






ICML的最佳论文曾被ICLR拒绝,该论文的第一作者现已加入OpenAI,同时Pika的联合创始人也有参与。
编辑日期:2024年07月26日
ICML 2024的最佳论文已经揭晓,有趣的是,这篇论文之前曾被ICLR 2024拒绝。

这篇出自斯坦福的研究,Pika的联合创始人孟晨琳(Chenlin Meng)也是作者之一。他们提出了一种新颖的离散扩散语言模型方法,通过引入分数熵损失函数,有效提升了离散扩散模型在语言建模任务上的表现。
实验结果显示,这种方法在多项任务上超越了GPT-2。
生成效果如下:

五位审稿人的评分分别为:8、8、6、6、5。尽管如此,最终还是被高级委员决定拒稿……
这一情况让人联想到Mamba,作为Transformer架构的挑战者,它为大型模型开辟了新的路径,却同样遭到了ICLR的拒绝。
这引发了广泛的争议,甚至ICLR的创始人之一Yann LeCun也表达了不满:
令人遗憾的是,历任程序委员会主席逐渐将其变成了一场接近传统评审流程的会议。
至少有些积极的变化:OpenReview平台现已被大多数机器学习/人工智能会议采用,并且论文提交后即可公开阅读(虽然匿名)。
还有人评论道:
如果搜索ICML 2024接受的论文,会发现许多都被ICLR 2024拒绝了。

这次又是怎么回事呢?
本文聚焦于扩散模型在处理如文本等离散数据时表现不佳的问题。研究团队认为,传统的扩散模型基于分数匹配原理,但这种方法在应用于离散数据时效果不尽如人意。
为解决这一问题,他们提出了一种新的损失函数——分数熵(Score Entropy),并基于此构建了分数熵扩散模型(SEDD)。
在主要的语言建模任务中,SEDD的表现优于当前所有的语言扩散模型,并且与相同规模的自回归语言模型相当,在零样本困惑度任务上甚至超越了GPT-2。
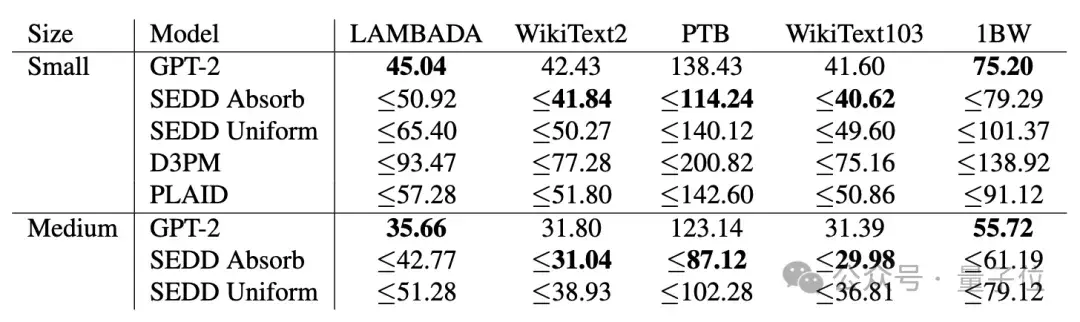
此外,SEDD能够生成高质量的无条件样本,并且能够在计算成本和生成质量之间进行灵活权衡。通过直接参数化概率比,SEDD具有高度可控性,可以通过提示词微调来实现特定需求,无需额外训练。
五位审稿人中有两位给出了8分的高评价。
大多数审稿人对论文提出的观点表示认可。其中一位审稿人特别赞扬了论文的推导部分,认为其实验结果非常令人信服。

然而,也提出了一些改进意见,包括拼写错误以及缺乏对某些实验细节的解释等问题。

从记录来看,作者对审稿人提出的问题进行了详细的解答和修正(有些回复分两次提交)。
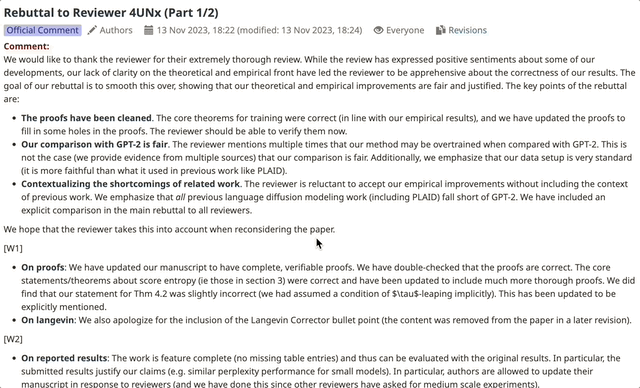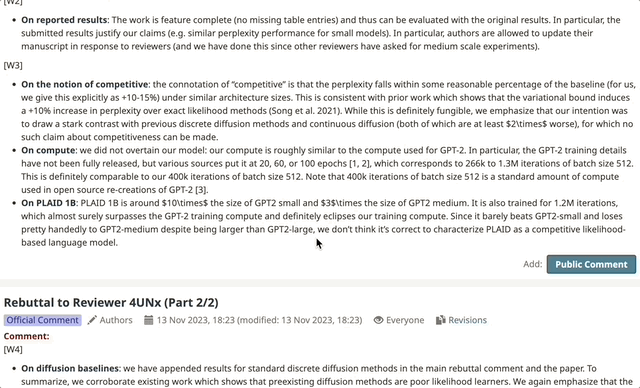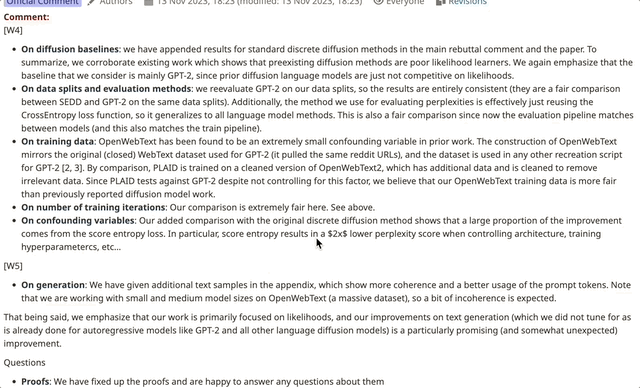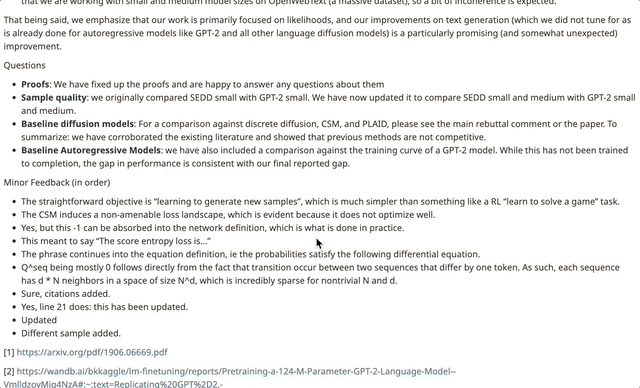
一些审稿人在看到作者的修改内容后,相应地调整了自己的评分。
ICML的最佳论文曾被ICLR拒绝,尽管之后作者进行了补充,但最终评审委员会(AC)仍未接受这篇论文。主要的批评集中在实验部分的完整性不足。
审稿人们普遍指出,该论文仅以GPT-2为主要基准进行比较,而未涵盖其他扩散模型作为基线。在提交时,实验部分被认为不够全面。尽管作者后来增加了额外的实验,AC依然认为这些补充不足以弥补原有的不足,并且论文中关于先前扩散模型性能不如自回归模型的说法可能存在偏差。
例如,SSD-LM和TESS等模型的表现优于GPT-2,但论文并未与这些模型的结果进行对比。
总的来说,AC认为该论文提出的想法很有价值,但在实验设计和基准对比方面存在不足。
值得一提的是,这种情况并非首次出现——之前Mamba也被拒绝,但在完善后获得了最佳论文奖。这次论文的第一作者最近加入了OpenAI,并计划在即将举行的ICML 2024会议上详细介绍这项研究。
论文链接:https://arxiv.org/abs/2310.16834
大家在看




















