苹果AI版iOS首日大热:聊天瞬间提升情商,大型模型成为最强大的语言助手,Siri实现华丽转变。
编辑日期:2024年07月30日
随着iOS 18.1 Beta版的发布,注册开发者从现在起可以开始体验苹果AI的部分功能。其中最显著的变化是Siri的全面更新,它已转变为Apple Intelligence & Siri。
另一项重要的更新是其写作功能,它能够帮助你润色推特评论,快速地使用上各种高级表达方式。
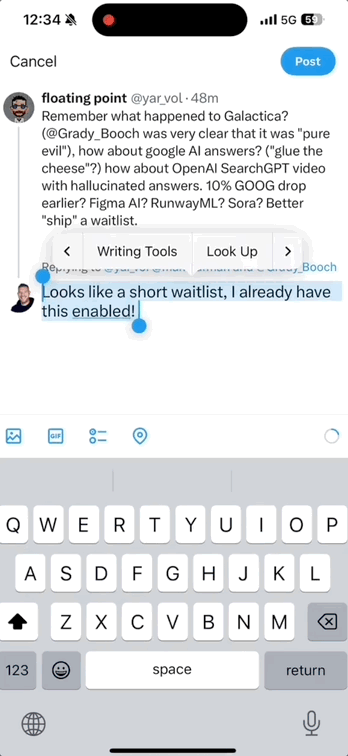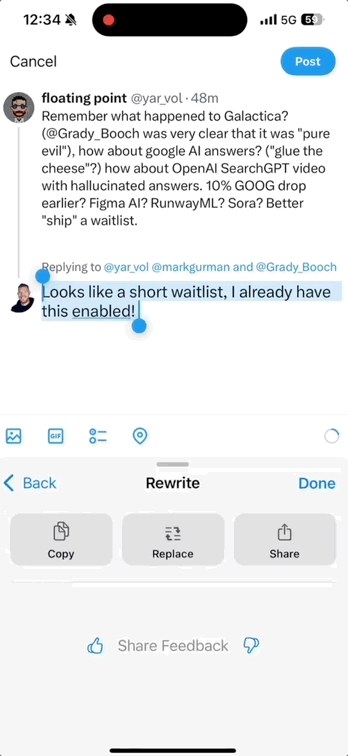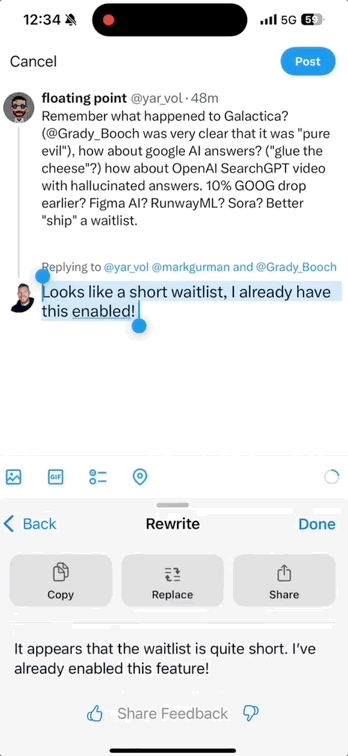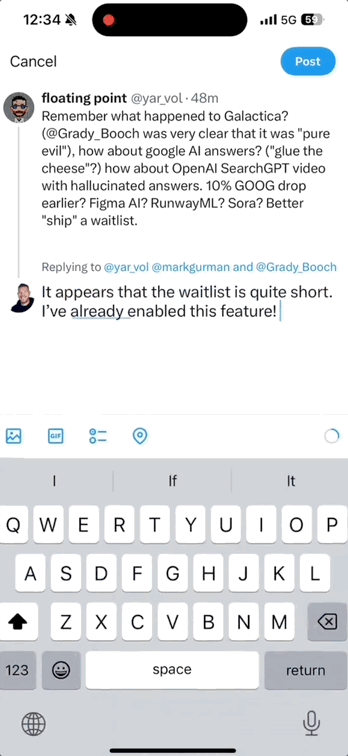
即使是粗话,也能在瞬间变得文雅随和:
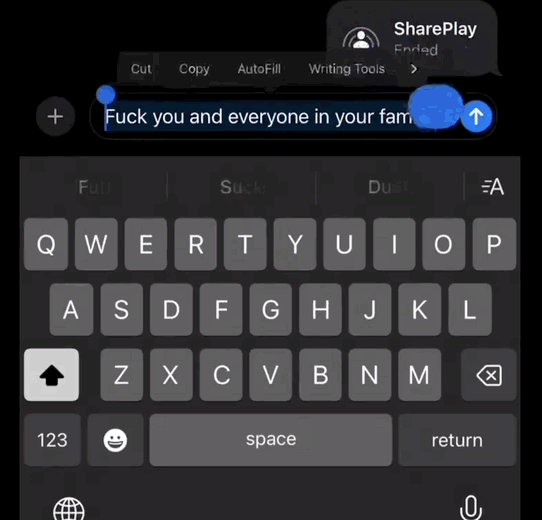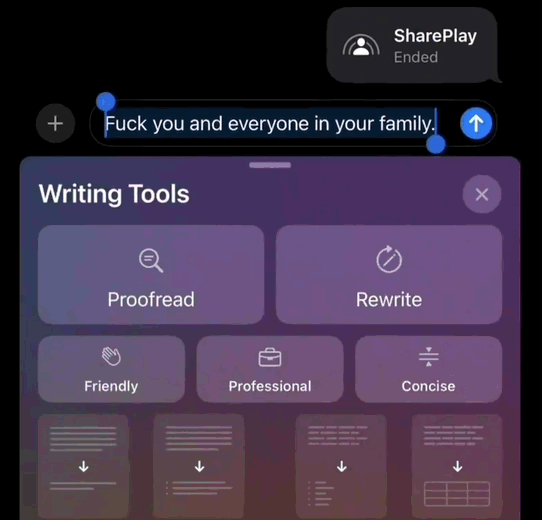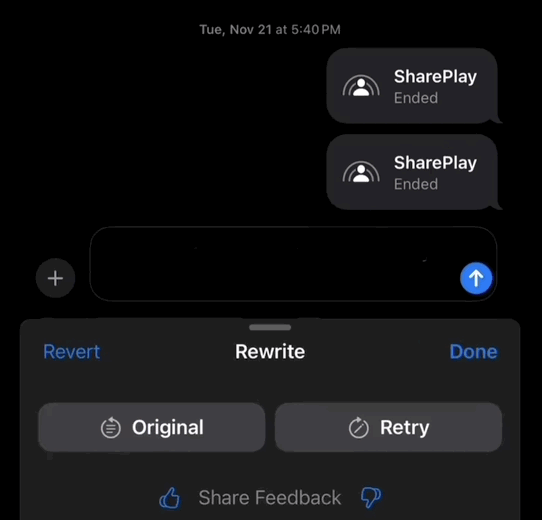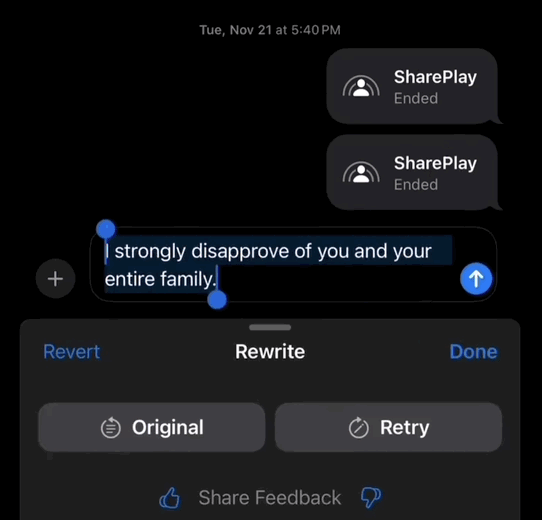
启用 Apple Intelligence 后,苹果自主研发的大型端侧模型将会下载到您的设备中。

根据一些反应迅速的网友的体验反馈,我们的AI不像其他家的AI那样经常出现拒绝服务的情况。
同时,苹果自家的大模型报告也已经发布,透露了大量的技术细节。根据报告显示,在指令遵循、文本总结等任务中,苹果的云基大模型的表现超过了GPT-4。
苹果基础大模型团队的负责人庞若鸣(Ruoming Pang)也表示,他们的模型与一些同类的最佳模型相比具有竞争力。

庞若鸣拥有普林斯顿大学计算机博士学位,本科及硕士学位分别来自上海交通大学与南加州大学。他在2021年加入苹果公司,在此之前,他在谷歌担任工程师长达15年。
Apple Intelligence 的主要对话功能是由他领导的团队研发的模型所提供支持的。
这次他还特别强调,这些基础模型“并非仅仅是聊天机器人”,它们支持广泛的功能,包括内容摘要、写作辅助、工具运用以及代码编写等。

此外,苹果还开发了许多自家的算法,以提升模型的表现,这些具体信息都在报告中有所披露。
还有细心的网友发现了其中的亮点 —— 苹果的大模型训练使用了谷歌的TPU集群,而并未使用任何英伟达的产品。

要体验苹果的 Apple Intelligence,需要满足多个条件。
首先,目前搭载它的 iOS 18.1 Beta 版本仅限于每年支付99美元的注册开发者使用,因此普通用户还需要等待一段时间。
还有,就像之前提到的,仅支持M系和A17 Pro芯片,这意味着在iPhone中,只有特定地区的一部分15 Pro和15 Pro Max可以使用。
除了硬件和身份要求外,还需要修改系统设置,包括将地区设置为美国,以及将设备和Siri的语言都改为英语。
在满足所有这些要求后,就可以加入等待队列了。

此次发布的是Apple Intelligence的部分功能,主要集中在文本生成、Siri和相册这几个模块。
首先来说文本生成,作为苹果AI的重要组成部分,这一功能的应用范围并不局限于苹果官方应用程序。
只要采用标准输入文本系统,就可以在第三方应用程式中使用该功能进行文本总结、校对及重写。
此外,结合iOS 18 Beta版中的语音备忘录已推出的音频转文本功能,文本生成系统还能为录音创建摘要。
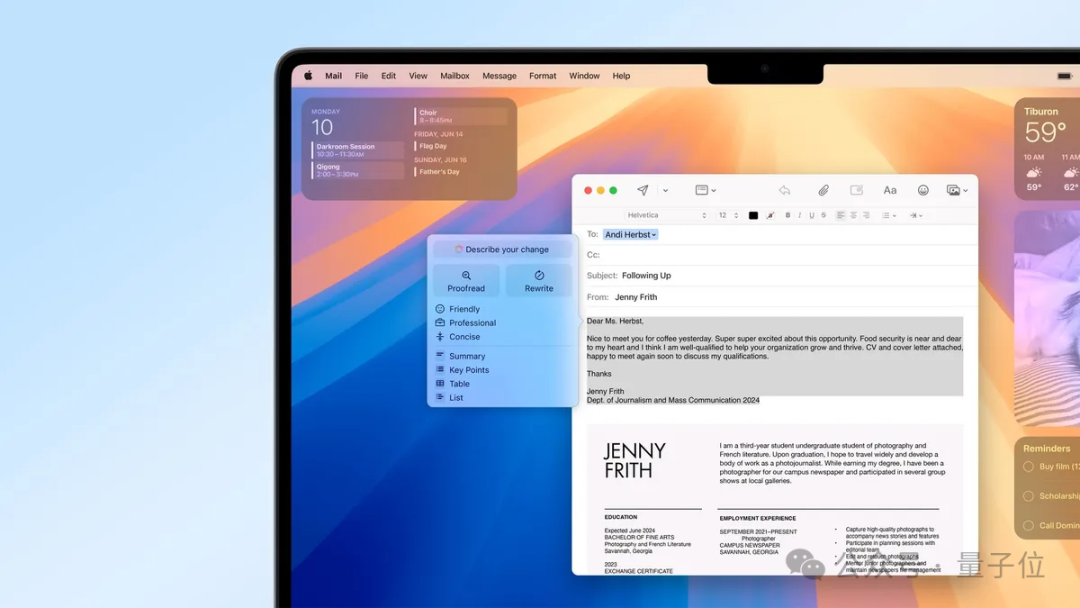
第二个较为重要的更新是关于Siri的。在界面设计上,新的Siri不再显示为一个圆形图标,而是在运行过程中会有环绕屏幕的彩色光线不停闪烁。此外,对于不想使用语音交互的用户,系统还提供了一种文本对话模式:只需双击屏幕底部就能调出键盘,实现与Siri的文字交流。
在内容方面,新的Siri将能够回答与苹果产品相关的问题,并帮助用户进行故障排除。
此外,新的Siri能够理解从一个查询到下一个查询的上下文,例如,先让Siri创建一个日历事件,然后再要求创建一个提醒,过程中无需重复说明正在讨论的内容。
然而,之前介绍的屏幕感知功能并未包含在这次的Siri更新中。
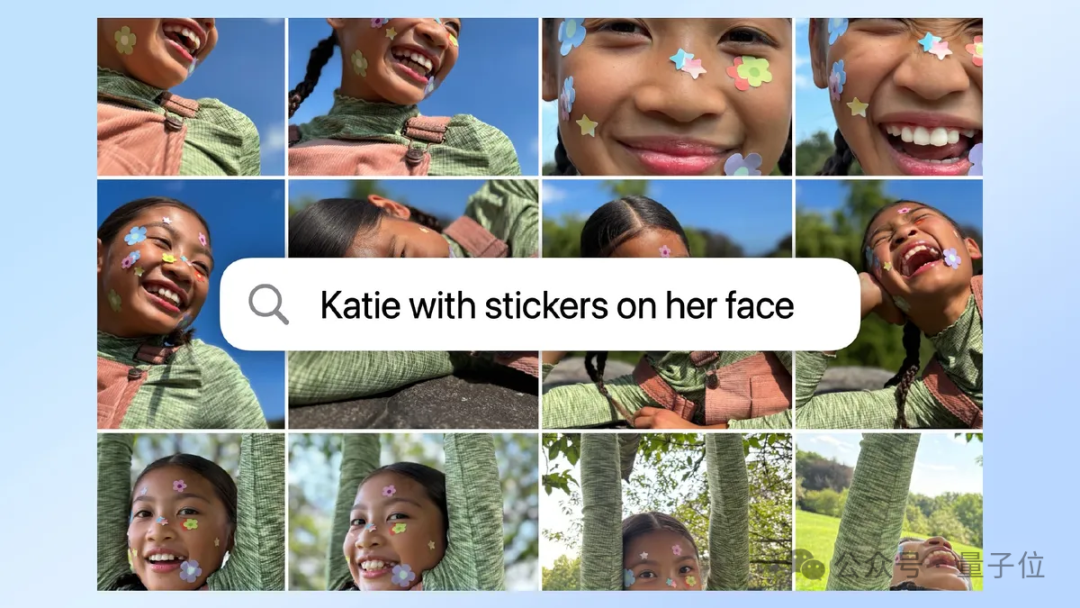
相册的更新允许用户使用自然语言来搜索特定的照片,甚至是视频中的具体时刻。
以上就是本次开发者测试版本中关于AI的大致内容。需要指出的是,这仅是之前发布会上展示功能的一部分,还有许多功能尚未上线。
特别地,本次更新尚未接入之前提到的ChatGPT集成。
苹果曾表示,ChatGPT 并非其人工智能产品中的必备选项,其主要功能将由自家大型模型驱动。与此同时,苹果也发布了一份详尽的技术报告来介绍这个模型。
模型的命名直截了当,被称为苹果基础模型(Apple Foundation Model,简称 AFM),它包含两个版本:设备端(on-device)和服务器端(server)。设备端模型的大约参数量为30亿左右,而服务器端的具体参数量并未透露,只知道它比设备端更大。这两个版本都具有32k的上下文窗口。
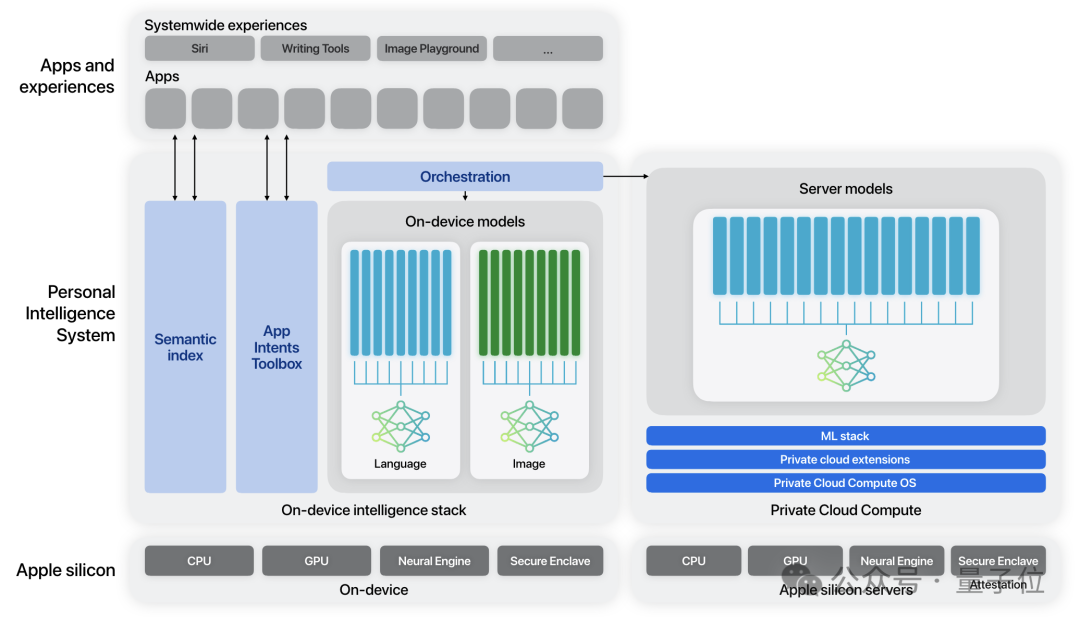
模型的训练是通过我们自己基于 JAX 的 AXLearn 框架来进行的,并采用了包括张量并行和流水并行在内的策略。
硬件方面采用的是谷歌的TPU,具体来说,云端使用了8192颗TPUv4芯片,而客户端使用了2048颗TPUv5p芯片。总之,整个系统中并没有使用任何英伟达的产品。

数据主要来源于通过Applebot爬取的网页,以及具有公共许可的代码和数学数据集。
值得一提的是,苹果选择的数据集没有一个使用GPL,而是都采用了开放程度更高的开源协议,如MIT、Apache和CC0。
在流程上,AFM的预训练过程分为三个阶段——核心训练、继续训练和上下文延伸。
在核心训练阶段,云侧版本的数据量为6.3T tokens,窗口长度为4096。端侧版本则是基于此通过蒸馏过程获得。
在继续训练的过程中,低质量数据的权重会被减少。同时,利用数学方法和代码,并结合已授权的高质量数据来提升模型的性能。
该过程采用了1T个令牌的数据,窗口长度也从4096增加到了8192。
在接下来的阶段中,窗口长度将进一步扩展到 32k,涵盖长达序列的文本和合成数据,总共有 100B 个令牌。
AFM 的后期训练包括了指导性监督微调(SFT)、以及基于人类反馈的强化学习(RLHF)等环节。在 SFT 阶段,采用的数据包括合成数据及人工标注数据,其中合成数据主要涉及数学、工具应用和编程代码等领域。进入 RLHF 阶段后,苹果开发了两种独特的强化学习算法,即 iTeC 和 MDLOO。
iTeC,全称为 Iterative Teaching Committee,可以翻译为“迭代教学委员会”。这是一种用于在强化学习之后进行训练的算法,主要目标是通过多轮迭代来优化模型的表现。
其核心概念在于结合各种偏好优化算法,包括拒绝采样、直接偏好优化(DPO),从而使模型能从多种优化策略中获益,进而提升其在特定任务上的适应性和表现。
在每一次迭代中,iTeC 会从最新的模型中挑选出一组表现最优的模型,组成一个“模型委员会”。这些模型是通过不同的训练方法获得的,包括SFT、RS、DPO/IPO以及RL等。
通过收集人们对模型响应的偏好反馈,iTeC不断更新其奖励模型,并用于训练新的模型集。每收集一轮人类偏好数据后,iTeC就会更新其奖励模型,并训练新的模型集,这个过程会进行多轮迭代,逐步提高模型的性能。
MDLOO 是一种专为优化模型响应质量而设计的在线强化学习算法。作为一款在线算法,它能够在模型训练的过程中实时解码响应,并运用 RL 算法以实现奖励的最大化。这意味着该方法能让模型在训练期间持续学习并调整其策略,从而生成更加贴合人类喜好的响应。
在具体实现方面,它结合了留一法(Leave-One-Out,LOO)的优势评估器与镜像下降策略优化(MDPO)的方法,以此实现更加稳定和有效的策略更新。
为了使终端侧的模型运行更加高效,并且避免占用过多的内存资源,苹果对AFM的终端侧版本实施了量化处理。具体而言,苹果采用了一种混合精度的量化方法,根据不同部分采用了不同级别的量化精度。
苹果采用的方法被称为“调色板”策略。在调色板量化中,权重不是单独进行量化,而是被分组,让同一组内的权重共享同一个量化常数。
对于投影权重,每16列/行共享相同的量化常数,并采用K-均值算法进行4位量化。
对于嵌入层,由于它是输入和输出共享的,所以采用每通道8位整数进行量化。此外,一些相对不那么重要的层被进一步压缩至2位量化。
为了恢复量化后损失的性能,以保持模型的输出质量和准确性,苹果还引入了准确性恢复适配器(Accuracy-Recovery Adapters)。
或者稍微调整一下语序:
为了保持模型的输出质量和准确性并恢复量化后损失的性能,苹果还引入了准确性恢复适配器(Accuracy-Recovery Adapters)。
该适配器是一种小型神经网络模块,能够被插入到预训练模型的特定层中。它在量化模型的基础上进行训练,并通过微调学习如何补偿量化过程所带来的影响。
在应用了一系列优化技术之后,现在是时候验证模型的表现了。在这个过程中,苹果采用了一种结合人类评估和自动化评估的策略。
首先谈人工评估方面,评估人员编制了一系列问题,涵盖了分析推理、头脑风暴、聊天机器人等多个领域,并让模型产生相应的回答。同时,这些问题同样会被提交给其他用于对比的模型,随后评估人员会判断哪个模型的输出更优秀。
因此,无论是云端模型还是终端模型,都有至少60%的概率不会逊色于Llama 3、GPT-4等对比模型。
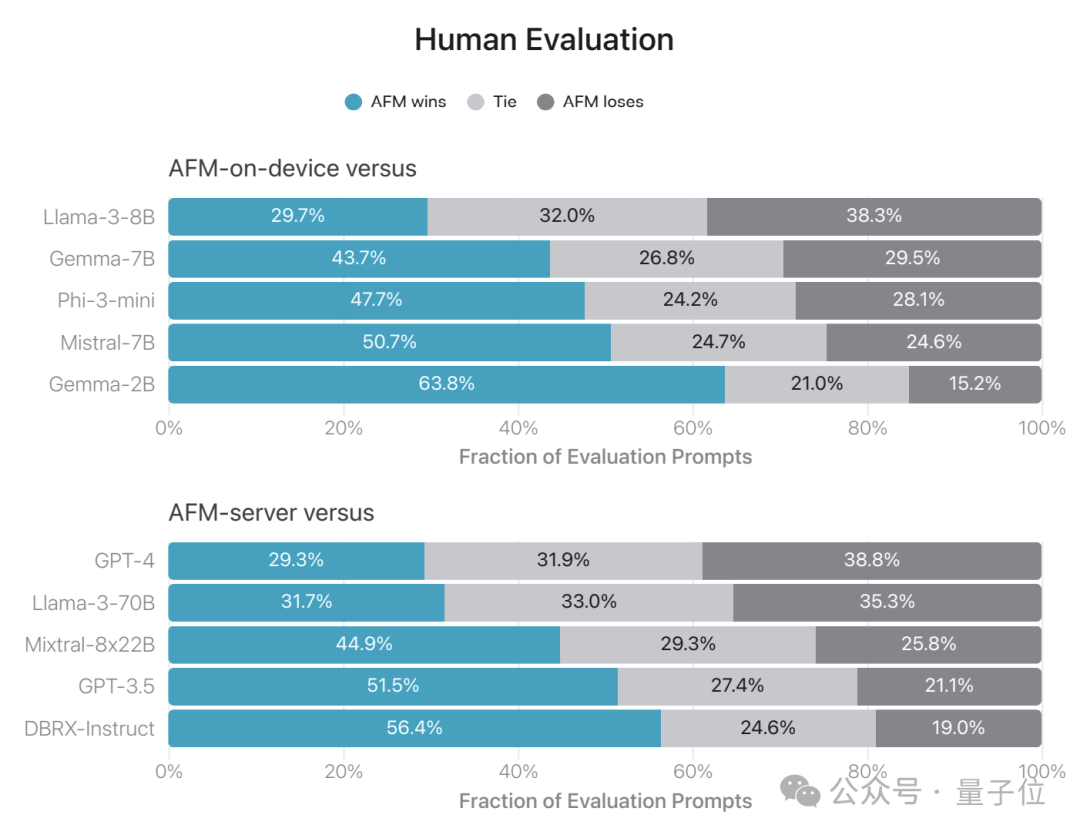
其他的测试主要通过使用数据集来实现。
在指令遵循能力方面,苹果进行了IFEval测试,测试结果显示,在指令和提示(prompt)两个层面上,云端AFM均超越了GPT-4,成为新的最先进状态(SOTA)。
端侧模型的表现超越了类似规模的模型如Llama 3-8B和Mistral-7B。在AlpacaEval评估中,无论是端侧还是云侧的AFM都获得了第二名的好成绩。
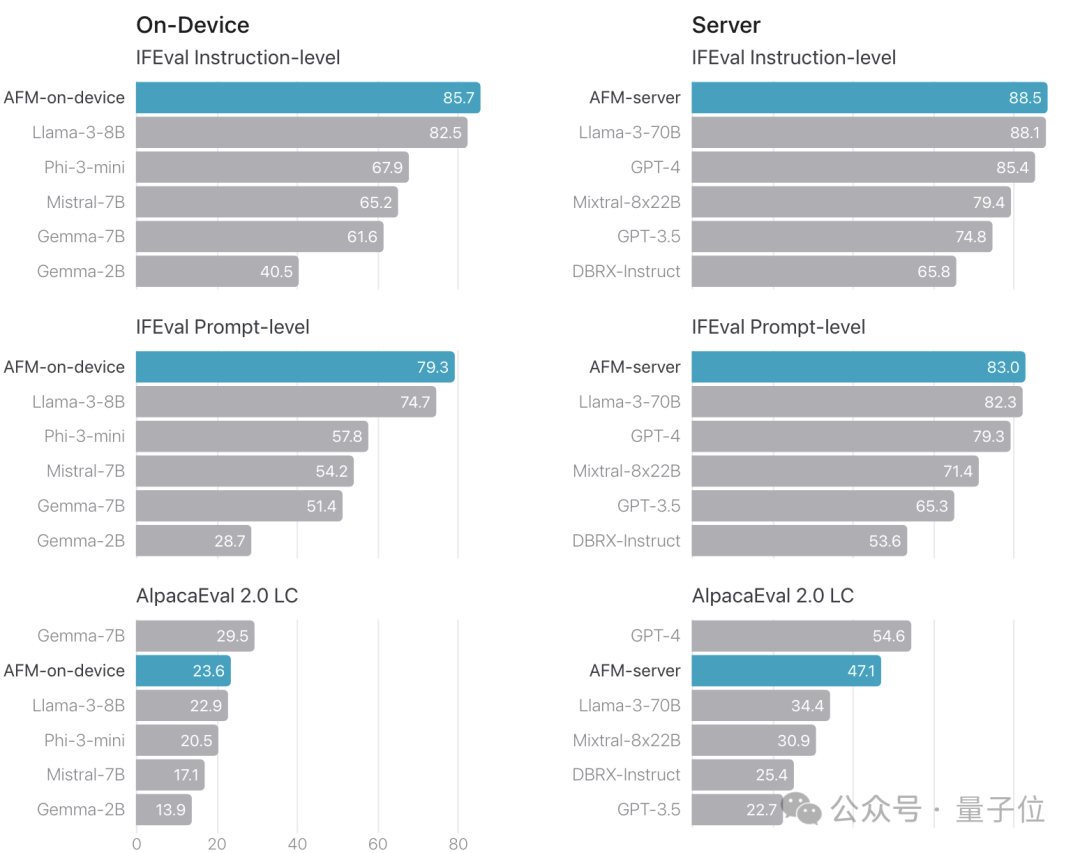
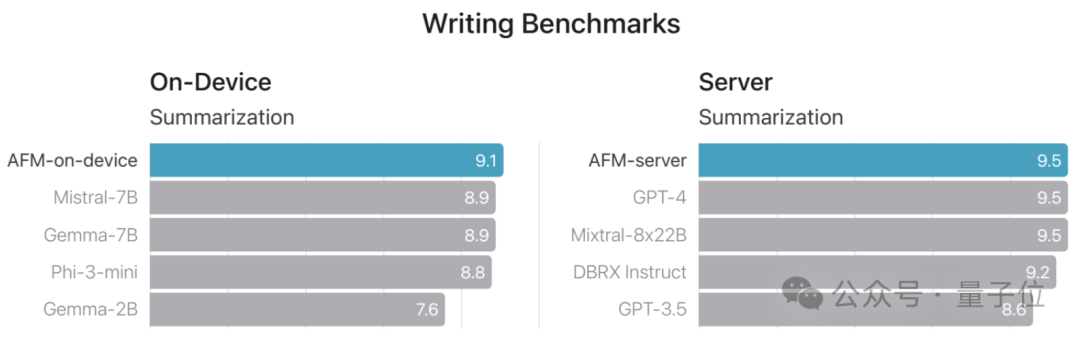
再来看具体任务上的表现,AFM在写作类基准测试中的总结任务上实现了最先进(SOTA)的表现,并且在撰写任务上也接近第一名的成绩。

在数学上,苹果已在GSM8K和MATH两个数据集上进行了评估。
结果表明,在GSM8K上,端侧模型的表现不如Llama 3-8B和微软的Phi 3 mini;而在云侧方面,则被GPT-4和Llama 3-70B超越,但表现优于GPT-3.5。
在MATH上的成绩相对较高,端侧版领先了同样规模的模型,而云侧版也超越了Llama 3-70B。

除了性能之外,安全性也是非常重要的。苹果通过人工方式评估了AFM抵御对抗性攻击的能力。评估结果表明,在面对对抗性提示时,AFM的违规率明显低于其他开源和商业模型。
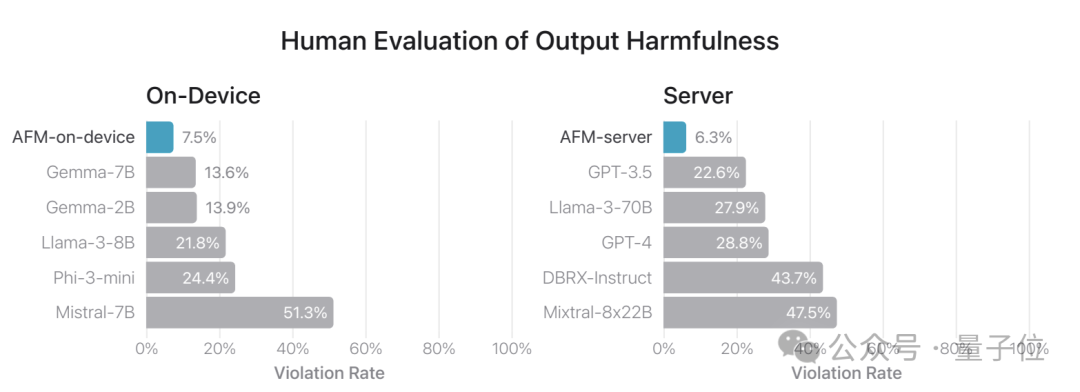
以上就是苹果大模型技术报告中一些值得关注的要点,更多详细信息可以参考报告原文。
尽管苹果智能(Apple Intelligence)已提供给开发者进行测试,但据彭博社透露,正式版本可能面临推迟发布的情况。
确实,根据苹果以往的版本发布模式,18.1的版本号也表明这些功能不会与9月的新手机发布同时推出。
对此,分析师Gene Munster建议,苹果应当考虑将iPhone 16的发布日期推迟,以保持与Apple Intelligence的一致性。
至于库克是否会考虑这些建议,我们就拭目以待吧。
报告地址:(需要具体地址内容,这里只提供了报告地址的提示,没有具体地址内容可以填写。)
如果是指要在报告中填写地址的话,就需要提供具体的地址内容了。例如: 报告地址:北京市海淀区XX路XX号XX大厦12层。
苹果公司在其机器学习研究网站上发布了关于苹果智能基础语言模型的研究:https://machinelearning.apple.com/research/apple-intelligence-foundation-language-models
参考链接:
注意:您未提供需要重写的具体内容,仅重写了“参考链接”部分。若需重写其他内容,请提供详细信息。
本文出自微信公众号:量子位(ID:QbitAI),作者:克雷西
大家在看