Llama3.1平均每训练3小时就会出现一次故障,H100万卡集群显得十分脆弱,甚至连气温的波动都会影响其吞吐量。
编辑日期:2024年07月29日
最近,有人在Meta发布的长达92页的Llama 3.1论文中发现了一些亮点:

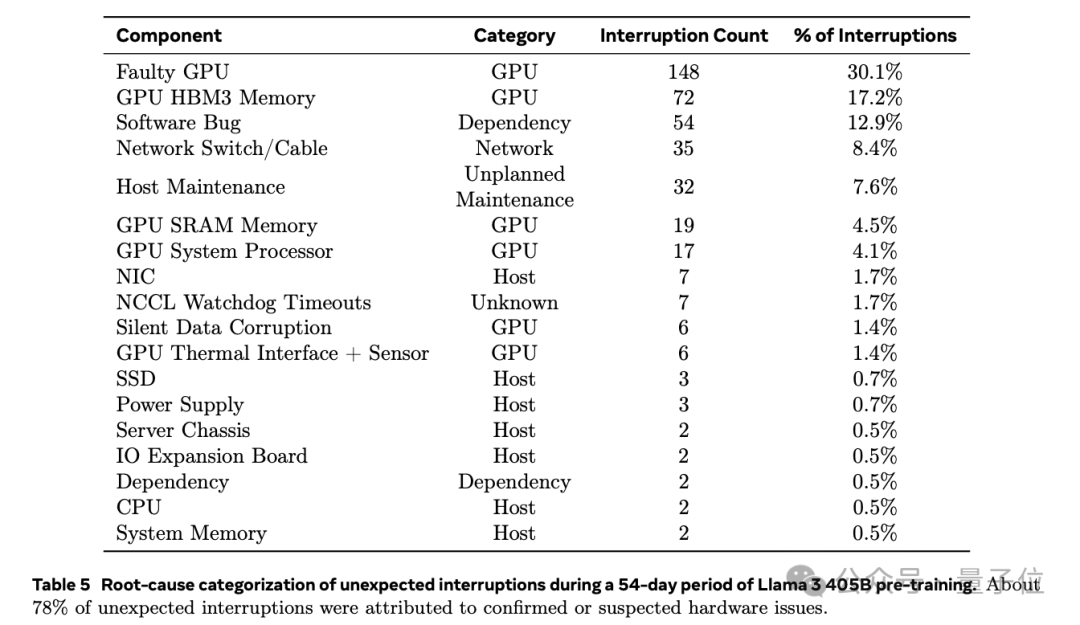
在为期54天的预训练期间,Llama 3.1总共经历了466次任务中断。其中,只有47次是计划内的,而其余的419次都是意外发生的。在这些意外中断中,已确认或怀疑有78%是由硬件问题引起的。
而且,GPU的问题最为严重,占比达到了58.7%。
Llama 3.1 405 模型是在配备有16384个Nvidia H100 80GB GPU的集群上进行训练的。常言道,对于大型系统而言,唯一可以确定的是总会出现故障。
但这个问题 still 还是引起了众多网友的关注。
或者
但这个问题依然引起了众多网友的关注。
具体来说,在419次意外中断中,有148次(占30.1%)是由各种GPU故障(包括NVLink故障)引起的,而72次(17.2%)明确是由HBM3内存故障导致的。
考虑到H100的高功耗700W以及高的热应力,出现这样的结果并不出人意料。
有趣的是,在54天内,只有两次问题是由于CPU故障引起的。
除GPU外的另一半故障是由多种因素引起的,例如软件Bug、网络电缆等问题。
不过最终,Llama 3.1 团队保持了超过 90% 的有效训练时间。只有三次故障需要人工大量介入处理,其余的都实现了自动化处理。
那么,他们是如何应对的呢?
为了增加有效的训练时间,Llama 3.1团队表示他们已经减少了任务启动和检查点的时间,并且开发了一些工具以便更快地诊断和解决问题。
其中大量运用了PyTorch内置的NCCL飞行记录器(由Ansel等人于2024年开发),这一功能能够将集体元数据和堆栈追踪记录至循环缓冲区中,从而实现对大规模停滞及性能问题的快速诊断,尤其是与NCCLX相关的问题。

通过使用此工具,团队可以有效地记录每次通信事件和每个集体操作的持续时间,并且在NCCLX监视程序或Heartbeat超时的情况下,能够自动导出跟踪数据。
还可以根据需要,采用在线配置更改的方法(如 Tang 等人在 2015 年提出的方法),选择性地开启某些计算密集型的追踪操作和元数据收集,而且无需重新发布代码或重启任务。

团队指出,在大规模训练中排查问题是十分复杂的,这是因为网络同时利用了NVLink和RoCE技术。通过NVLink传输数据通常是借助于CUDA内核发起的加载/存储操作完成的。如果远程GPU或NVLink连接出现问题,通常的表现是CUDA内核中的加载/存储操作被卡住,但并不会返回明确的错误代码。
NCCLX 通过与 PyTorch 的紧密协作,提升了故障检测和定位的速度及准确性,使得 PyTorch 可以访问 NCCLX 的内部状态并追踪相关的信息。
虽然无法完全避免因 NVLink 故障引起的卡顿现象,但系统会监控通信库的状态,在检测到卡顿时自动触发超时机制。
此外,NCCLX 还将监控每一次 NCCLX 通信中的内核及网络活动,并在出现故障时提供 NCCLX 集体操作的内部状态“快照”,内容涵盖各等级间已完成及待处理的数据传输情况。团队通过分析这些数据来排查并调试 NCCLX 的扩展问题。
有时候,硬件问题可能会导致某些部分虽然看似仍在运行,但速度却减慢了,这种情况很难被察觉。即便只有一个小部分变慢,也可能拖累成千上万个其他GPU的速度。
为此,团队开发了一些工具,可以优先处理某些可能存在问题的进程组通信。通常只需调查几个最可疑的对象,就能有效地找出那些运行变慢的部分。
团队还观察到一个有趣的现象——环境因素会影响大规模训练的表现。在训练Llama 3.1 405B模型时,系统的吞吐量会根据一天中的不同时间出现1-2%的变化。这是因为中午的高温会影响到GPU的动态电压和频率调节。
在训练过程中,可能有数万个GPU同时增加或减少功耗,例如在所有GPU等待检查点(checkpointing)或集体通信完成时,或者在整个训练任务启动/关闭时。这种情况可能会导致数据中心的瞬时功耗波动达到数十兆瓦,这对电网来说是一个相当大的挑战。
团队最终还表示:

Meta在2022年首次公开了其人工智能研究超级计算机(RSC)的详细信息,该系统当时配备了16,000个NVIDIA A100 GPU,助力构建了第一代的人工智能模型,并在Llama初代及Llama 2的开发过程中扮演了重要角色。
△ 来自 Meta
(注:原文似乎不完整,不确定需要如何用中文重写。如果是指某个内容或信息来自Meta,可以翻译为“来自Meta”。如果有更多上下文信息,可以提供更准确的翻译。)
今年三月,Meta公开了一个由24576个NVIDIA H100 GPU组成的AI集群,该集群支持Llama 3及后续的模型。
更设定了到今年年底增加350,000个NVIDIA H100 GPU的目标,作为总体算力的一部分(总体算力接近600,000个H100 GPU)。

这么大的规模,嗯嗯嗯,确实不是一个持续性的简单挑战。当然,大型AI集群给模型训练带来故障这问题,算是有点“古老”了,早在很久以前就已经有相关的研究了。
H100 的含金量本身无需多言。

在去年最新的MLPerf训练基准测试中,NVIDIA的H100集群席卷了八项测试,并全部创下了新的记录,尤其在大型语言模型任务中的表现格外突出。

在11分钟内完成GPT-3的一轮训练,而BERT的训练仅需8秒。在大型语言模型的任务中,H100集群的加速性能接近线性增长,也就是说,随着集群中处理器数量的增加,加速效果也几乎以同等比例增加。
这意味着在集群内的GPU之间的通信效率非常高。

此外,H100 还完成了包括推荐算法、计算机视觉(CV)、医学图像识别和语音识别等任务,它是唯一一个参与了全部八项测试的集群。
不过,SemiAnalysis 一个月前的一篇文章指出,构建大型的人工智能算力集群是非常复杂的,远不止于是否有足够的资金购买显卡的问题。
在电力、网络设计、并行性、可靠性等许多方面都存在着局限性。

参考链接:
注意:您未提供需要重写的具体内容,仅重写了“参考链接”部分。若需重写其他内容,请提供详细信息。
本文出自微信公众号:量子位(ID:QbitAI),作者:西风
大家在看