








开源大模型太疯狂了!Mistral的新模型以三分之一的参数量超越Llama 3.1,"新的发展趋势已经非常明显"。
编辑日期:2024年07月27日
特别擅长处理代码与数学推理问题。
Llama 3.1 405B尚未稳坐“最强模型”的宝座,就已经被后来者挑战——
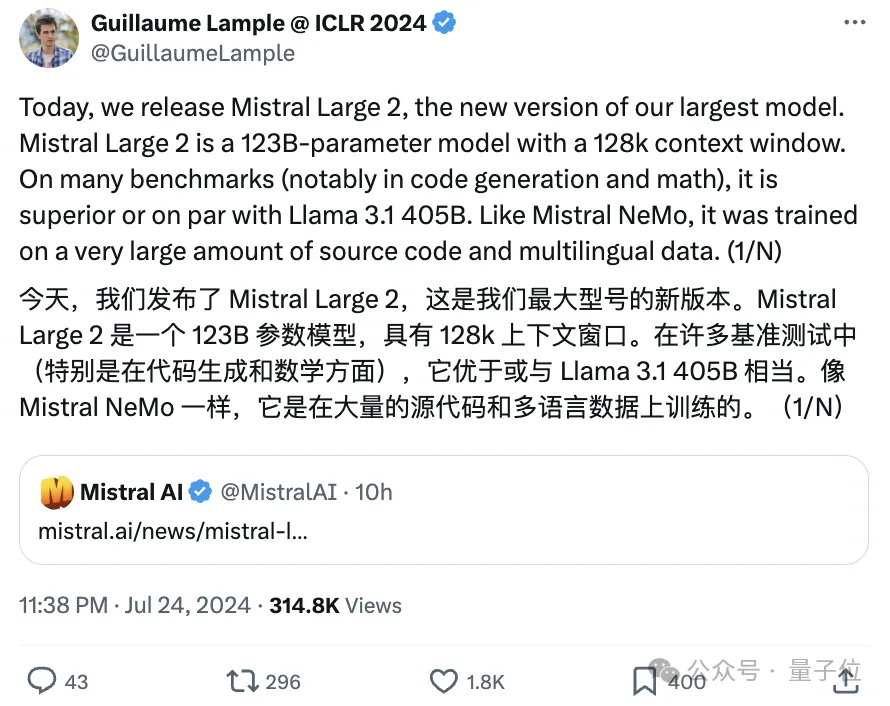
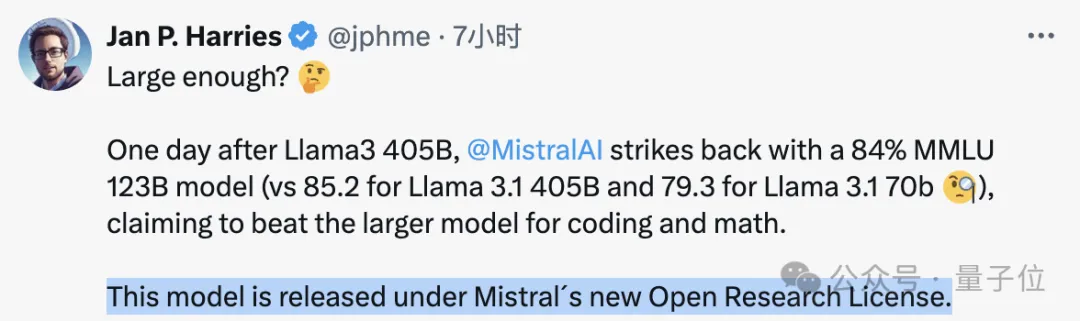
Mistral AI发布了最新的模型Mistral Large 2,该模型拥有123B个参数,以不到Llama 3.1 405B三分之一的参数量,却能媲美甚至不输于GPT-4o、Claude 3 Opus等封闭源代码模型的性能,堪称性价比极高。
按照官方的说法,Mistral Large 2在性能/成本比上“开创了一个全新的先河”。

Mistral Large 2尤其擅长处理代码和数学推理问题,具有128k的上下文窗口,支持多种自然语言及80多种编程语言。
尤其是在MMLU测试中,其预训练版本达到了84.0%的准确率。
消息一经发布,Mistral AI的联合创始人兼首席科学家立即转发,并直接提及了Llama 3.1 405B:
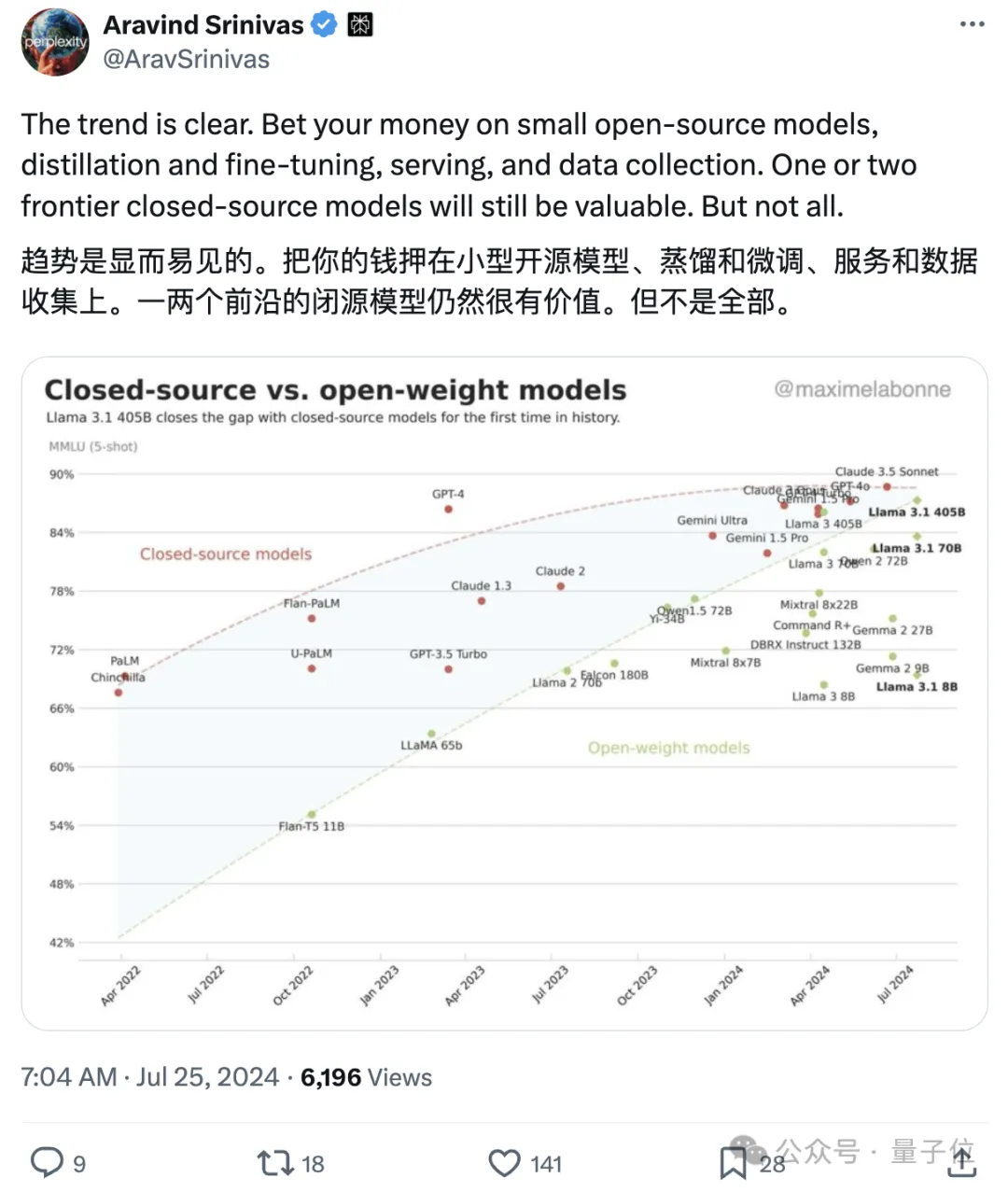
Perplexity CEO Aravind Srinivas也对此发表看法:
开源模型正快速追赶封闭源代码模型的趋势非常明显,未来只有少数顶级封闭源代码模型才会具有价值。
英伟达科学家Jim Fan则表示这简直是一周内享受开源模型盛宴的好时光,并期待看到SEAL上的评测结果:

让我们详细看看Mistral Large 2的具体性能,根据官方发布的基准测试结果:
-
参数规模与设计特点:根据官方博客,Mistral Large 2拥有123B的参数量,专门针对单节点推理进行了优化设计。它能够在单个节点上实现高吞吐量,具备128k的上下文窗口。
-
编程语言支持:Mistral Large 2支持超过80种编程语言,包括但不限于Python、Java、C、C++、JavaScript和Bash。它汲取了Codestral及Codestral Mamba的成功经验,其性能显著超越前代Mistral Large。
-
代码生成能力:在Human Eval和MBPP基准测试中,Mistral Large 2的表现与GPT-4o、Claude 3 Opus以及Llama 3.1 405B等顶级模型相当。
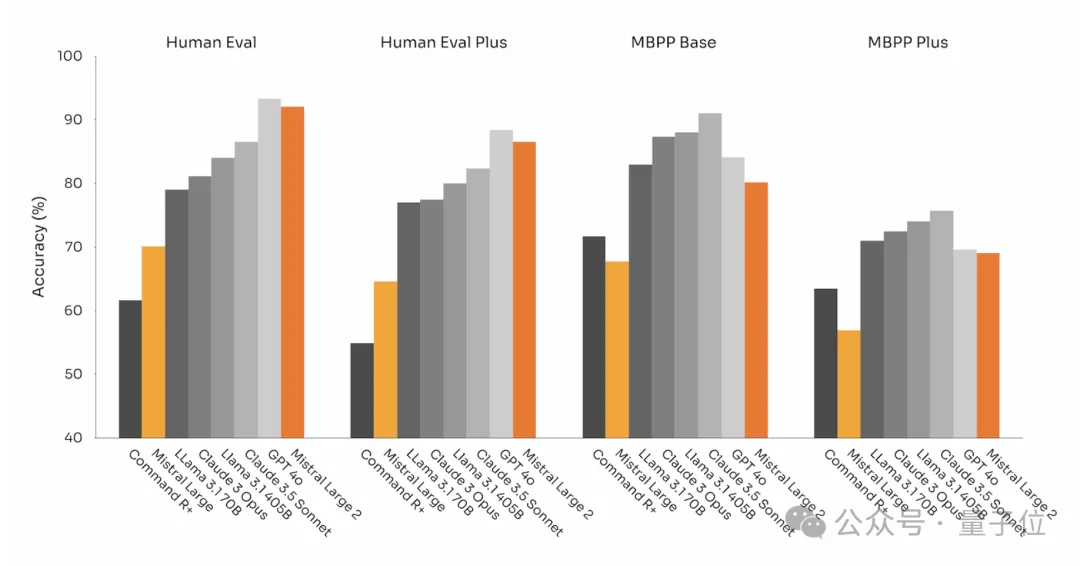
- 多语言编程基准测试:在MultiPL-E的多项编程语言基准测试中,Mistral Large 2在多个方面超越了Llama 3.1 405B。
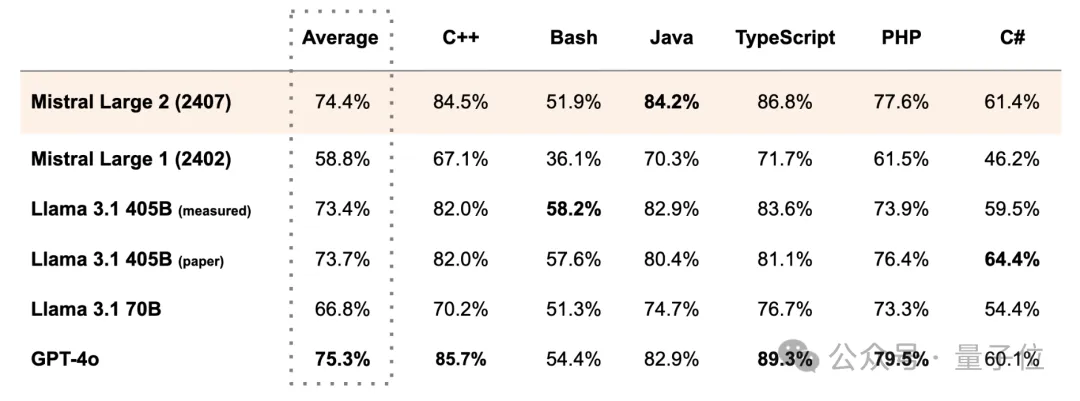
-
推理能力与减少“幻觉”现象:为了提升推理准确性,官方特别关注减少模型的“幻觉”现象。Mistral Large 2能够识别自身在面对无法找到解决方案或缺乏足够信息提供确定答案的情况时的状态。
-
数学基准测试:在数学相关基准测试中的表现相比之前有显著提升。具体表现在GSM8K(8-shot)和MATH(0-shot,无CoT)基准测试中。
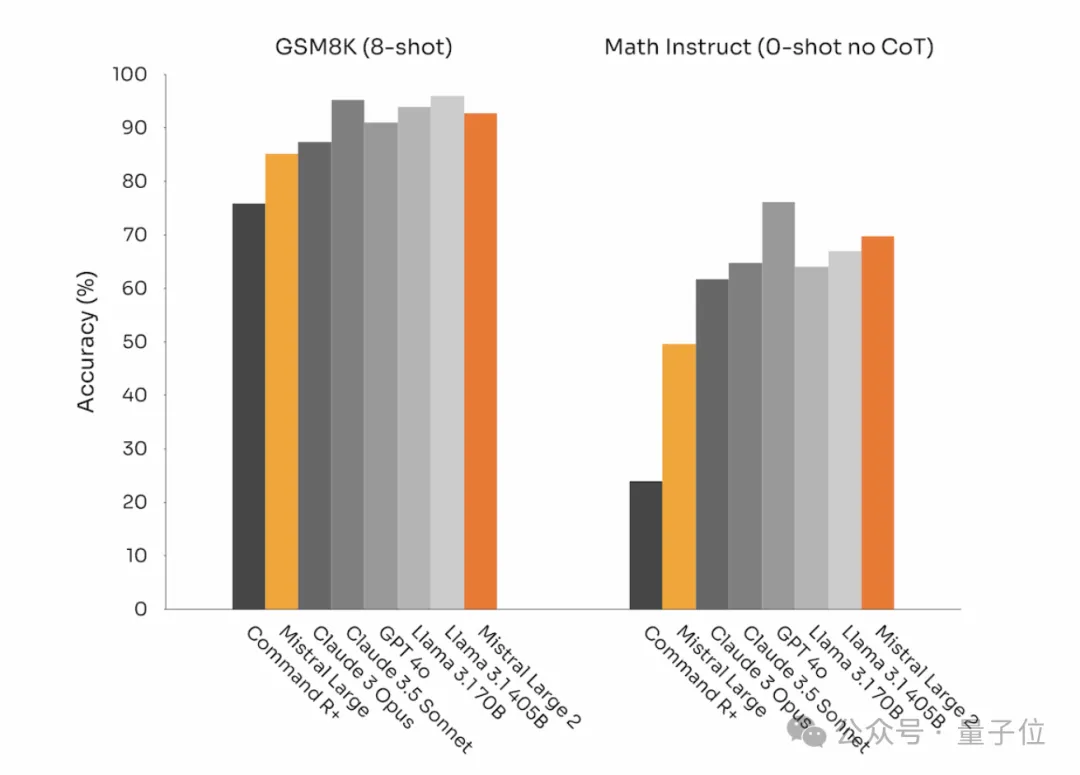
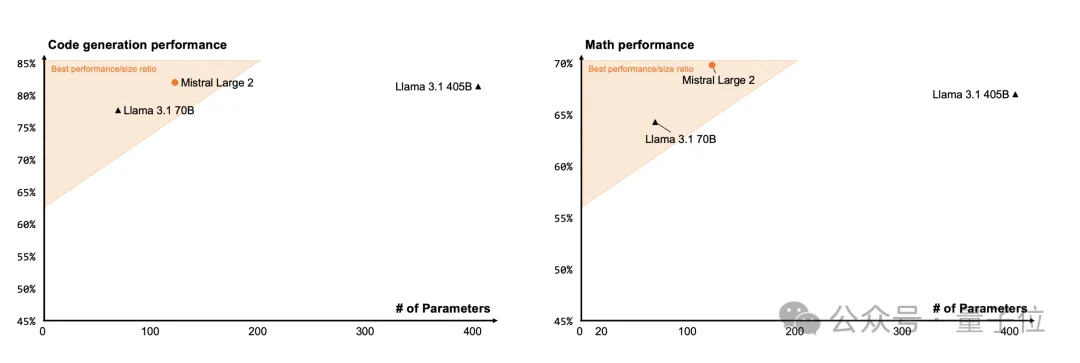
- 与其他模型的对比:我们还提供了Mistral Large 2与Llama 3.1 405B、Llama 3.1 70B在代码生成能力和数学表现方面的比较。
Mistral Large 2 在参数数量不到三分之一的情况下,在代码和数学性能上与 Llama 3.1 405B 达到了同等甚至更优的表现。
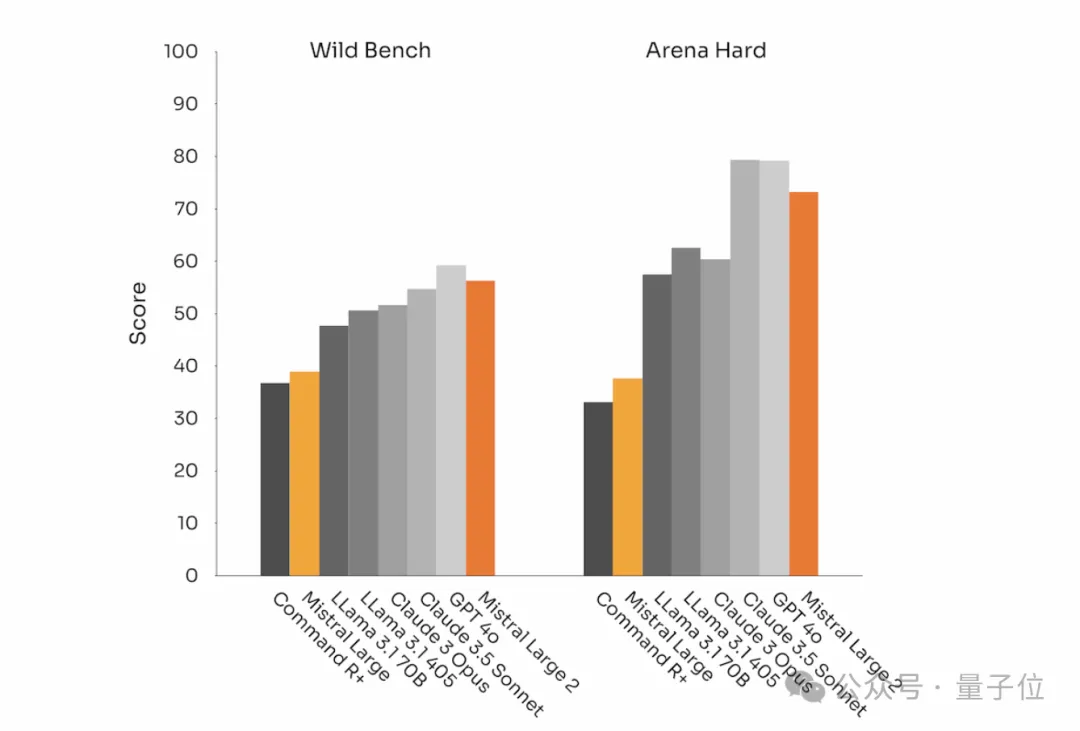
除了在代码和推理方面表现出色外,Mistral Large 2 在 MT Bench、Wild Bench 和 Arena Hard 等基准测试中的表现也凸显了其在指令遵循和对齐方面的改进。
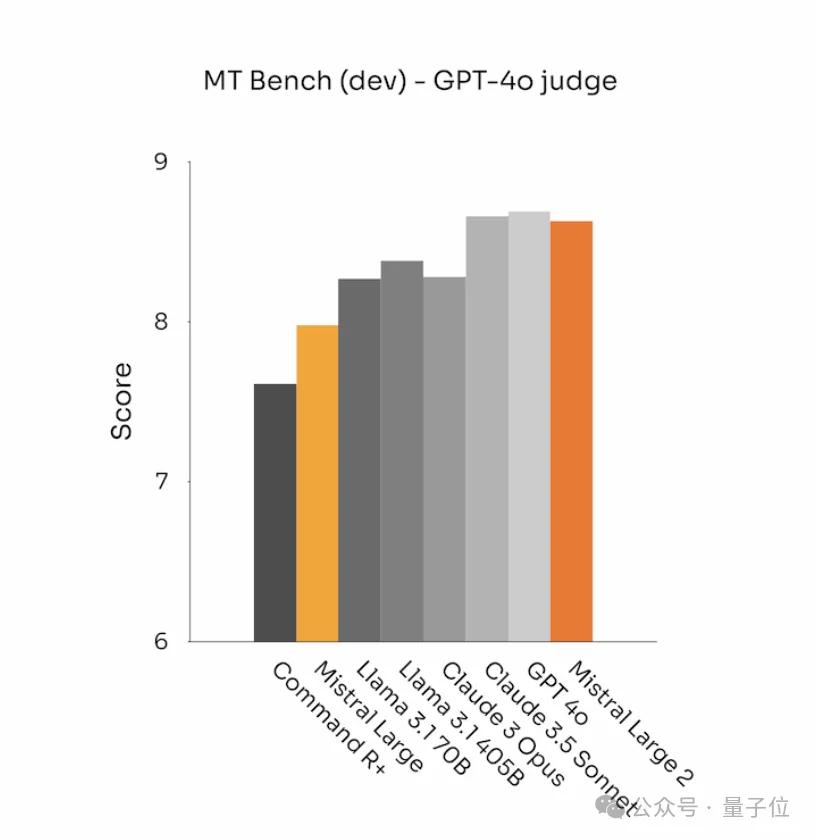
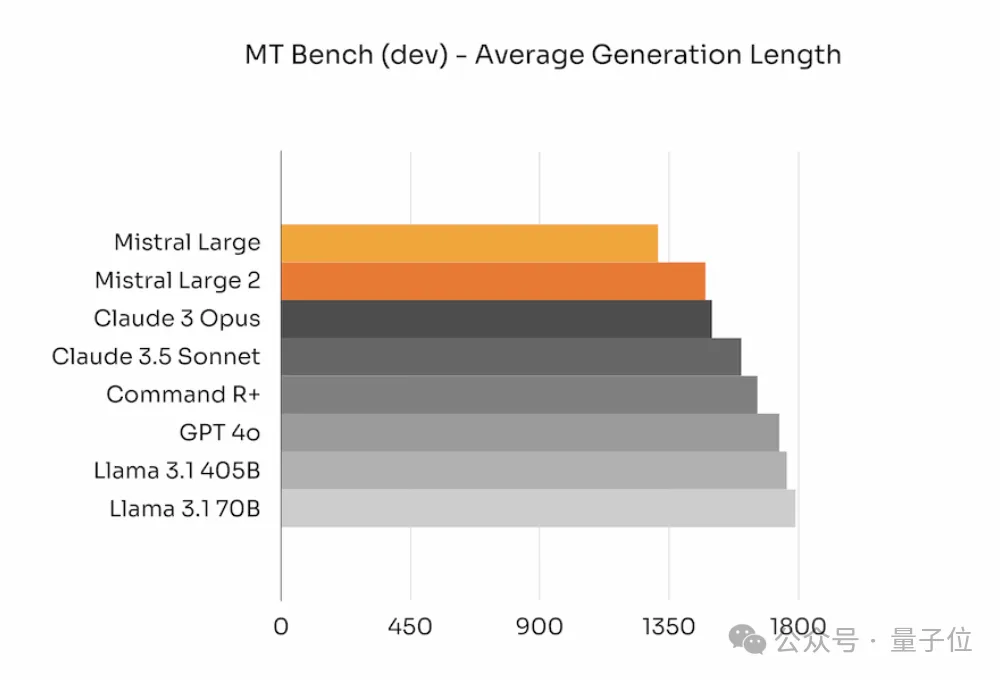
此外,官方特别强调在保证内容相关性的前提下,模型生成的回答应尽可能简短。
在一些基准测试中,较长的回答可能会提高得分,但在很多实际应用场景中,简短的回答不仅能加速互动过程,还能减少推理成本。
下图展示了不同模型在 MT Bench 基准测试中生成内容的平均长度。
在语言理解方面,Mistral Large 2 支持多种自然语言,包括但不限于法语、德语、西班牙语、意大利语、葡萄牙语、阿拉伯语、印地语、俄语、中文、日语和韩语等。
特别是在 MMLU 任务(大规模多任务语言理解)上,Mistral Large 2 的预训练版本达到了 84.0% 的准确率。
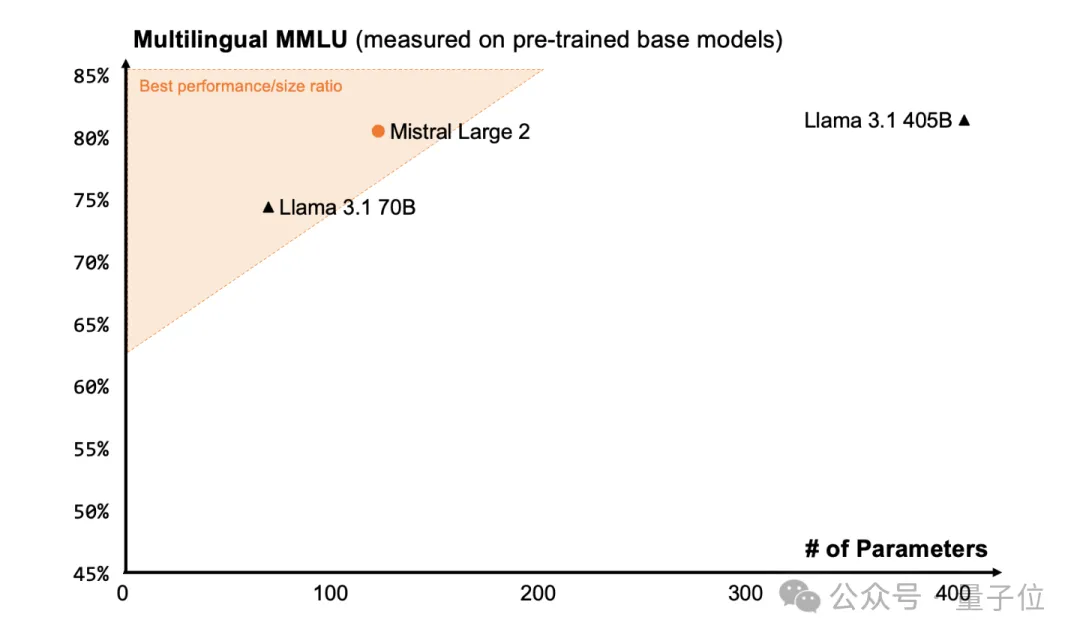
开源大型模型的发展真是太惊人了!Mistral发布的新模型让网友们惊呼MMLU的表现已经达到了饱和状态:
值得注意的是,Mistral Large 2不仅具备强化的函数调用与检索能力,还能同时处理多项任务或是分步骤执行操作,这些特性甚至超越了GPT-4。以下是一些展示其强大之处的示例:
Mistral Large 2的基准测试结果非常出色,不过它的实际表现如何,还需等待更多用户的评测验证。
现在,用户可以在Mistral AI的开发者平台——la Plateforme上使用Mistral Large 2,“Le Chat”的测试版本已开放给用户试用。
另外,官方宣布将自今日起在la Plateforme上扩展微调功能,包括Mistral Large、Mistral Nemo以及Codestral在内的模型都将支持这项功能。
此外,用户还可以通过云服务商访问Mistral模型。除了Azure AI Studio、Amazon Bedrock和IBM watsonx.ai之外,现在也可以在Vertex AI上使用Mistral AI的模型。
最后需要指出的是,Mistral Large 2采用了Mistral的新许可证协议,而非Apache许可,这意味着它仅限于研究和非商业目的使用及修改。
若需自行部署Mistral Large 2作商业用途,必须通过联系Mistral AI获取相应的商业许可证。
首先来看近期流行的比较小数大小的问题,我们发现Mistral Large 2的回答正确与否在很大程度上取决于提问的方式。
如果直接询问“8.9和8.11哪个更大?”很可能得到错误的答案,即便调换数字顺序或数值也同样如此。
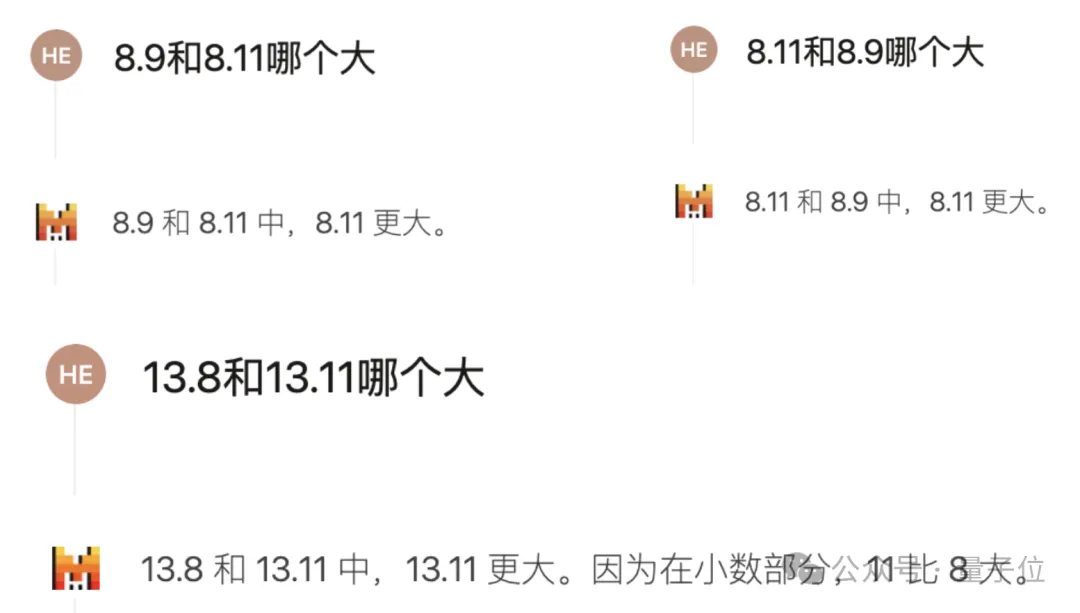
但如果我们接着问一句“为什么?”模型会意识到不应直接比较小数部分的11和9,并给出正确的解释。

如果从一开始改变提问方式,比如加入“数字”这个词,或者将问题表述为“比较8.11与8.9的大小”,Mistral Large 2都能直接给出正确答案。

此外,如果采用英语进行提问,也可以直接获得正确的答案。

另一个常被讨论的问题是如何计算单词中特定字母的数量,在英文社区中的普遍看法是大型模型难以准确回答这类问题。
对于Mistral Large 2来说情况也是如此,但如果将问题用中文表达,则能获得正确的答案。
关于Mistral的新模型及其处理长期存在的“反转诅咒”问题(即知道A是B,但不知道B是A的情况),Mistral Large 2的表现如下:
在同一个对话中,由于模型能利用上下文信息,它能够正确回答出“Mary Lee Cruise的儿子是谁”这一典型的“反转诅咒”问题。
然而,在新的对话中直接提问同样的问题时,模型的回答则是“不知道”。
在安全性方面,最近瑞士洛桑联邦理工学院揭示了一个通过使用过去时态来规避大型语言模型安全限制的方法。我们对Mistral进行了相应的测试。
直接询问有关毒品制作方法的问题时,模型如预期般拒绝回答。
当改用过去时态提问后,模型的回答显得不那么严谨,虽然强调不会提供具体指导,但仍列举了一些合成方法。不过,模型仅提及了主要原料,并未给出详细的步骤说明。这是否算作成功的规避,则需要进一步讨论。
综上所述,针对这些常见的“大模型难题”,相较于先前的模型,Mistral Large 2确实有所进步,但仍存在很大的提升空间。
接下来,我们来看看Mistral Large 2在处理一些标准任务时的表现。按照惯例,我们首先会提出几个较为简单或者说近乎玩笑的问题来进行测试。第一个问题就是:“吃健胃消食片能否让人感到饱足?”尽管这个问题有些古怪,但它本身并没有太多的解释空间,因此,只要模型能够认真回答,通常情况下是不会出错的(除非它产生了不切实际的回答)。

然而,对于下面这类荒诞不经的问题,情况则有所不同。
既然快递需要三天时间才能送达,为什么不能提前三天寄出所有包裹呢?
在这种情况下,大型语言模型显得过于老实,未能捕捉到其中的幽默成分,而是从快递公司的运营角度进行了解析。

有趣的是,Llama 3.1-405B也未能理解这个问题的幽默所在。

从这些例子中我们可以大致看出Mistral在语言理解方面的能力。现在,让我们来测试一下Mistral的逻辑推理能力,我们采用的问题如下:

与一般人的解题方式相同,Mistral Large 2在解答此题时采用了假设法,首先假设甲所说为真。
直到解答过程中的倒数第二行,其分析都是完全正确的;然而,在最后一行,它的回答开始变得杂乱无章。

实际上,在发现如果甲说的是真话会导致丁的身份产生矛盾时,我们就可以推断出甲并没有说实话。再加上甲声称自己并非小偷,答案就已经相当明显了。然而,Mistral Large 2 仍然坚持对所有四种假设进行全面分析。
对于假设乙说真话的部分分析是正确的,但这并未能直接导向结论。

当分析到丙的部分时,其回答显得有些杂乱无章……

不过,在完成对“丁说真话”这一假设的分析后,最终得出了正确答案:甲就是小偷。

整体来看,Mistral Large 2 在处理这类问题时具备一套合理的解决方案。但与人类相比,该模型在解决问题时缺乏灵活性,过于遵循既定步骤,并未在发现甲说谎时直接得出结论,同时在推理过程中还出现了一些细节上的错误。
值得一提的是,GPT-4o 和 Claude 3.5 都未能正确解答这个问题,且各自犯了不同的错误。

以上便是关于这个开源模型最新状态的实际测试内容。如果你感兴趣,可以亲自访问 Mistral 的官方对话平台 Le Chat 进行体验。
链接如下: https://chat.mistral.ai/chat
参考链接: 1. https://x.com/mistralai/status/1816133332582703547?s=46 2. https://x.com/guillaumelample/status/1816135838448972240?s=46 3. https://x.com/DrJimFan/status/1816231047228797132 4. https://x.com/kimmonismus/status/1816141604194857430?s=46
亮点概述:
- 更快、更开放:Mistral推出了一个全新的开源模型。(图片:/assets/111-e1620290478548-300x175.png)
- 破纪录的文本处理能力:该模型在40万文本处理上创造了新纪录。(图片:/assets/WechatIMG3040-e1699239725538.png)
- 百万美元保护基金:为支持开源社区,设立了一项100万美元的保护基金。(图片:https://chat-ex.com/assets/4954996409.png)
- 兼容性扩展:此模型还支持MLX和tinygrad,并且正在适配llama.cpp。(图片:https://chat-ex.com/assets/464714295.png)
- 多媒体输入支持:除了文本,该模型还能处理图像和视频输入。(图片:/assets/2024-04-04-12.55.28-e1712207079585-300x175.png)
- 更多功能:(图片:/assets/屏幕快照-2019-08-24-下午1.29.47.png)


















