ACL 2024奖项公布!全华人团队运用AI解开三千年前甲骨文之谜
编辑日期:2024年08月15日
ACL 2024 最终颁发奖项了!
共有7篇最佳论文和35篇杰出论文,同时还会公布时间检验奖、SAC奖、最佳主题论文奖、最佳资源论文奖等。
值得一提的是,在7篇最佳论文中,有一篇名为《利用扩散模型破译甲骨文》是由全华人团队完成的。


今年的国际计算语言学年会(ACL)第26届会议于8月11日至16日在泰国曼谷举行。

ACL 2024 的论文总提交数量与 2023 年差不多,大约为 5000 篇,其中有 940 篇被接受。
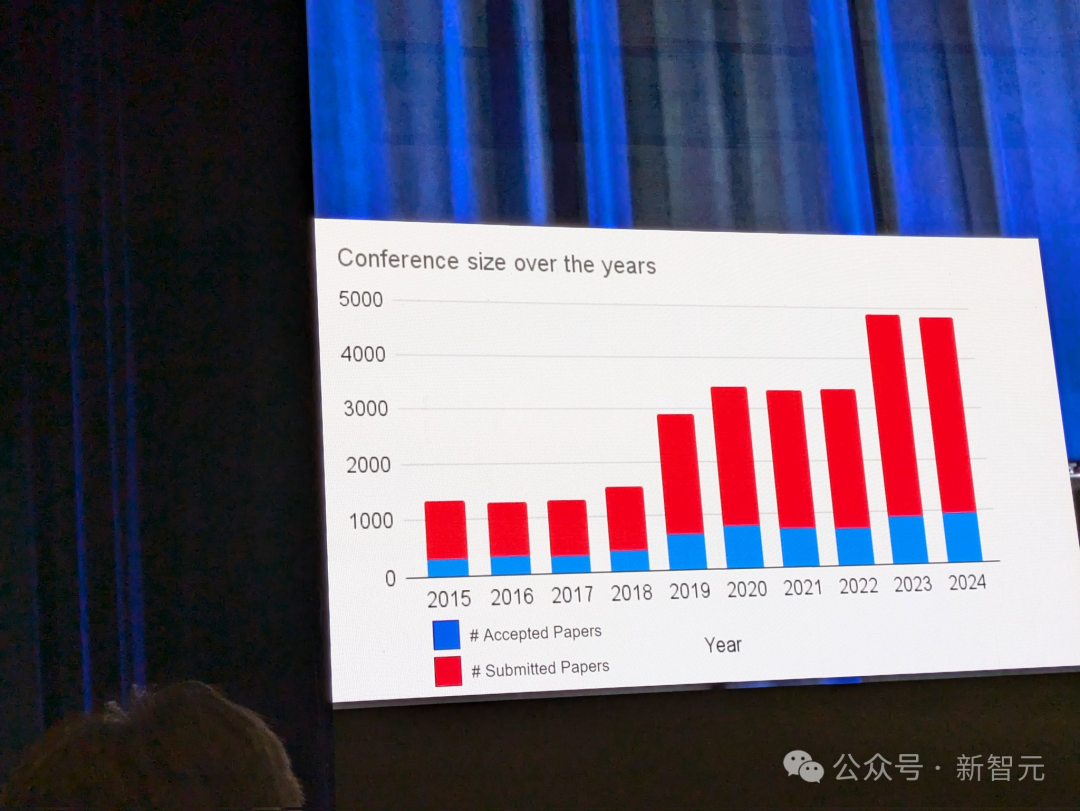
本届ACL堪称历史上规模最大的一次,共有72名SAC、716名AC及4208位审稿人参与。
共有975篇findings论文,6篇JCL、31篇TACL,另外有3场主题演讲和1场座谈会。
整场会议还包括了18个工作坊、6个教程、38个演示以及60篇SRW论文。

论文作者提交论文的具体情况如下:
大多数人提交了 1 篇或 2 篇论文:其中有 10,333 名学者提交了 1 篇论文,2,130 人提交了 2 篇论文。
少数人提交了多篇论文:有3位作者提交了18篇,6人提交了19篇,18人提交了超过20篇。

一起来看看,今年有哪些团队获得了大奖?
论文 1:利用扩散模型解读甲骨文语言
作者:管海肃,杨欢欣,王欣宇,韩胜威,刘永革,金连文,白翔,刘玉亮
机构:华中科技大学、阿德莱德大学、安阳师范学院、华南理工大学
这段文本已经是中文,所以不需要重写。如果你需要的是对这些机构的一个更详细的介绍或者其他的表达方式,请提供更多的上下文信息。

论文链接:https://arxiv.org/pdf/2406.00684
如题目所述,一个华人的团队利用人工智能做了一件既有趣又有价值的事情——通过使用扩散模型来破译甲骨文(OBS)。
甲骨文起源于约3000年前的中国商朝,是语言史上的一个重要基石。
尽管人们已经发现了数千份碑文,但大量甲骨文的内容仍未被解读,这为这种古老的语言蒙上了一层神秘的面纱。
在论文中,作者介绍了一种新的方法,该方法采用了图像生成的人工智能技术,特别是开发出了名为「Oracle Bone Script Decipher」(OBSD)的系统。
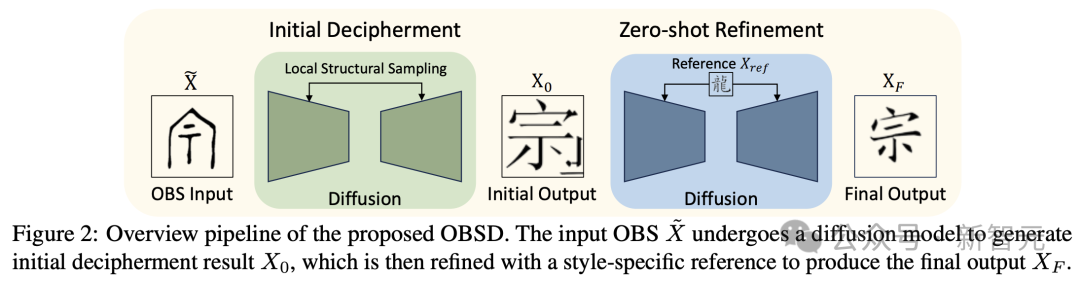
通过采用基于条件扩散的策略,OBSD 生成了重要的解码线索,为人工智能辅助分析古代语言开辟了新的路径。
为了验证其有效性,研究人员在甲骨文数据集上进行了大量的实验,实验的量化结果证明了 OBDS 的有效性。
论文 2:自然语言满足性:探索问题分布与评估基于转换器的语言模型
(尚未提交预印本)
论文 3:因果估计记忆曲线的因果估计方法研究
作者:Pietro Lesci, Clara Meister, Thomas Hofmann, Andreas Vlachos, Tiago Pimentel
(注:由于这些都是西方名字,且没有对应的中文翻译,所以这里并没有进行中文重写。如果你需要将这些作者的名字转换为假设的中文名字,请告知我。)
如果一定要按照中文习惯来调整的话,可能会变成这样(但这种变换是根据音译,并无实际意义,仅供示意): 作者:列斯彼罗, 梅思克拉, 霍夫曼托马斯, 弗拉霍斯安德烈亚斯, 皮门泰尔蒂亚戈
机构:剑桥大学、瑞士苏黎世联邦理工学院

论文链接:https://arxiv.org/pdf/2406.04327
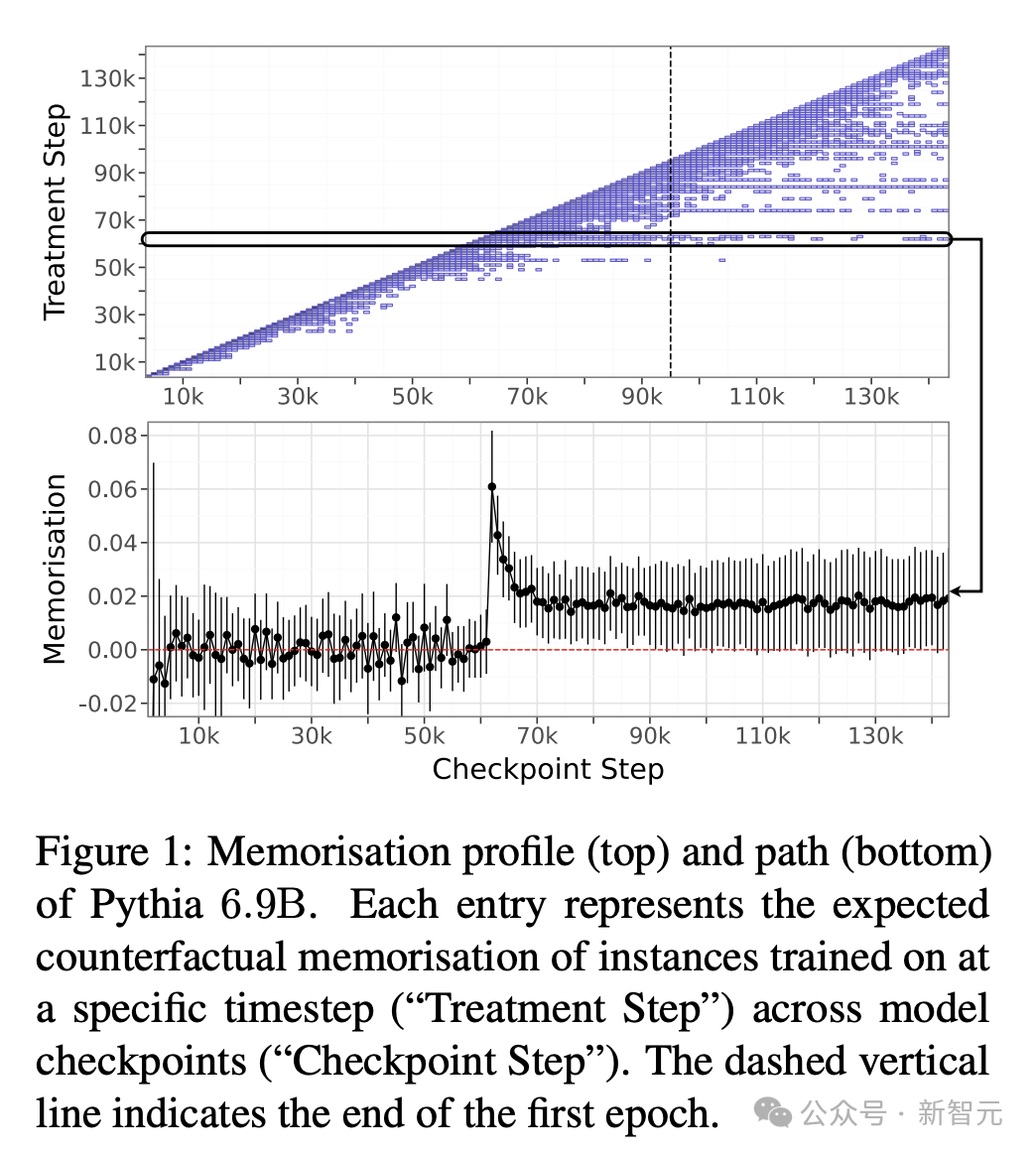
理解LLM的记忆对于实践和社会具有重要影响,例如研究模型训练的动态或防止版权侵权。
先前的研究将记忆定义为通过实例训练后,对模型在预测该实例时所产生的因果反应。
这个定义基于一个反事实的假设:即能够观察到在模型未见到此实例时情况会如何发展。
然而,现有的方法通常针对模型架构而不是特定的模型实例来估算内存,因此很难提供计算效率高且准确的反事实估计。
这项研究填补了一个重要的空白,作者依据计量经济学中的差分设计,提出了一种原则性和高效的新方法来估算记忆效应。
使用这种方法,我们只需要观察整个训练过程中一小部分实例的行为,就可以描绘出模型的记忆概况,也就是模型在整个训练过程中的记忆趋势。
在对Pythia模型套件进行的实验中,研究人员发现:
(1)大型模型具有更强且更持久的记忆能力;
(2)由数据的顺序和学习率决定;
(3)在不同规模的模型中展现出稳定的趋势,因此大型模型的记忆特性可以预测从小型模型的记忆特性。
论文 4:Aya 模型:一种经过指令微调的开放多语言语言模型
作者:Ahmet Üstün, Viraat Aryabumi, 郑昕永, 高玮茵, Daniel D'souza, Gbemileke Onilude, 尼尔·班达里, 施瓦利卡·辛格, 许丽蕾, Amr Kayid, Freddie Vargus, Phil Blunsom, Shayne Longpre, Niklas Muennighoff, 马兹伊赫·法达埃, Julia Kreutzer, 萨拉·胡克
机构:Cohere For AI、布朗大学、Cohere、Cohere For AI 社区、卡内基梅隆大学、麻省理工学院

论文链接:https://arxiv.org/pdf/2402.07827
今年2月,初创公司Cohere发布了一款名为Aya的全新开源大型语言生成模型,支持超过101种语言。
值得一提的是,Aya 模型的语言模型覆盖范围是现有开源模型的两倍多,超越了 mT0 和 BLOOMZ。
人类评估得分达到 75%,在各项模拟胜率测试中的得分是 80-90%。
这个项目得以启动,汇聚了来自119个国家的超过3000名独立研究者的力量。
此外,研究人员还发布了一个至今为止最大的多语言指令微调数据集,包含513百万条数据,覆盖114种语言。
论文 5:不可能的任务:语言模型
作者:朱莉·卡拉尼、伊莎贝尔·帕帕迪米特里奥、理查德·富特雷尔、凯尔·马豪沃德、克里斯托弗·波特斯
机构:斯坦福大学、加州大学尔湾分校、德克萨斯大学奥斯汀分校

论文链接:https://arxiv.org/pdf/2401.06416
乔姆斯基等人曾明确表示,LLM 在学习人类可能和不可能学习的语言方面具有相同的能力。
然而,支持这种说法的公开实验证据却很少。
为此,研究人员开发了一系列复杂程度不同的合成「非现实语言」,每种语言都是通过对英语数据进行系统性的修改,并采用不自然的词汇顺序和语法规则来设计的。
这些语言处于一个不可能性的连续体上:一端是完全无法识别的语言,例如随意排列的英语;另一端则是从语言学角度来看极为特殊和罕见的语言,比如基于单词位置计数的规则体系。
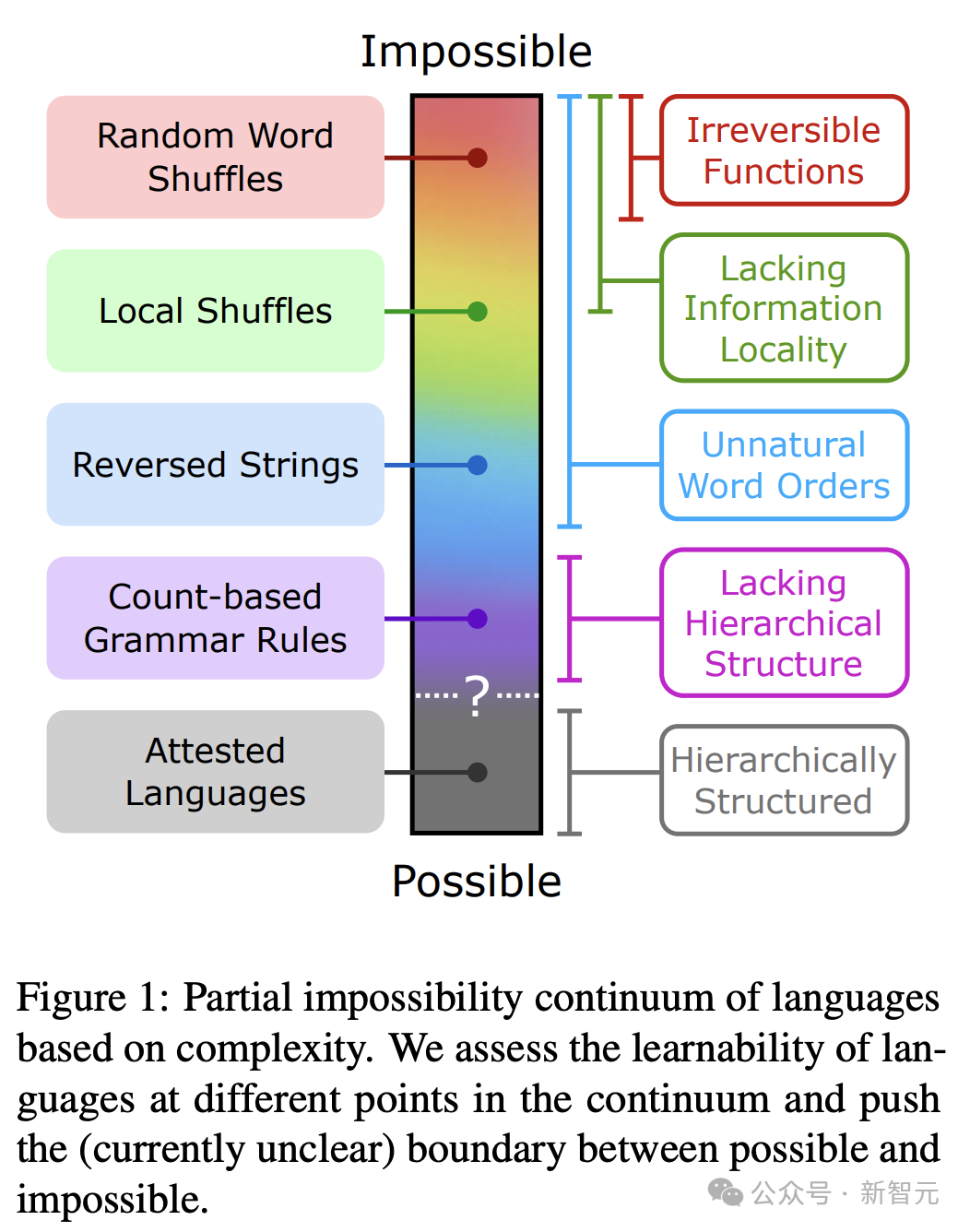
经过一系列的评估,GPT-2 在学习不可能的语言方面显得十分困难,这给其核心观点带来了挑战。
更重要的是,研究者希望这种方法能激发更多关于大型语言模型(LLM)在学习不同种类语言能力方面的研究,从而更好地理解LLM在认知和语言类型学研究中的潜在用途。
论文 6:半监督神经原型语言重构
作者:梁璐, 谢佩容, David R. Mortensen
机构:卡内基梅隆大学、南加州大学
(原文已经是中文,无需重写)

论文链接:https://arxiv.org/pdf/2406.05930
现有的原始语言对比和重建工作,通常需要全程监督。
然而,历史重建模型仅在使用有限的标注数据进行训练时,才具备实际的应用价值。
对此,研究人员提出了一项半监督的历史重建任务。
在这种任务中,模型只需要基于少量的标注数据(有原型的同源集)和大量的未标注数据(无原型的同源集)来进行训练。
作者开发了一种用于对比重构的神经网络架构——DPD-BiReconstructor,该架构蕴含了语言学比较方法中的一个关键观点:重构词汇不仅能从其子词汇中被重构出来,还可以确定性地转换回其子词汇。
研究表明,这种架构能通过利用未标注的同源词汇集合,在这项新任务上的表现超越了现有的半监督学习基线。
论文 7:为什么敏感函数对转换器模型而言难以处理?
作者:Michael Hahn,Mark Rofin
机构:萨尔大学
(这似乎是直接的中文翻译,没有特别需要重写的内容。如果您需要更详细的资讯或其它帮助,请告诉我!)

论文链接:https://arxiv.org/pdf/2402.09963
实证研究已经揭示了Transformer模型存在一系列的学习偏见和局限性,例如在学习简单的形式语言(如奇偶性PARITY)时持续遇到困难,并且倾向于低级函数。
然而,理论上的理解仍然有限,现有的表达能力理论往往要么过度预测,要么低估了实际的学习能力。
研究人员已经证实,在Transformer架构中,损失景观(loss landscape)受到了输入空间敏感性的限制:
那些对输入字符串多个部分敏感的Transformer模型,在参数空间中形成孤立点,这会导致在泛化过程中出现低敏感度的偏差。
该研究从理论和实证的角度证实,最新的理论统一了对于Transformer学习能力及偏差的常见经验观察,例如它们在序列处理中对位置的敏感度、对低阶函数的偏好,以及在解决奇偶性问题时面临的长度泛化难题。
这表明,要理解Transformer的归纳偏置,不仅需要研究其原则上表达能力,还需要研究其损失面(或损失景观)。
论文 1:GloVe:全球词汇向量表示(2014)
作者:杰弗里·彭宁顿,理查德·索切尔,克里斯托弗·曼宁
机构:斯坦福大学
(这似乎是直接的中文翻译,如果您需要更多的上下文或者具体信息,请提供更多信息。)

论文地址:https://nlp.stanford.edu/pubs/glove.pdf
(这句已经是中文了,上述链接为原文献地址,无需进行语言转换或重写。如果您需要关于这篇论文的简介或者解释,我可以进一步帮助。)
词嵌入(word embedding)在2013年至2018年期间是NLP深度学习方法的基石,并且至今仍持续产生重大影响。它们不仅提升了NLP任务的表现,还在计算语义方面展现出显著的影响,比如词语相似性和类推能力。
两种最具影响力的词嵌入方法可能是 skip-gram/CBOW 以及 GloVe。相较于 skip-gram,GloVe 的提出时间较晚,其相对优势在于概念上的简易性——直接根据单词的分布特性来优化它们在向量空间中的相似度,而非从简化语言模型的角度进行间接优化。
论文 2:分布相似性的衡量方法(1999)
作者:李莉安
机构:康奈尔大学
(这似乎是直接的中文翻译,没有特定的语境或内容需要重写。如果您有具体的句子或上下文希望调整,请提供更多信息。)

论文地址:https://aclanthology.org/P99-1004.pdf
(这已经是中文描述了,原文就是提供一个网址链接,无需进行语言转换。)
研究分布的相似性度量,旨在改进对未出现的共现(co-occurrence)事件的概率估计,这相当于以另一种方式来表示单词之间的相似性。
本文的贡献体现在三个方面:对多种度量方法进行广泛的实证比较;根据相似度函数中包含的信息来进行分类;引入了一种新的函数,它在评估潜在代理分布方面表现优异。

论文:OLMo: 加速语言模型科学的发展
作者:Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi
机构:艾伦人工智能研究所、华盛顿大学、耶鲁大学、纽约大学、卡内基梅隆大学
(原文本已经是中文,因此无需重写。如果您需要的是把这些机构名称整合进一句话里,可以参考下面的形式:)
以下机构包括艾伦人工智能研究所、华盛顿大学、耶鲁大学、纽约大学以及卡内基梅隆大学。

论文链接:https://arxiv.org/abs/2402.00838
这项工作代表了在提升大型语言模型训练的透明度和可重复性方面的重要进步,这是社区迫切需要的,以便推动进一步的发展(或者至少能让除了一些大型企业外的更多参与者能够为之做出贡献)。
论文 1:Johnny 如何通过人性化大型语言模型来说服它们自我突破:重新思考说服手段以挑战人工智能安全问题
作者:曾毅,林鸿鹏,张靖雯,杨迪一,贾若溪,施伟彦
机构:弗吉尼亚理工大学、中国人民大学、加州大学戴维斯分校、斯坦福大学
(原文本已经是中文,故无需重写)

论文链接:https://arxiv.org/abs/2401.06373
本篇论文讨论了人工智能安全领域的绕过限制这一主题。它探讨了一种在社会科学研究领域中开发的方法。这项研究非常吸引人,并且有可能对相关社区产生重大影响。
论文2:DIALECTBENCH:一种用于方言、变体及密切相关的语言的自然语言处理基准测试
作者:Fahim Faisal, Orevaoghene Ahia, Aarohi Srivastava, Kabir Ahuja, David Chiang, Yulia Tsvetkov, Antonios Anastasopoulos
(注:由于这些名字都是非中文名,所以在中文重写时保持原样)
机构:乔治梅森大学、华盛顿大学、圣母大学、RC Athena(注:原文中的"RC Athena"似乎不是一个具体的大学名称,保留原名)

论文链接:https://arxiv.org/abs/2403.11009
方言变异是在自然语言处理和人工智能领域中一个尚未得到充分研究的现象。然而,对其进行研究具有极高的价值,不论是从语言学和社会学的角度来看,还是对于实际应用都具有重要影响。本篇论文提出了一种创新性的基准,以适应在大规模语言模型时代研究这一议题的需求。
论文 3:祷告后喝啤酒?评估大型语言模型中的文化偏见
作者:Tarek Naous, Michael J. Ryan, Alan Ritter, Wei Xu
(这似乎是作者列表,并没有实际的文字内容需要被翻译或重写。如果需要完全汉化作者名字,请告知我。)
机构:乔治亚理工学院

论文链接:https://arxiv.org/abs/2305.14456
本篇论文揭示了一个在大型语言模型领域中的重要议题:文化偏见。尽管研究聚焦于阿拉伯文化和语言,但其结果表明,在构建大型语言模型时,我们必须考虑到不同文化的细微差异。因此,可以针对其他文化进行类似的研究,以推广和评估这些文化是否同样受到此问题的影响。
论文 1:Latxa:一个面向巴斯克语的开放语言模型及评估套件
作者:Julen Etxaniz, Oscar Sainz, Naiara Perez, Itziar Aldabe, German Rigau, Eneko Agirre, Aitor Ormazabal, Mikel Artetxe, Aitor Soroa
(注:这些名字为外国名字,直接翻译可能失去原有含义,所以这里保持原样)
机构:巴斯克大学
(这句已经是中文了,所以没有重写的空间。如果您有其他的具体需求或者想要重写的句子,请提供更多的信息或文本内容。)

论文链接:https://arxiv.org/abs/2403.20266
本篇论文详细描述了语料库收集以及评估数据集的所有具体步骤。虽然他们的研究聚焦于巴斯克语,但这种方法可以被推广,用于构建其他低资源语言的大型语言模型。
论文 2:Dolma:一个包含三千亿词条的开放语料库,用于语言模型预训练研究
作者:Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Harsh Jha, Sachin Kumar, Li Lucy, Xinxi Lyu, Nathan Lambert, Ian Magnusson, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Abhilasha Ravichander, Kyle Richardson, Zejiang Shen, Emma Strubell, Nishant Subramani, Oyvind Tafjord, Pete Walsh, Luke Zettlemoyer, Noah A. Smith, Hannaneh Hajishirzi, Iz Beltagy, Dirk Groeneveld, Jesse Dodge, Kyle Lo
机构:艾伦人工智能研究所、加州大学伯克利分校、卡内基梅隆大学、Spiffy AI、麻省理工学院及华盛顿大学。

论文链接:https://arxiv.org/abs/2402.00159
本文论述了在为大型语言模型准备数据集的过程中,数据策展的重要性。它提供有价值的见解,能够惠及社区内的广泛受众。
论文3:AppWorld——为交互式编程代理基准测试提供的一款可控应用及人物世界
作者:Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, Niranjan Balasubramanian
(注:由于原文提供的就是作者列表,并没有实际的句子内容,因此这里只是简单地保留了原有的作者名单。如果有具体的文本内容需要翻译,请提供详细信息。)
机构:纽约州立大学石溪分校、艾伦人工智能研究所、萨尔大学
(原文已经是中文,无需重写)

论文链接:https://arxiv.org/abs/2407.18901
这是一个极为印象深邃且重要的尝试 —— 建立一个人机交互的模拟器与评估环境。这将会激励社区创建富有挑战性的动态基准。





(此图不完整)
注:您提供的文本已经是中文,所以这里没有进行语言转换。若需要其他帮助,请告知。





参考资料:
(注:您提供的文本内容非常短,若需重写具体文本内容请提供更多信息。)
本文出自微信公众号:微信公众号(ID:null),作者为新智元。
大家在看