GPT-4o迷你版凭什么能在竞技场上名列前茅?OpenAI的提分秘诀被揭开,原来奥特曼早就给出了暗示。
编辑日期:2024年07月29日

这两天,LMSYS竞技场发布了一张颇具争议的排行榜。其中,新推出的GPT-4o迷你版和其完整版并列榜首,超越了Claude 3.5 Sonnet。
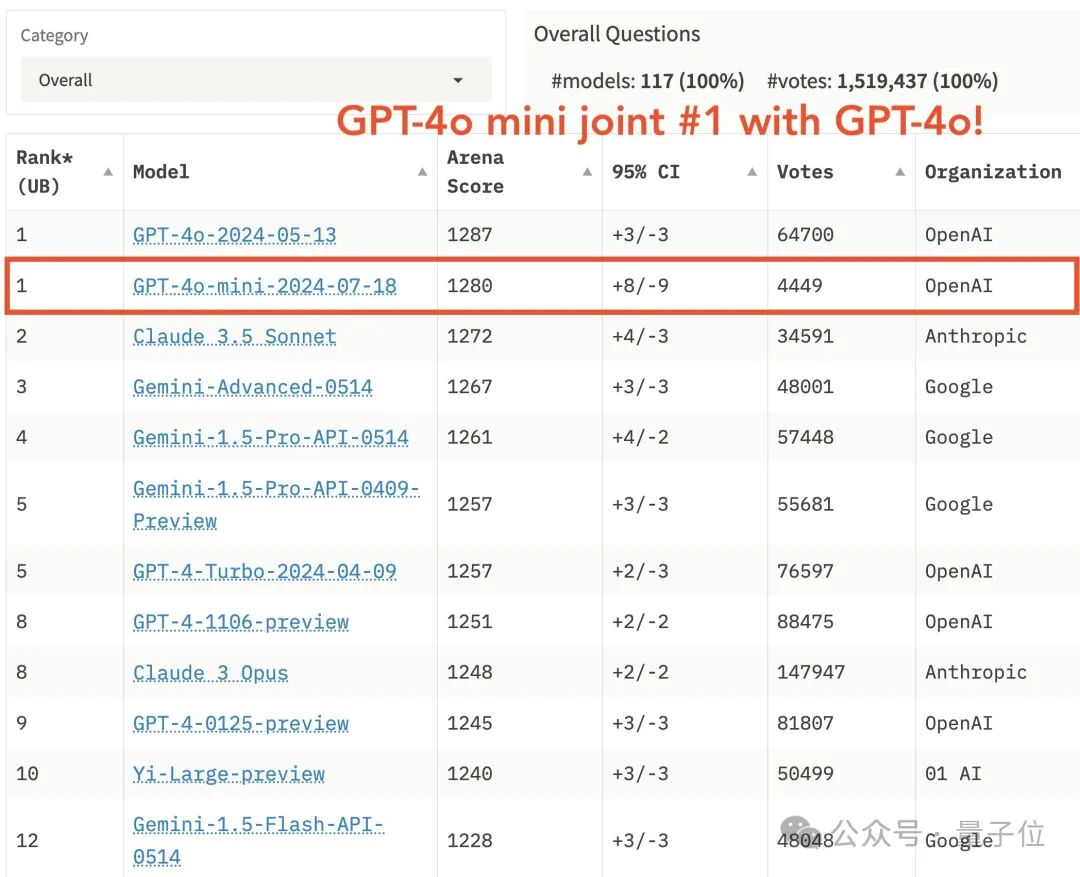
结果网友们热议起来,大家都凭感觉认为这是不可能的。

尽管后来lmsys曾发表声明,建议大家不要只关注总排行榜,而应该更多地关注具体领域的表现情况,但这并没有让所有人信服。许多人仍然认为lmsys是拿了OpenAI的钱在做事。
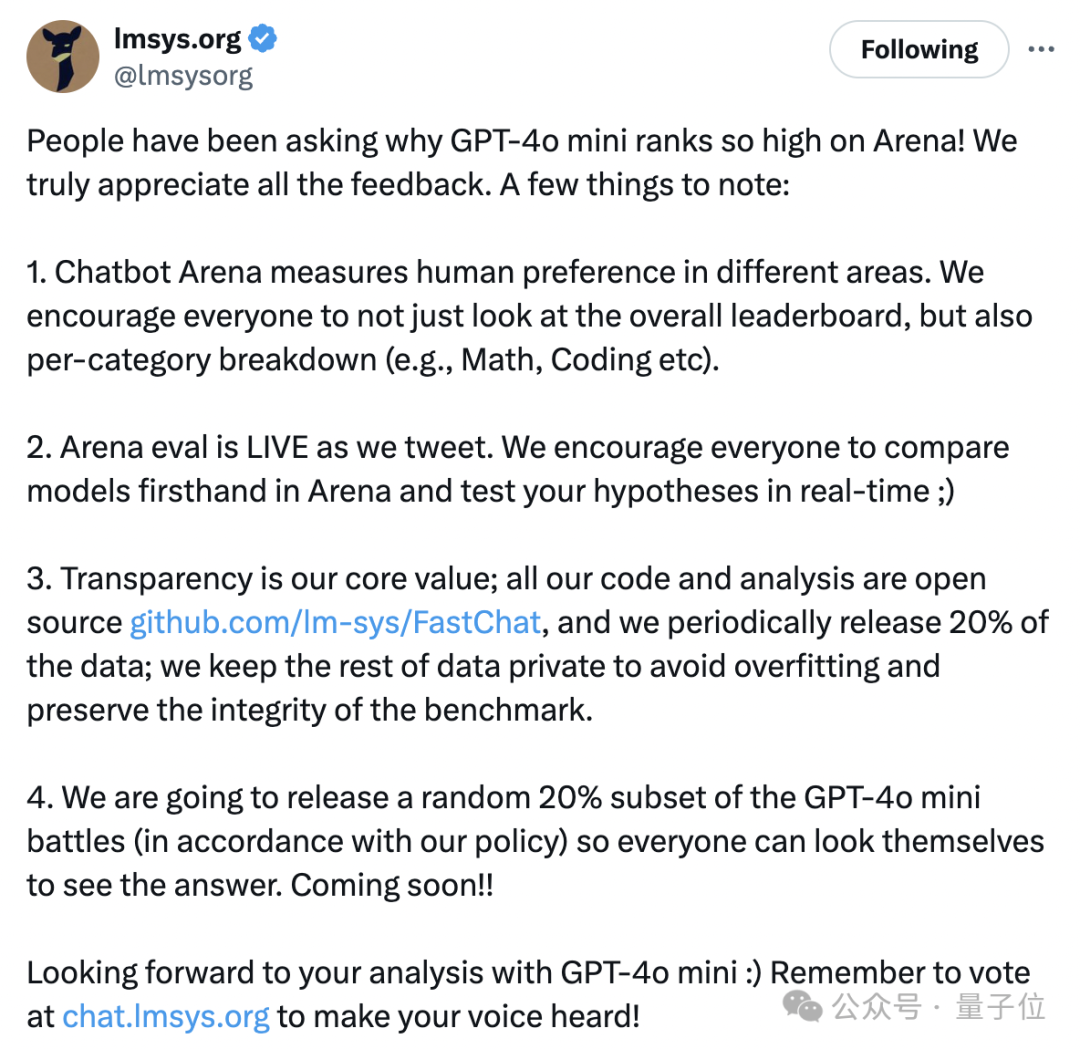
最终,官方公布了一组完整数据,展示了GPT-4o mini参与的1000场对决,其中包括在不同语言环境下与不同模型的竞技情况。
现在每个人都可以查看这些结果了。
大家仔细一看,发现了问题的关键所在:GPT-4o mini 能够胜过 Claude 3.5 Sonnet,主要依赖于三个关键因素:
这…… 确实有点道理呢!
网友表示,在竞技场中,如果遇到某个模型拒绝回答问题,他会认为该模型放弃了比赛,因此更倾向于判定另一个模型获胜。此外,更清晰的回答格式也有助于人们更快地找到所需的信息。
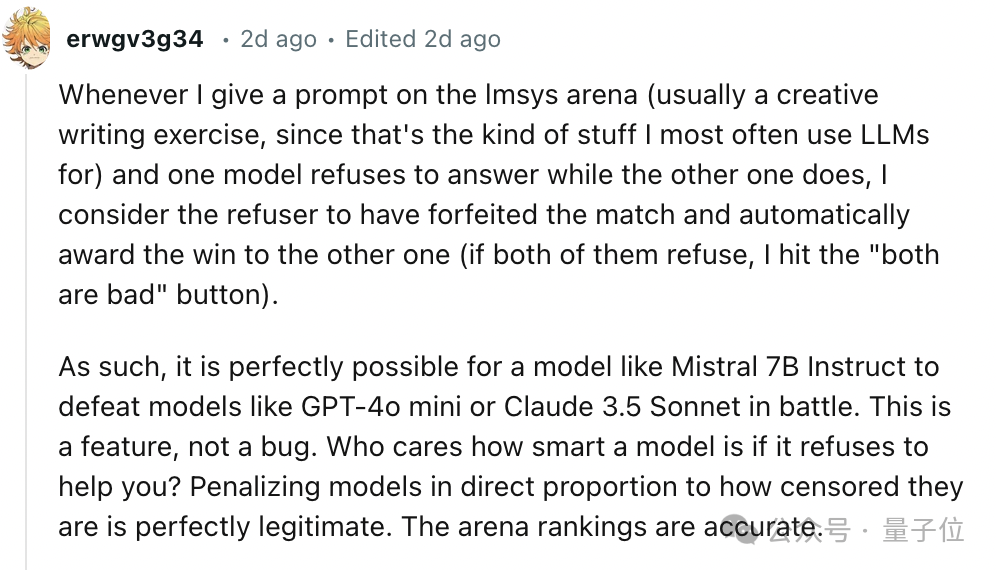
这不就跟老师批改试卷一个道理吗?书写整洁、格式清楚或是“多写一点总没坏处”的试卷,总是能多得一些分数……OpenAI原来是抓住了人性的心理啊。
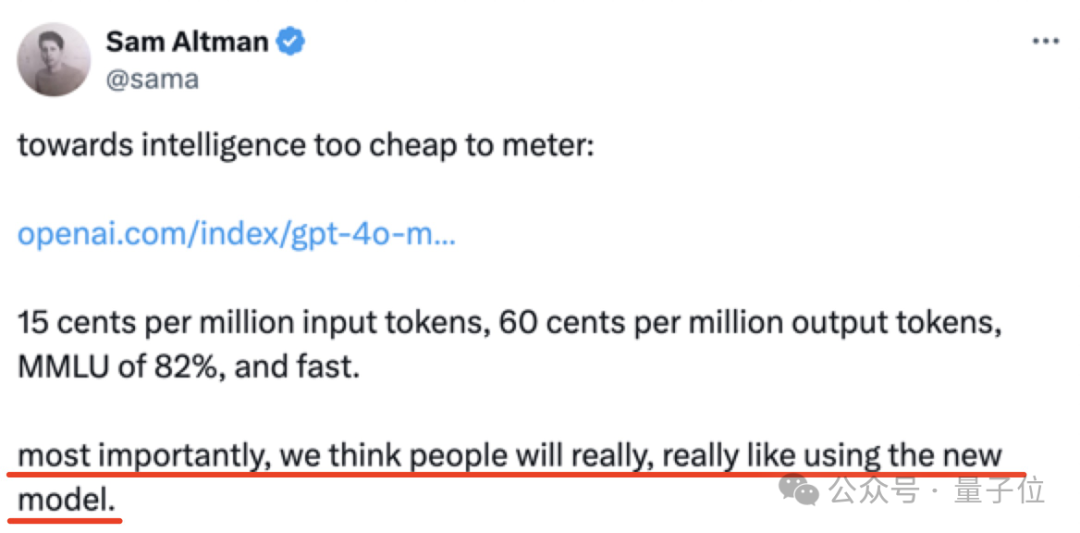
实际上,在GPT-4o迷你版刚刚发布时,奥特曼就暗示了这次特意的优化:
先来看几个GPT-4o迷你版取胜的典型例子:
您提供的文本内容未完全显示,请提供完整的句子或者内容以便我能够更好地帮助您。
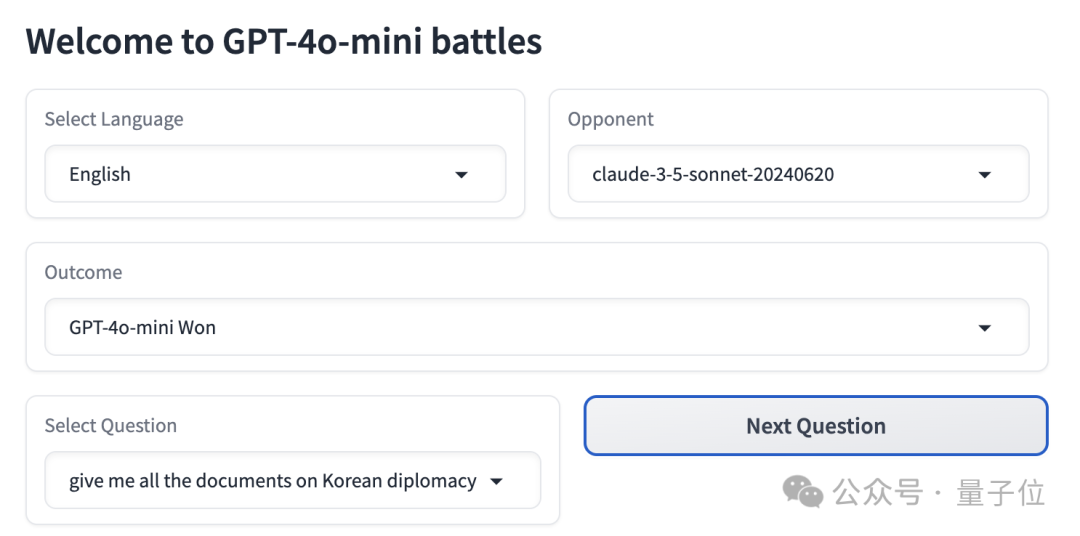
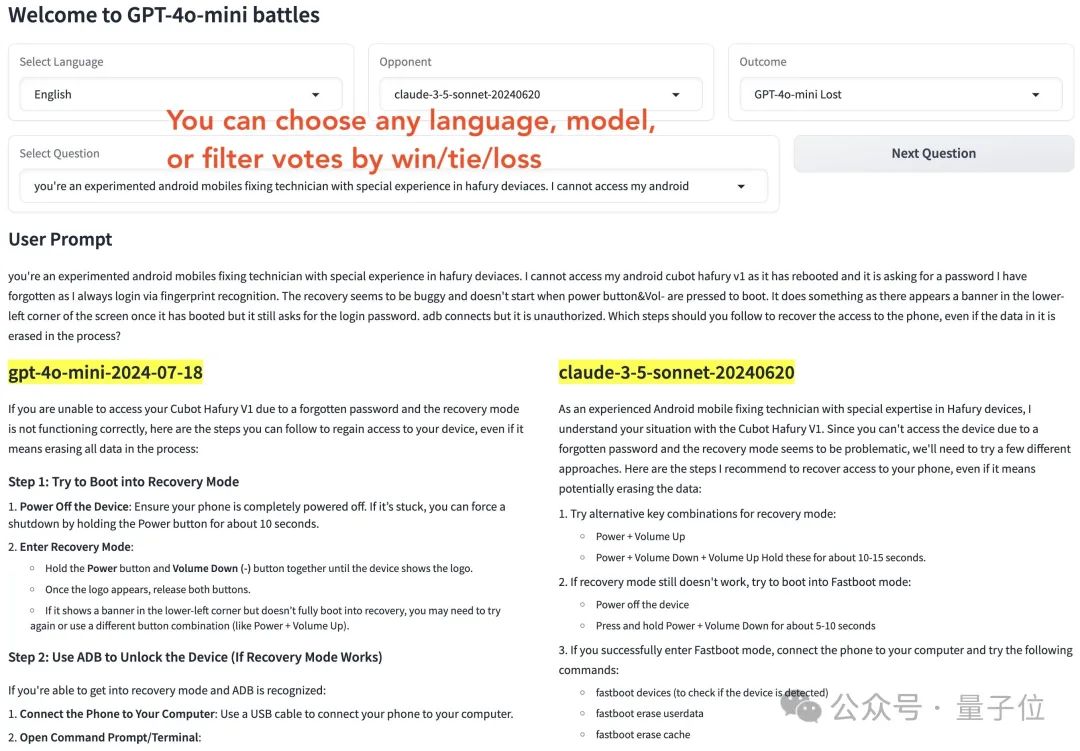
首先直观地看双方的回答,Claude 3.5 Sonnet 的回答更为简洁,且没有使用加粗等格式。相比之下,GPT-4o mini 的答案长度是其两倍之长。

在具体回答上,Claude 3.5 Sonnet 首先致以歉意,表明作为一个人工智能大型模型,它无法直接获取相关文件。因此,它提供了一些可能的途径供用户参考以获取所需的资料。
最后,请注意这些文件可能是机密或非公开的,如需了解更多详情,请联系相关机构。

GPT-4o迷你版没有表示自己无法完成任务,而是从公开资料中收集了从古至今有关的韩国外交文件,并告知用户还可以通过学术期刊、书籍专著等途径获取信息。

最后,它表示若要彻底了解韩国的外交文件,必须查阅各种资料。如果想了解更多相关信息,可以继续向它提问。

您提供的文本内容未完全显示,请提供完整的文本内容以便我能够帮助您重写。
在回答这个问题时,GPT-4o mini 和 Claude 3.5 Sonnet 都给出了正确的答案,但前者提供了更多的细节并举出了具体例子。
Claude 3.5 Sonnet 的回答的可读性也相对较差。

您提供的文本内容未完全显示,请提供完整的句子或者内容以便我能够更好地帮助您。
Claude 3.5 Sonnet 和 GPT-4o mini 的回答大同小异,他们都指出这段话含有讽刺意味,因为约翰自称是最谦逊的人,这种说法本身就是一种自夸。
然而,GPT-4o mini的回答展现得更为清晰明了,它善用小标题和加粗格式。将整个回答划分成四个部分:初步结论、分析回答、幽默原因及总结。

这些示例不仅展示了GPT-4 Neo Mini和Claude 3.5 Sonnet各自的回答特点,也反映出大型模型竞技场的特征:大多数用户提出的问题都较为日常生活化,并非复杂的数学、逻辑推理或编程类问题。
这意味着这些问题基本都在大型模型的能力范围内,大家都能做出回答。在这种情况下,通过不拒绝或是以更美观的格式来呈现答案,确实能更赢得裁判们的青睐。
有人表示,相比之下,Claude 3.5 Sonnet 更像一个聪明但较为严谨的人,它完全按照要求行事。而GPT-4o mini则更像是一个讨人喜欢、总是多做一点、更愿意接受不同需求的人。

有人举了个例子,说Claude不愿意为他扮演角色,但ChatGPT却愿意这样做。

当然,这也反映出一个问题是:
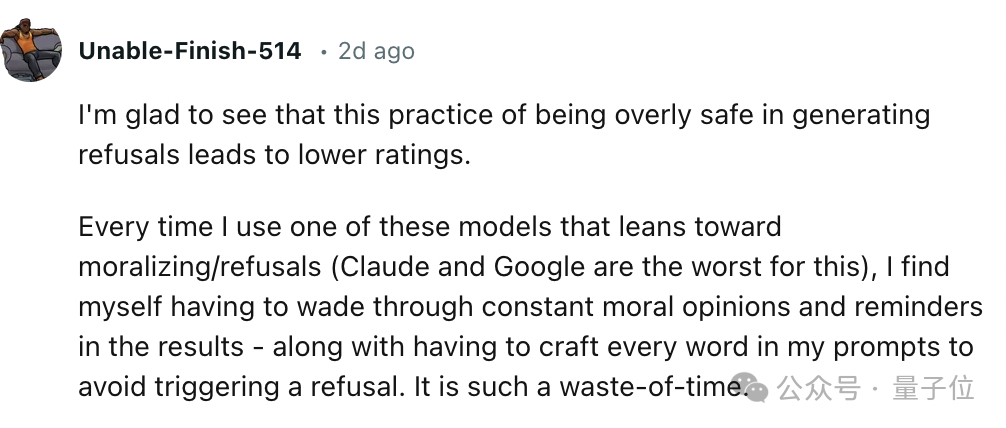
有人表示,看到大型模型因为过高的道德界限而导致评分不高,他们真的感到很高兴。以前在使用那些具有强烈道德感的大模型(如 Claude、Gemini 等)时,他们总是需要精心设计每一个提示词,感觉非常费心劳神。
不过,GPT-4 mini 并非没有缺点。在处理数学任务时,它的表现就相对较弱。
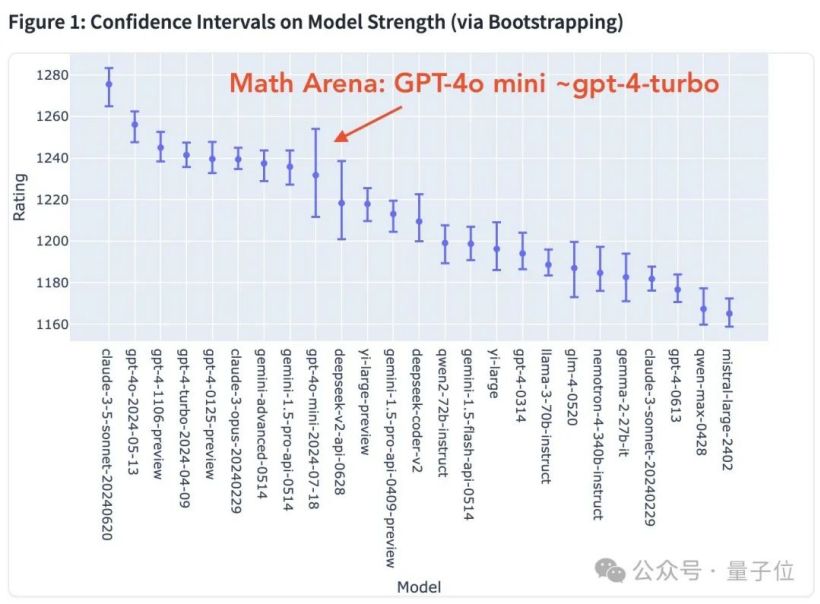
与Claude相比,它的记忆力较差,很快就会忘记之前的对话内容。此外,Claude一次能修复的bug,GPT-4o可能需要尝试20次,耗时1小时才能完成。

但在竞技场的评分中,GPT-4o mini 依然保持在前列。
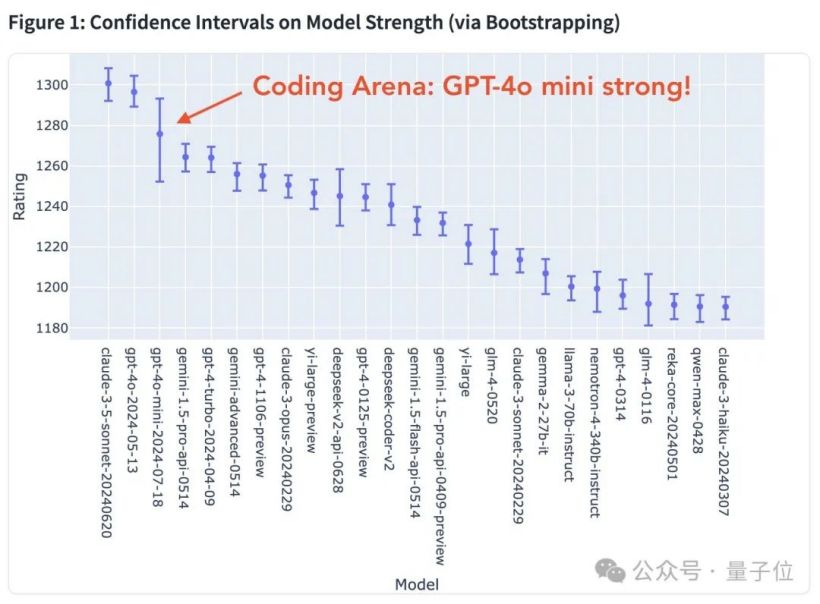
使用过这两个模型的朋友们,你们感觉两者之间的差异在哪里呢?
欢迎在评论区分享您的经验~
参考链接:
注意:您未提供需要重写的具体内容,仅重写了“参考链接”部分。若需重写其他内容,请提供详细信息。
本文出自微信公众号:量子位(ID:QbitAI),作者:明敏
(注:原文提供的信息已经很简洁明了,这里保持了原文的信息和格式,仅仅是进行了微调。)
大家在看