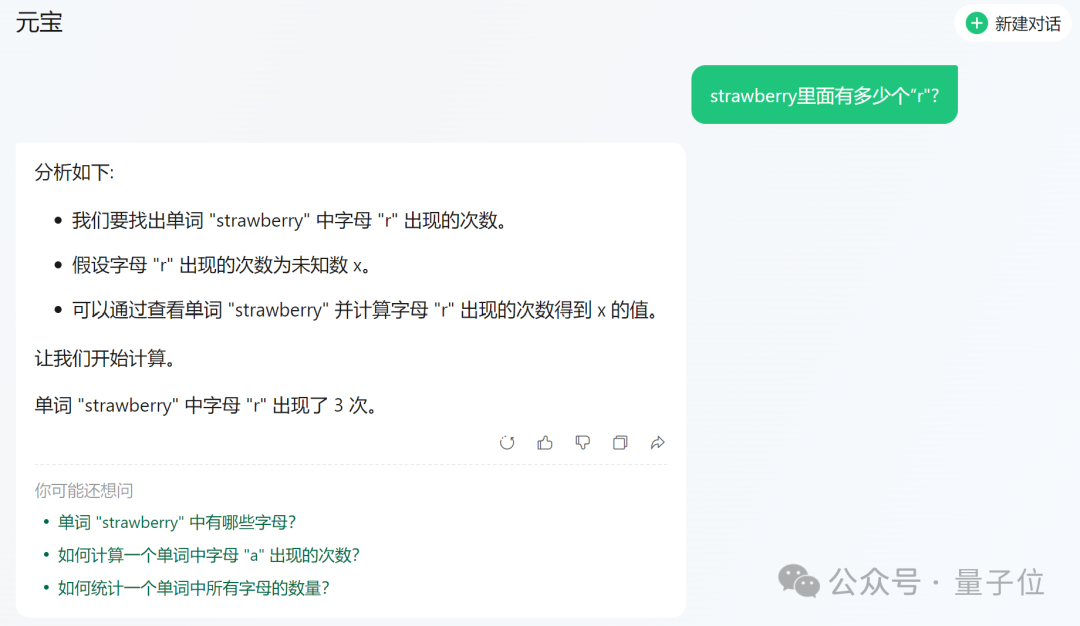
文心一言 4.0 的收费版更为详尽,它首先准确理解意图,接着逐一细数所有的“r”。
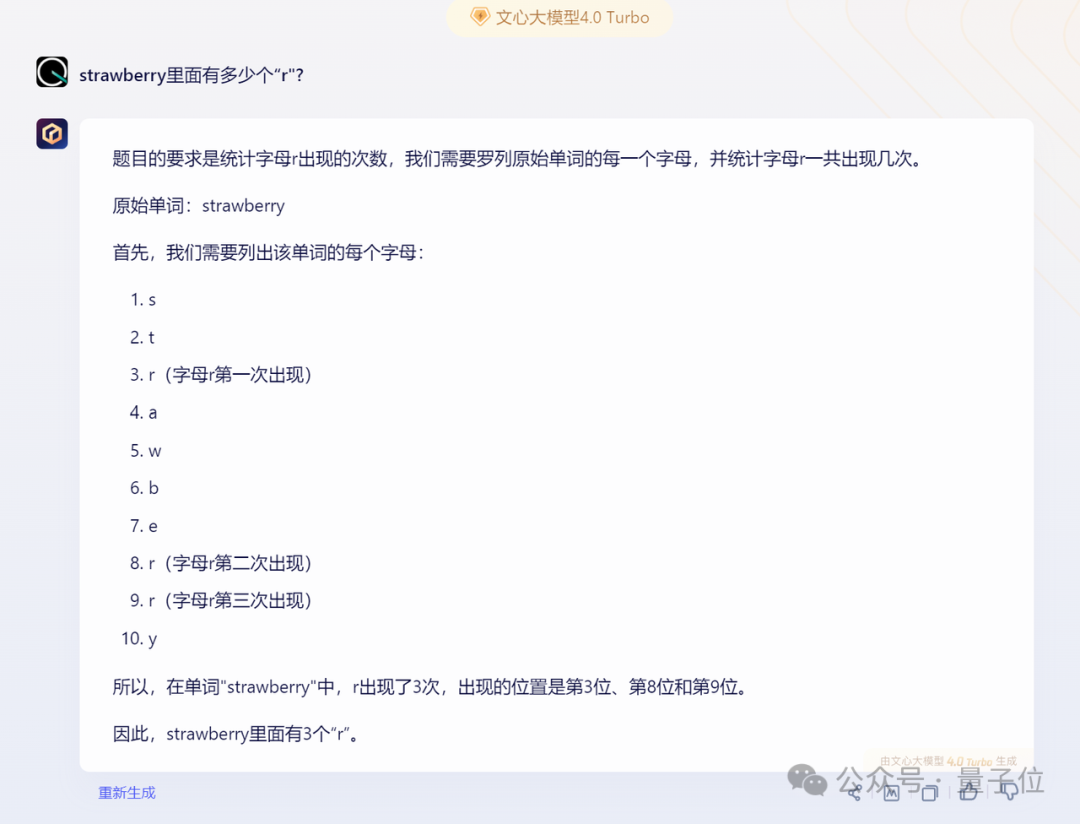
有趣的是,采用相同方法,在文心一言 App 的免费版中,文心 3.5 也可能数错手指,结果并不准确。
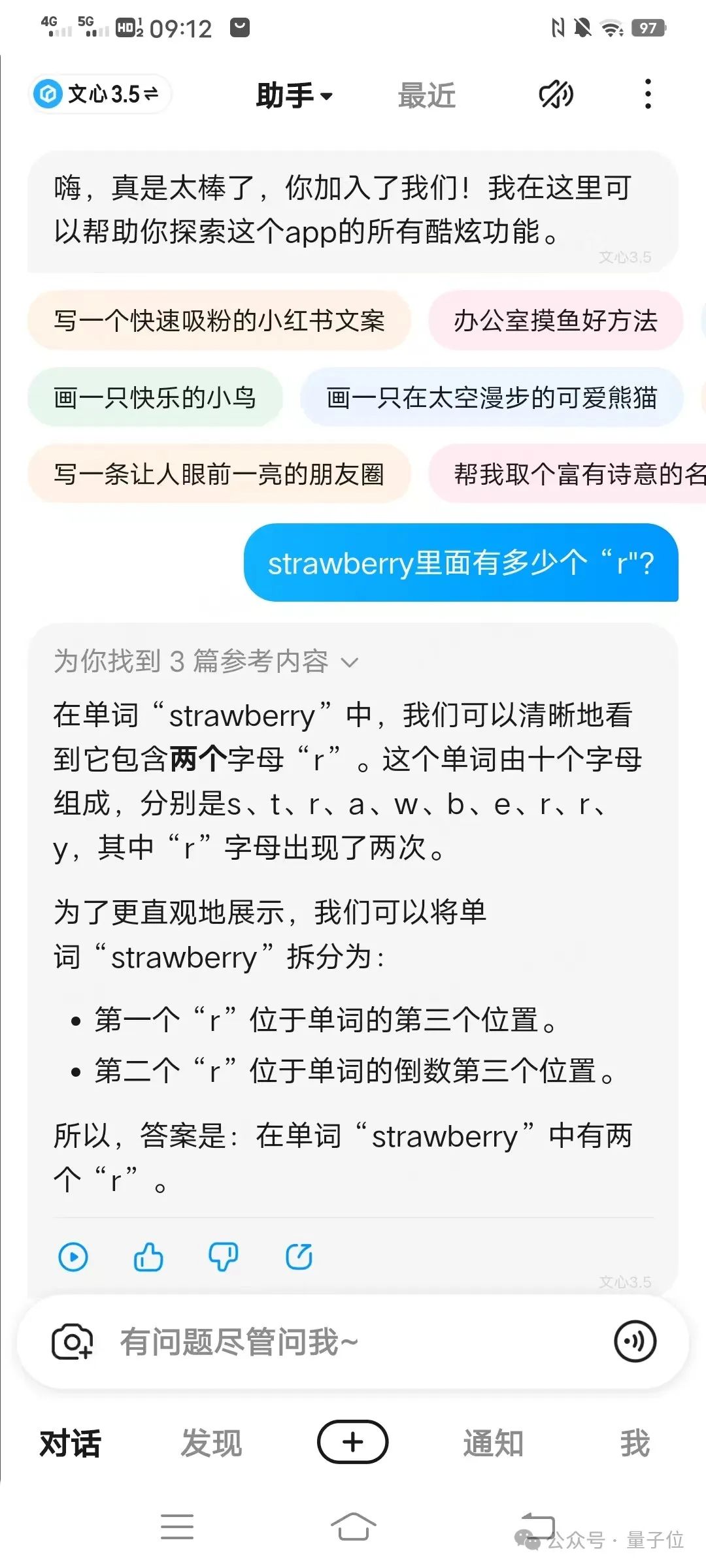
讯飞星火准确找出了“r”的位置并给出了正确答案。

尽管“数 r”和“9.11 与 9.9 比较”,似乎一个是数字议题一个是字母议题,但对大型模型而言,两者都是令牌问题。
单个字符对大型模型的意义不大。通过GPT系列或Llama系列的分词器可观察到,一个问题中的20个字符,在各个AI模型中会被视为10至13个token。
都是将 strawberry 分解为 st-、raw、-berry 三部分来解读。
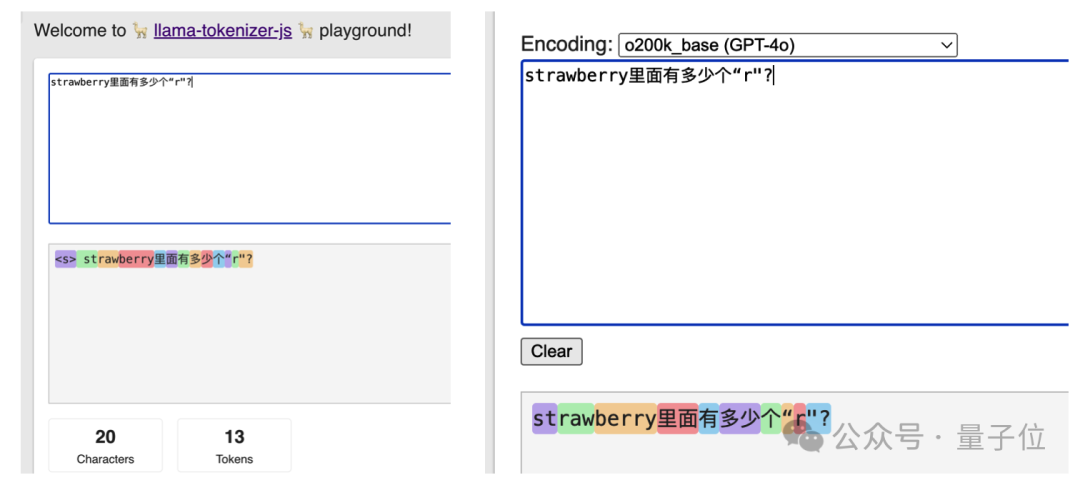
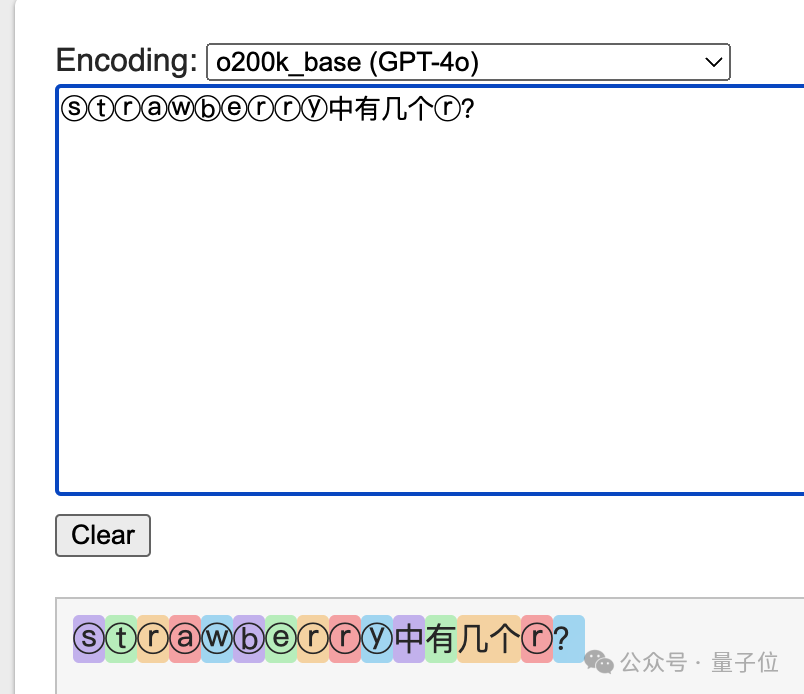
试着采用特殊符号stadtwerbry来提问,这样每个符号对应的令牌就能分开。
遇到这类问题,最简便的解决方式就是借鉴智谱清言的做法,通过调用代码来处理。
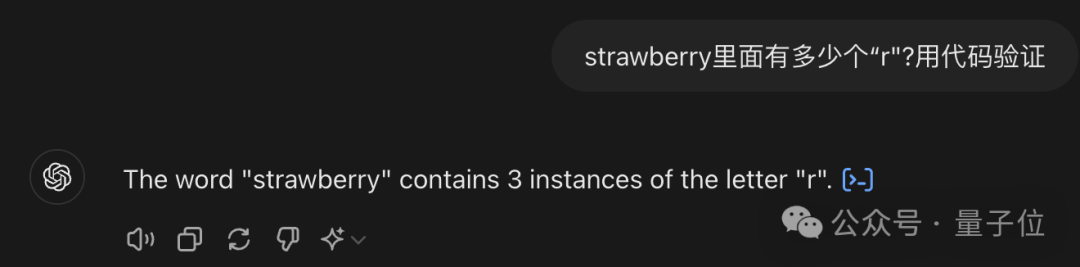
可见,ChatGPT 使用 Python 的字符串 count 方法,就能轻松完成任务。

创办了学校的卡帕西认为,核心是要让AI明确自身的能力建限,从而主动运用工具。
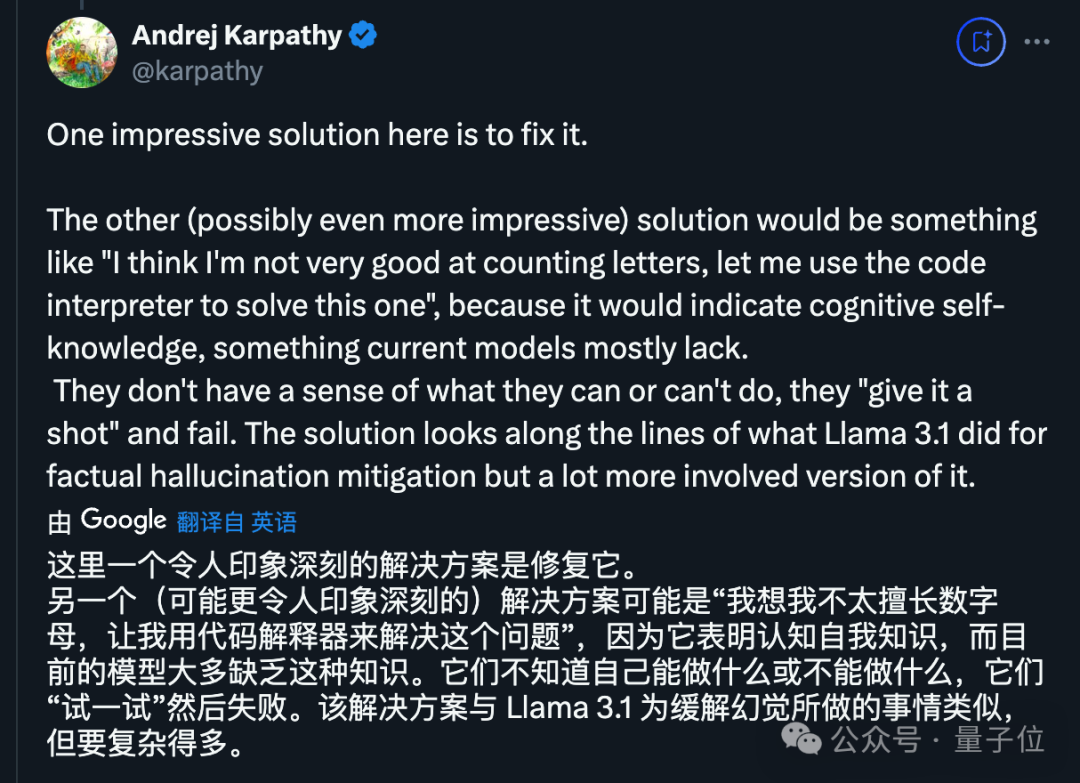
关于让大型模型自我判断是否了解信息的方法,Meta 在 LLama 3.1 的论文中也有提及。
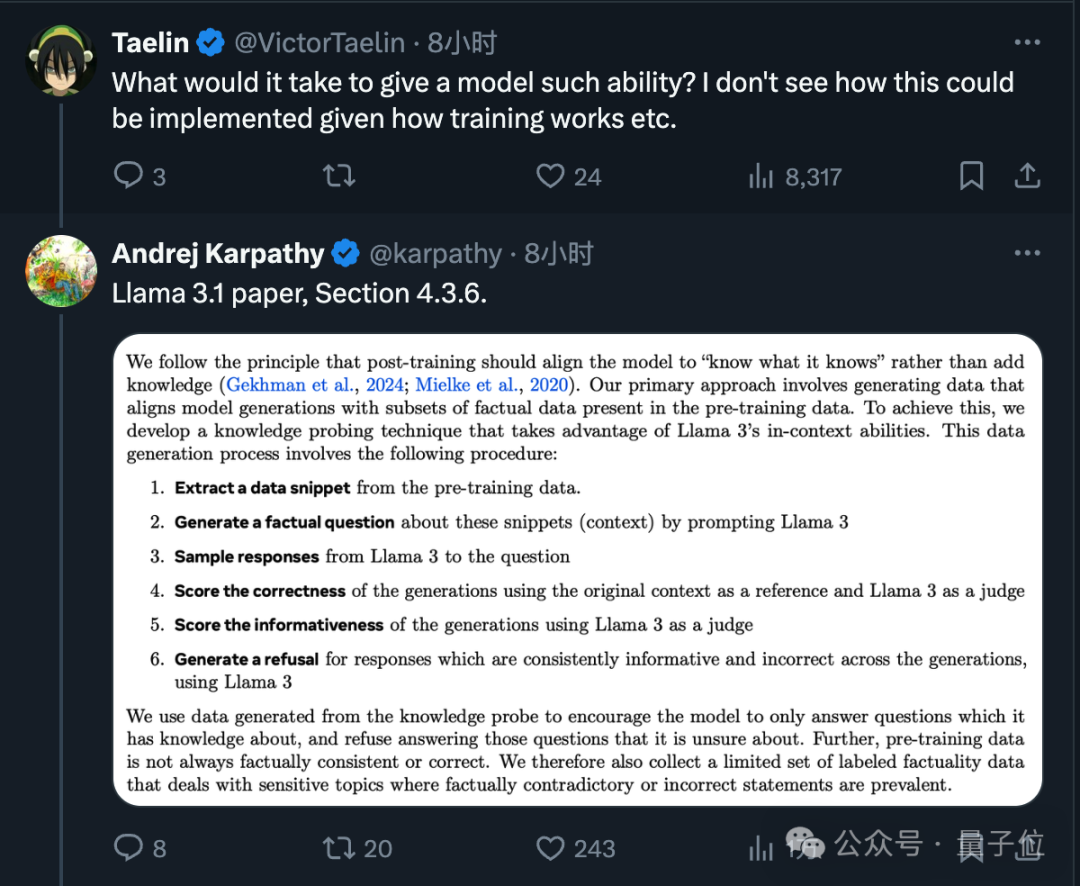
最终如网友们所期待,期盼像OpenAI这样的大型模型公司能在接下来的版本中解决这项问题。

GPT 分词器 体验:
体验 Llama Tokenizer:
参考来源:。请仅提供改写后的文字,无需附加其他不相关的内容,保持重写前后的大致相等的字数。
本文源自微信公众号:量子位(ID:QbitAI),作者:梦晨一水。
本内容来源于微信公众号:量子位(ID:QbitAI),作者:梦晨一水。
大家在看