Meta构建分布式RoCEv2网络:探索连接数万块GPU以训练拥有千亿级别参数的AI模型
编辑日期:2024年08月06日
RoCEv2 的完整名称是 RDMA over Converged Ethernet version 2,它是一种用于节点间通信的传输方式,主要用于大部分的人工智能应用场景。
Meta公司已经成功地将其RoCE网络从原型扩展到了多个集群的部署,每个集群可以容纳数千个GPU。
这些RoCE集群支持各种生产型分布式GPU训练任务,包括排名、内容推荐、内容理解、自然语言处理以及GenAI模型训练等工作负载。
Meta公司专门为分布式AI训练建立了一个专用的后端网络,这个网络可以独立于数据中心网络的其他部分进行发展、运行和扩展。
训练集群依赖于两个独立的网络:前端(FE)网络用于数据获取、检查点和日志记录等任务,而后端(BE)网络则用于训练任务,具体如下图所示:
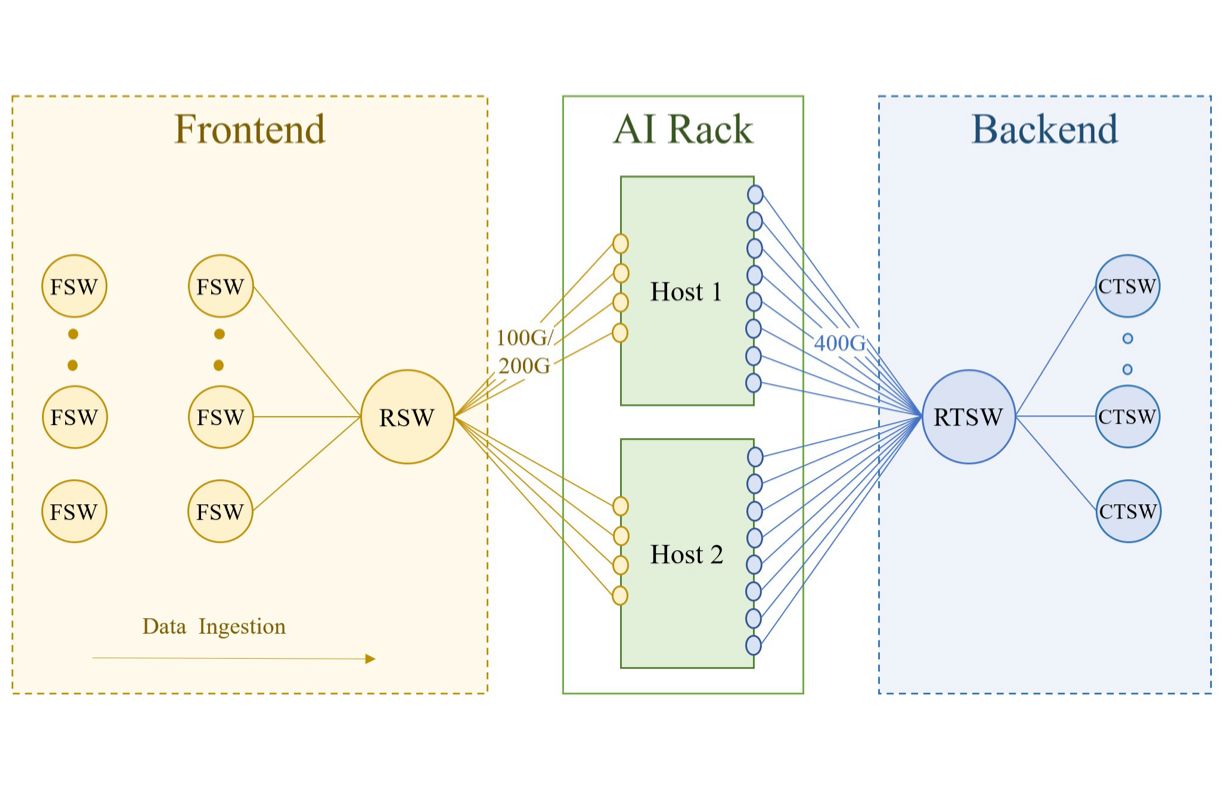
训练机架连接至数据中心网络的前端(FE)和后端(BE)。FE的网络层级包括机架交换机(RSW)、架构交换机(FSW)等,并内含存储仓库,为GPU提供所需的训练工作负载输入数据。
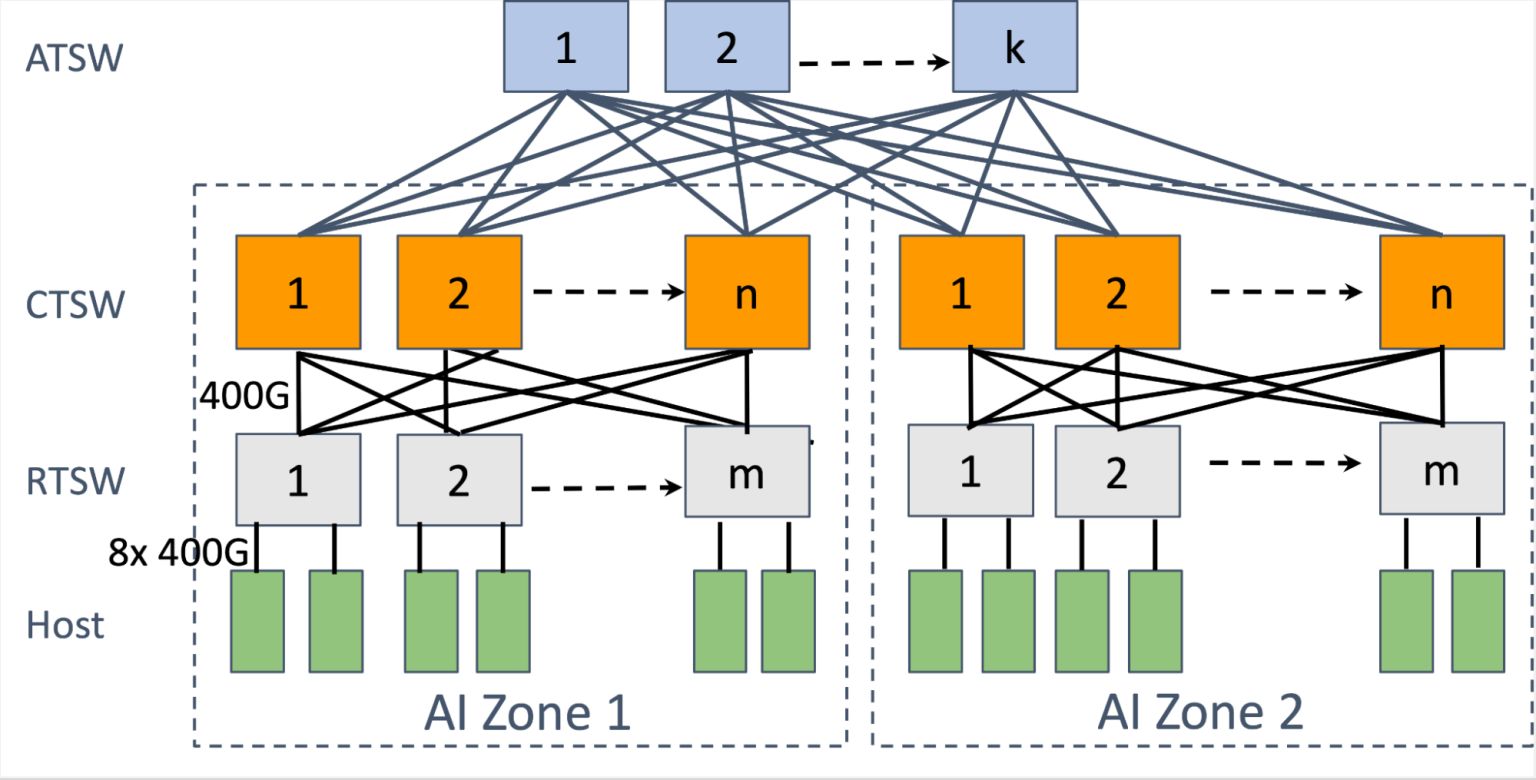
后端结构是一种专用结构,它采用无阻塞架构将所有RDMA网卡连接起来,不论其物理位置如何,从而在集群中任意两个GPU之间实现高带宽、低延迟及无损传输。

为了解决LLM模型训练对GPU规模需求的问题,Meta设计了聚合训练交换机(ATSW)层,用以连接多个AI区域。此外,Meta还对路由和拥塞控制等方面进行了优化,以提高网络性能。
请附上参考地址。
(注:原文并不是一个完整的句子,因此重写时添加了一些词汇以形成完整的句子。)