Nature封面:AI训练AI,越训越愚钝
编辑日期:2024年07月27日
垃圾进,垃圾出
白交 报道 自 凹非寺
AI 训练 AI,可能会让 AI 变得越来越傻?
直接结果就是:输出一堆垃圾!

要知道,现在绝大多数科技公司的大型模型都在使用合成数据来解决“数据短缺”的问题。这项研究无疑给整个行业泼了一盆冷水。
研究团队给出了这样一个例子。
他们测试了 Meta 的 OPT-125m 模型,询问了一些关于中世纪建筑的信息。

每一次微调都由上一次生成的数据进行训练。起初的回答还算正常,但在第九次时,就开始乱讲了……
扯到兔子是怎么回事?!
该论文的主要作者表示,他们曾考虑到合成数据可能对大型模型产生误差,但未曾想到模型的恶化速度会如此之快。
首先,团队定义了何为模型崩溃。
模型崩溃是一个退化过程,在这个过程中,模型生成的内容会污染下一代的训练数据集。而在被污染的数据上训练后,新一代模型更容易误解现实。
如此循环往复,每一代模型都比前一代更糟糕。
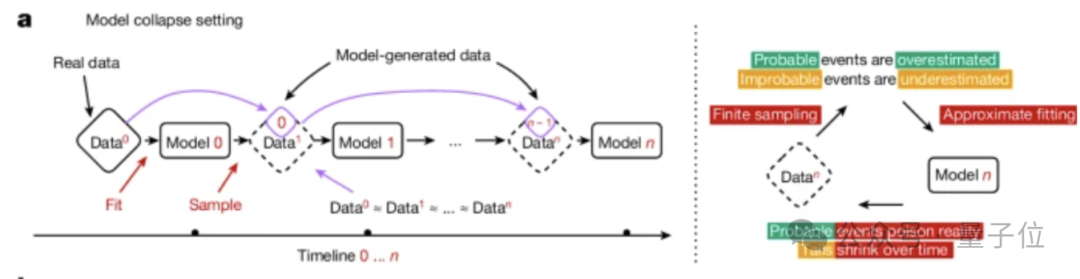
随着时间的推移,主要分为两种情况:早期模型崩溃和晚期模型崩溃。
在早期模型崩溃中,模型开始丢失一些尾部信息(类似于概率分布中的低概率事件)。而在晚期模型崩溃中,模型将收敛到与原始分布几乎毫无相似之处的状态。
这一过程的发生与模型设计、学习过程及使用的数据质量有关。
具体到理论上,主要有三个方面的误差导致大型模型与原始模型出现偏离。
随后,研究者们评估了模型退化对语言模型性能的影响。鉴于重新训练大型模型的成本高昂,他们选择了评估语言模型中最常见的场景——微调场景。在每次训练周期中,都从最新的预训练模型出发,该模型包含了最新的数据。训练数据则来源于另一个已经过微调的预训练模型。
他们采用了Meta公司的因果语言模型OPT-125m,并在wikitext2数据集上进行了微调。
为了从已训练的模型中生成数据,研究团队采用了五路波束搜索方法。他们将训练序列设定为64个令牌(token)的长度;然后对于训练集中的每一个令牌序列,让模型预测接下来的64个令牌。
通过浏览所有的原始训练数据集,他们生成了一个与之同样大小的合成数据集。如果模型的误差为零,那么它将会生成与原始wikitext2数据集相同的数据。
为了更直观地展示差异,他们设置了两种不同的情况:一种是在后续过程中不包含任何原始训练数据,只保留初始训练;另一种则是保留10%的原始数据。
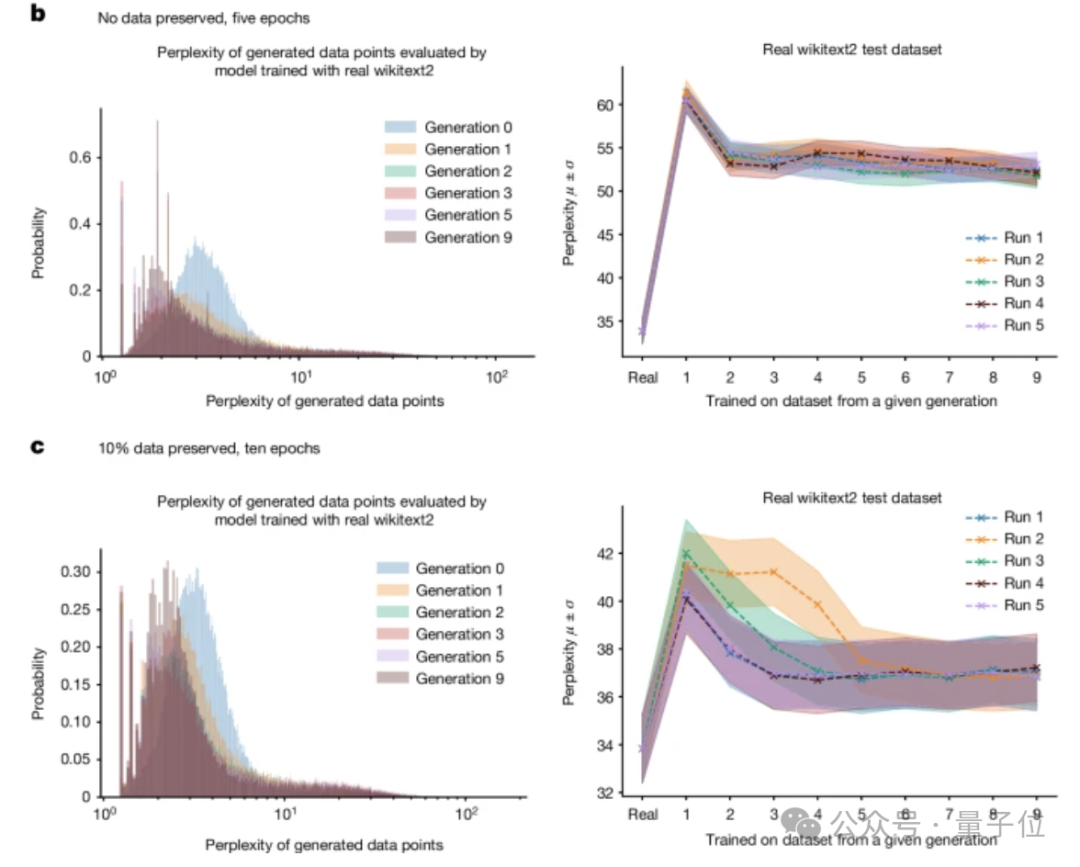
结果表明,随着时间的推移,模型产生的错误逐渐增多。在模型彻底崩溃之前,它会导致模型忘记数据集中发生的低概率事件,且输出内容变得越来越同质化,从而产生了上述的现象。
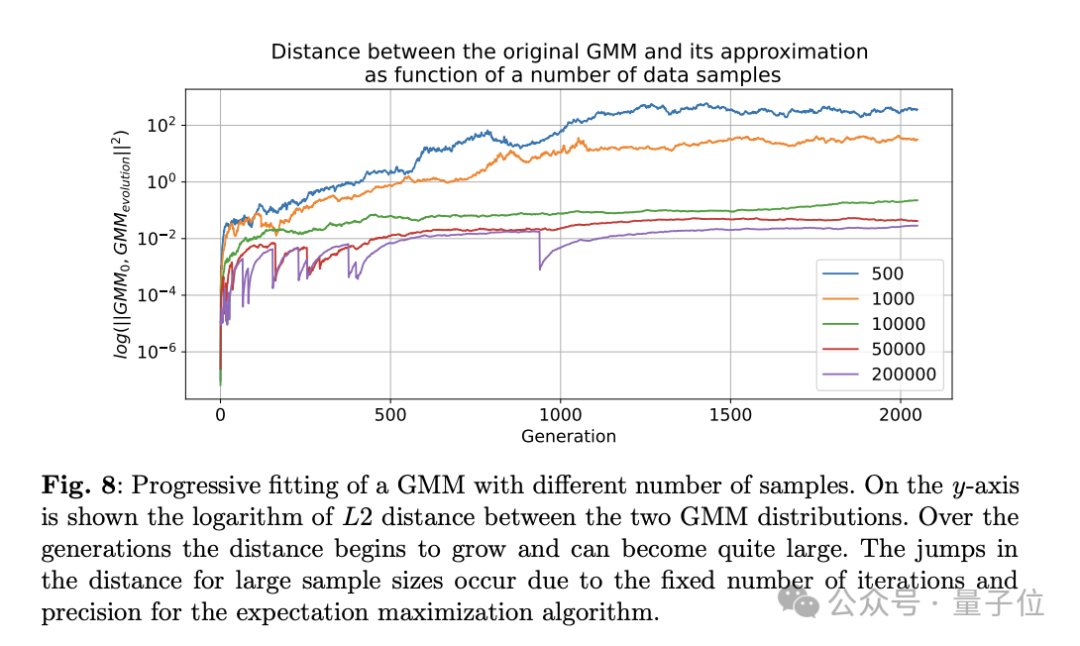
此外,在变分自编码器(VAE)和高斯混合模型(GMM)中也观察到了类似的模型退化现象。

一些领先的技术公司已经部署了一种技术手段,即在AI生成的内容中嵌入“水印”,以避免这些内容被再次用于训练数据中。然而,这一做法面临的挑战在于需要各大科技公司之间的协作,因此在商业上可能不具备可行性。
这样一来,那些从互联网获取大量数据的公司所训练出的模型能更好地反映真实世界的情况。因此,首批大规模模型似乎占据了先机。对于这种看法,您有何见解?
参考资料: [1] https://www.nature.com/articles/d41586-024-02420-7 [2] https://www.nature.com/articles/d41586-024-02355-z [3] https://www.nature.com/articles/s41586-024-07566-y
同时,一项突破性的进展解决了现有的热成像技术中的“重影效应”问题。

这项研究由耶鲁大学提供。