






无一模型能及格!北大 / 通研院提出超高难度基准 LooGLE,专用于评估长文本理解与生成能力
编辑日期:2024年08月07日
北京大学与北京通用人工智能研究院共同提出了一项新的基准数据集——LooGLE,该数据集专门用于测试和评估大型语言模型(LLMs)在处理长文本上下文理解方面的能力。

该数据集既能评估LLMs处理和检索长文本的能力,也能评估其对文本中长程依赖关系的建模和理解能力。
评估后发现,这些模型在处理复杂的长期依赖任务时,其多信息检索、时间重新排序、计算及理解推理等方面的能力表现并不理想。
例如,像 Claude3-200k、GPT4-32k、GPT4-8k、GPT3.5-turbo-6k、LlamaIndex 这样的商业模型,其平均准确率仅有 40%。
而开源模型的表现则更为不尽如人意......
ChatGLM2-6B、LongLLaMa-3B、RWKV-4-14B-pile、LLaMA-7B-32K 的平均准确率只有 10%。
目前,该论文已被ACL 2024接受。论文的第一共同作者是通研院的李佳琪和王萌萌,通讯作者则是通研院的研究员郑子隆和北京大学人工智能研究院的助理教授张牧涵。
LooGLE 基准测试的主要特点包括:
首先,它包含了近800份最近收集的超长文档,平均每份接近2万字(这一长度是现有类似数据集的两倍)。从这些文档中,我们重新生成了6千个涉及不同领域和类别的任务/问题,用于构建LooGLE。
目前缺乏数据集,既能够评估大型语言模型处理和记忆长文本的能力,又能评估它们对文本中的长距离依赖关系进行建模和理解的能力。
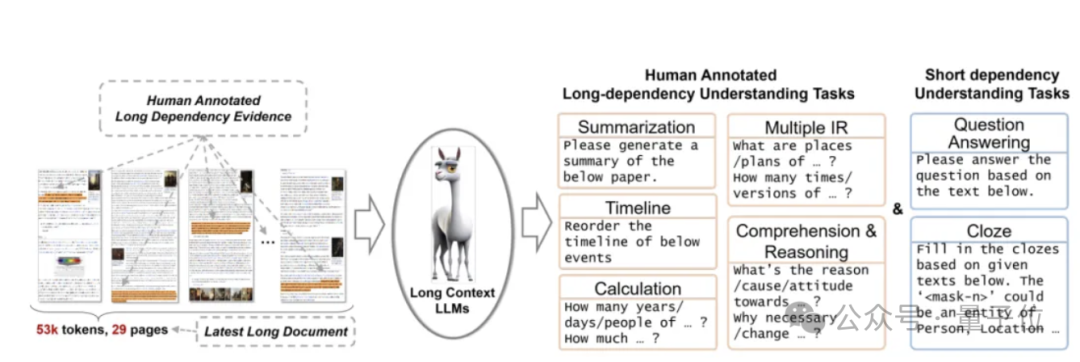
LooGLE的数据集由7个主要任务类别组成,目的是评估LLMs理解短程和长程依赖内容的能力。
团队设计了五种类型的长期依赖任务,包括理解与推理、计算、时间线重新排序、多信息检索和摘要。
通过人工标注精心创建了超过 1100 对高质量的长依赖问答对,以满足长依赖性的需求。这些问答对经过严格的交叉验证,从而实现对大型语言模型(LLMs)在处理长依赖关系方面能力的精确评估。
LooGLE 数据集仅包含 2022 年以后发布的文本,这样尽可能避免了预训练阶段的数据泄漏问题。这要求大型模型必须运用其上下文学习能力来完成任务,而非仅仅依赖记忆中的事实和知识储备。
该基准的文本来源于广泛认可的开源文档,涵盖了arxiv论文、维基百科文章以及电影和电视剧本等,涉及领域包括学术、历史、体育、政治、艺术、赛事、娱乐等。

在本项研究中,研究团队组织了近一百名标注人员手工编制了大约1100组真实的长依赖问答对。这些问答对被分为四类长依赖任务:多信息检索、时间重排序、计算以及理解推理。

为了提供更加全面和通用的性能评价,LooGLE采用了基于语义相似性的指标、GPT4作为评判指标,以及人类评估等方法。通过对9种最前沿的长文本LLMs(其中包括来自OpenAI及Anthropic的商业模型,还有几个主流开源基础模型经微调后的长文本模型,以及加入外部记忆模块的检索增强型模型)在LooGLE上的评估,我们获得了以下重要发现:
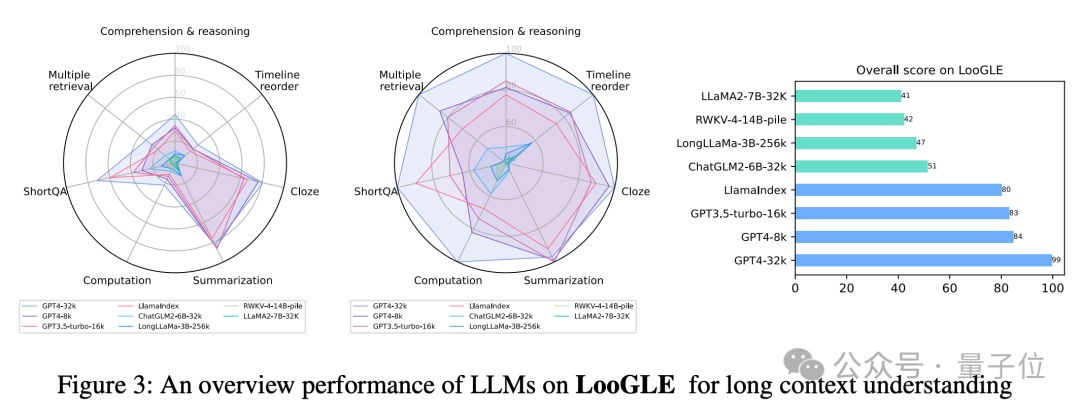

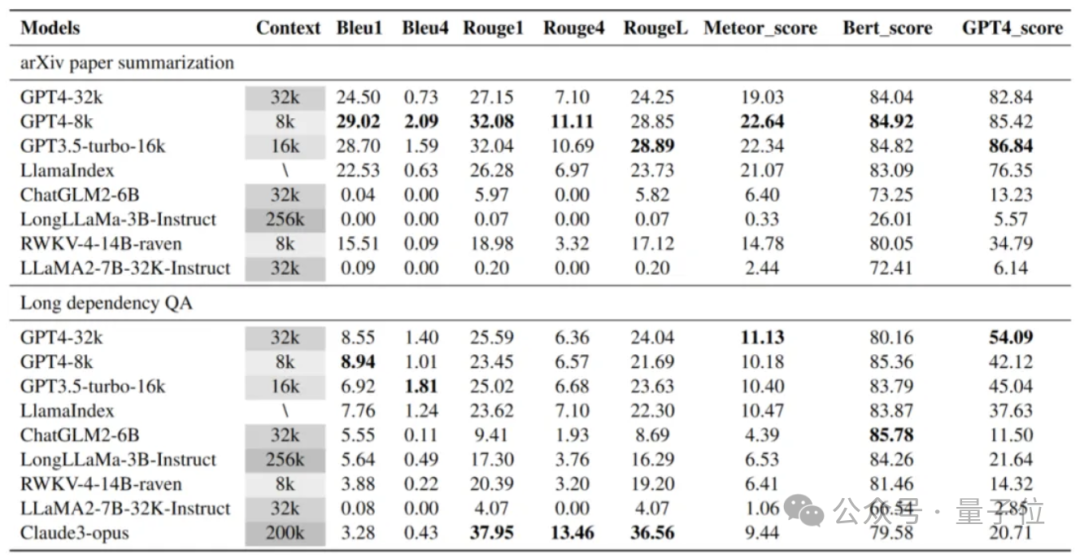
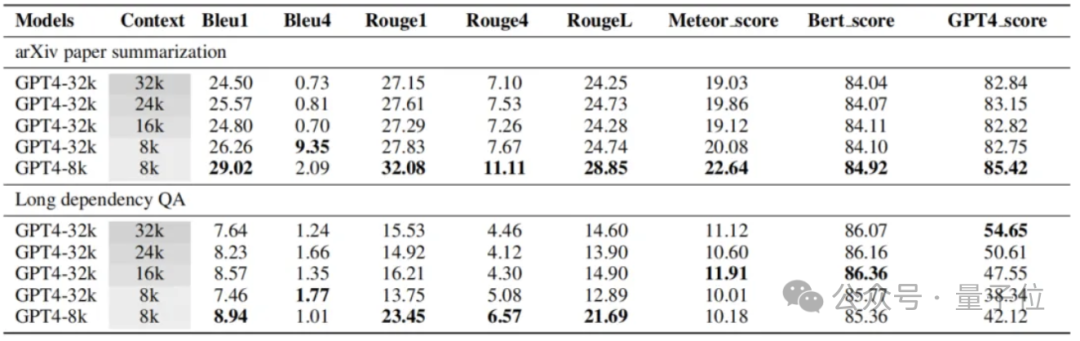

因此,LooGLE不仅为长上下文LLMs提供了系统而全面的评估框架,同时也为未来开发出能够实现“真正长上下文理解”的增强型模型提供了启示和方向。
论文链接:
请参阅以下链接:https://arxiv.org/abs/2311.04939
数据地址:
(这里没有给出具体的文本内容,只有“数据地址”四个字。如果需要重写,请提供完整的句子或者上下文信息。)
请访问这个链接:https://huggingface.co/datasets/bigainlco/LooGLE
代码地址:
请查看这个链接:https://github.com/bigai-nlco/LooGLE
本文来源于微信公众号:量子位(ID:QbitAI),作者:LooGLE 团队,原标题为《无一模型及格!北大 / 通研院提出超高难度基准,专门评估长文本理解与生成》。
大家在看




















