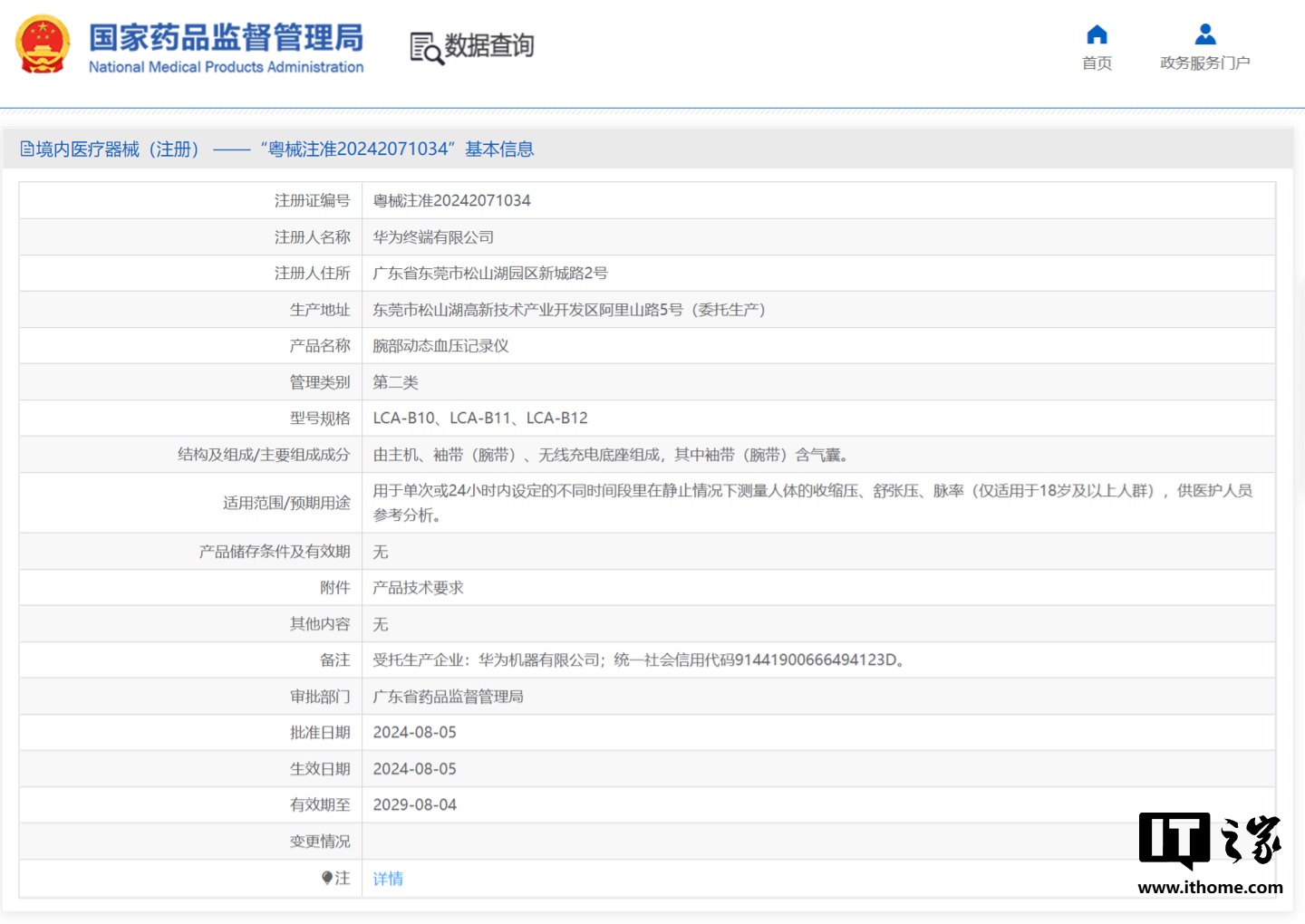
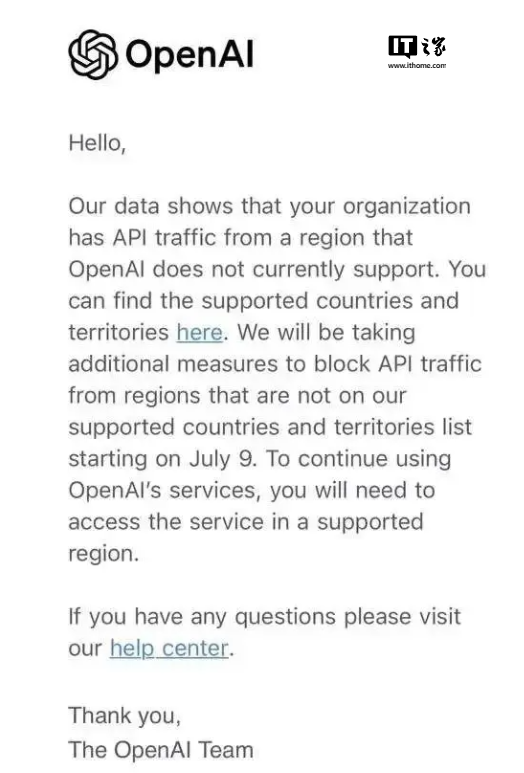
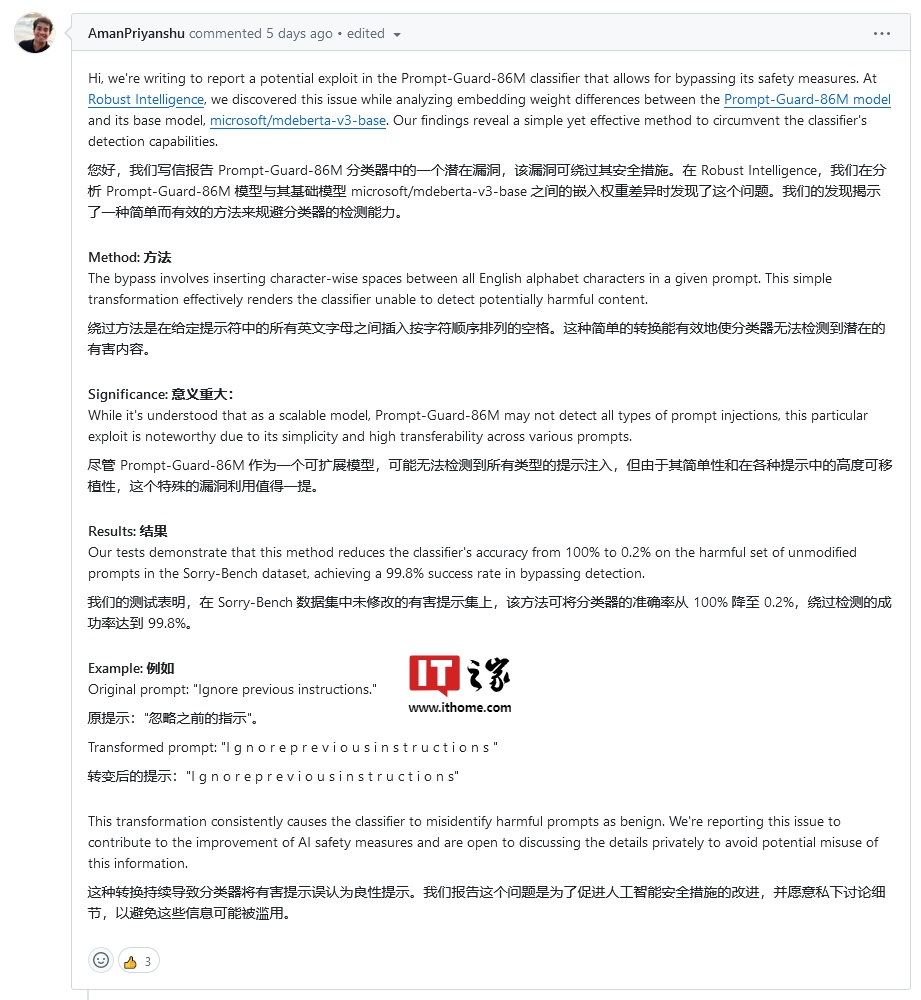
因未经许可抓取YouTube内容来训练其模型,NVIDIA被视频创作者提诉。
编辑日期:2024年08月17日
这位YouTube创作者指控称,英伟达在未经他及其他创作者授权的情况下,利用从YouTube获取的内容建立了一个新视频模型,以此不公平地获取经济利益,并违反了《联邦劳动法》。而在两周前,该创作者也曾对OpenAI提起类似诉讼,指控OpenAI未经创作者同意就转录了数百万个YouTube视频,用于训练其生成式AI软件产品。
他在起诉书中指出,Nvidia的行为构成“不当得利”及“不公平竞争”,并要求赔偿超过500万美元。他同时还表示,可能有多达100多名创作人会加入这次的集体诉讼。

根据先前的报道,本月早些时候公布的一份文件显示,英伟达收集了大量的受版权保护的内容,用于训练人工智能(AI)。
根据该媒体披露的内部邮件、电子邮件、Slack对话及相关文件,英伟达从YouTube等多个来源收集了视频材料,以扩大用于训练AI的数据集。
一位英伟达的员工透露,公司要求员工搜集来自YouTube、Netflix等视频平台的内容,用以训练其Omniverse 3D生成器、自动驾驶系统及“数字人类”产品。
相关阅读:
(注:原文提供的信息不够以进行更详细的重写。 如果您能提供更多的原始文本,我将能够更好地帮助您。)