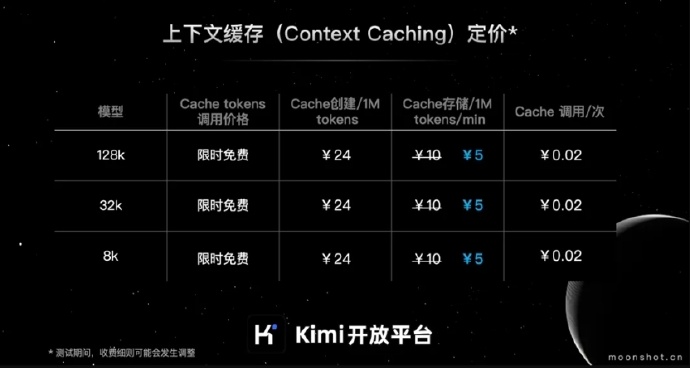
月之暗面 Kimi 开放平台的上下文缓存 Cache 存储费用降低了50%:现在的价格是每分钟每1M tokens 5元。
编辑日期:2024年08月07日
7月1日,Kimi开放平台的上下文缓存(Context Caching)功能开始公测。官方表示,在API价格不变的情况下,这项技术可以帮助开发者减少高达90%的长文本旗舰大模型使用成本,并提高模型的响应速度。
以下是Kimi开放平台上下文缓存功能公测的详细信息:
据介绍,上下文缓存是一项数据管理技术,它可以让系统提前存储大量经常被请求的数据或信息。当用户请求相同信息时,系统可以直接从缓存中提供,无需再次计算或从原始数据源中检索。

上下文缓存适用于那些经常需要请求、并且会大量重复引用初始上下文的场景,它可以减少处理长文本模型的成本并提升效率。据官方说明,这种方法最高可以减少90%的费用,并且将首个Token的延迟时间降低83%。以下是适用这种技术的业务场景:


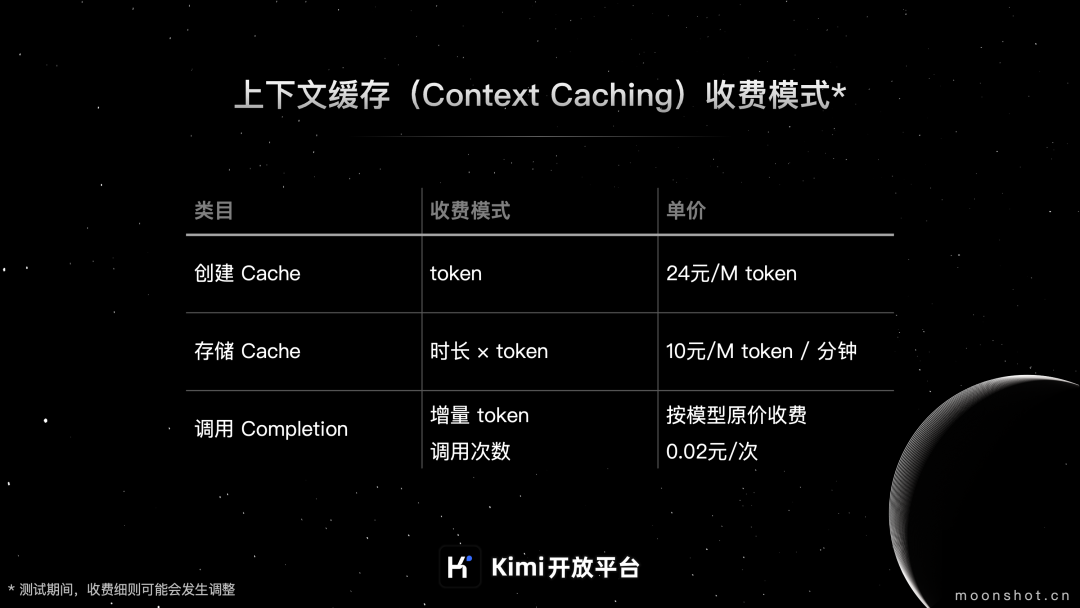
上下文缓存的收费模式主要分成以下三个部分:
大家在看

AI安装教程
AI本地安装教程

微软AI大模型通识教程
微软AI大模型通识教程

AI大模型入门教程
AI大模型入门教程

Python入门教程
Python入门教程

Python进阶教程
Python进阶教程

Python小例子200道练习题
Python小例子200道练习题

Python练手项目
Python练手项目

Python从零在线练习题
Python从零到一60题