蜘蛛侠翩翩起舞,新一代 ControlNet 来袭!由贾佳亚团队推出,实现即插即用功能,并能掌控视频生成过程。
编辑日期:2024年08月17日

同时,它还可以配合SVD来控制视频生成,对动作细节的掌控精确到手指。

在这些图像和视频的背后,是香港中文大学贾佳亚团队推出的开源图像/视频生成指导工具——ControlNeXt。
从这个名字就可以看出,研发团队对它的定位就是作为下一代的ControlNet。
像大神何恺明和谢赛宁的经典之作 ResNeXt(ResNet 的一种扩展),在命名时也是采用了类似的思路。
有些网友认为这个名字实至名归,确实代表了下一代的产品,并将 ControlNet 提升到了一个新的水平。

也有人直接表示,ControlNeXt是一个改变游戏规则的技术,大大提高了可控生成的效率,他们很期待看到人们利用这项技术创作出的作品。
ControlNeXt 支持多种SD系列模型,并且实现即插即用功能。
这其中包括图像生成模型如 SD1.5、SDXL、SD3(支持超分辨率),以及视频生成模型 SVD。
不多说,直接看效果。
可以观察到,在SDXL中加入了边缘(Canny)引导后,绘制出的二次元少女与控制线条几乎实现了完美的契合。

即使控制轮廓非常多且细碎,模型仍然能够绘制出符合要求的图像。

并且可以无需额外训练就与其它 LoRA 权重无缝集成。
例如,在SD 1.5中,可以将姿势(Pose)控制条件与各种LoRA结合使用,从而创建出风格迥异甚至跨次元但动作一致的角色。

此外,ControlNeXt 还支持遮罩(mask)和景深(depth)的控制模式。

在SD3中,还支持超级分辨率(Super Resolution),可以生成超高清的图像。

在视频生成过程中,ControlNeXt 能够实现对人物动作的控制。
比如让蜘蛛侠也在TikTok上跳起美女舞蹈,甚至连手指的动作都模仿得非常精准。
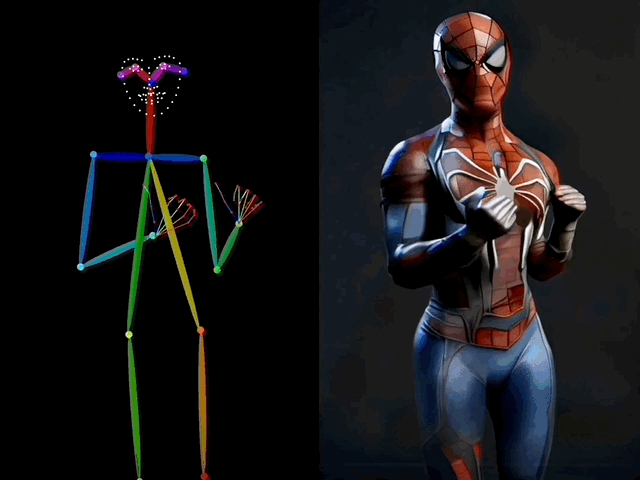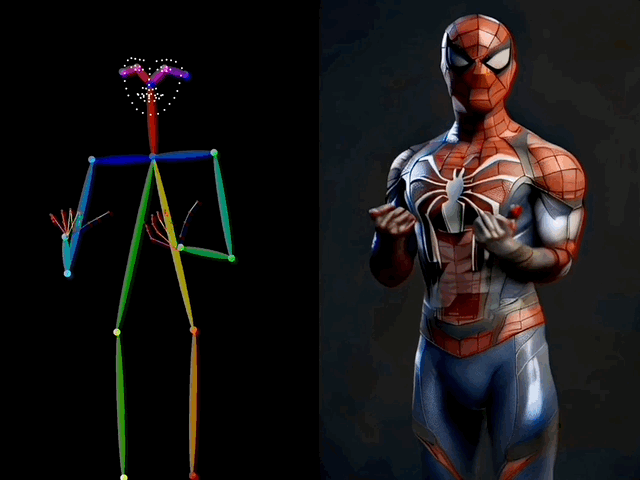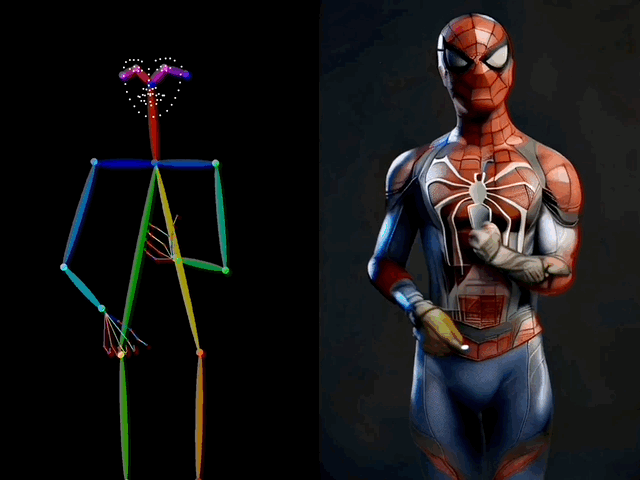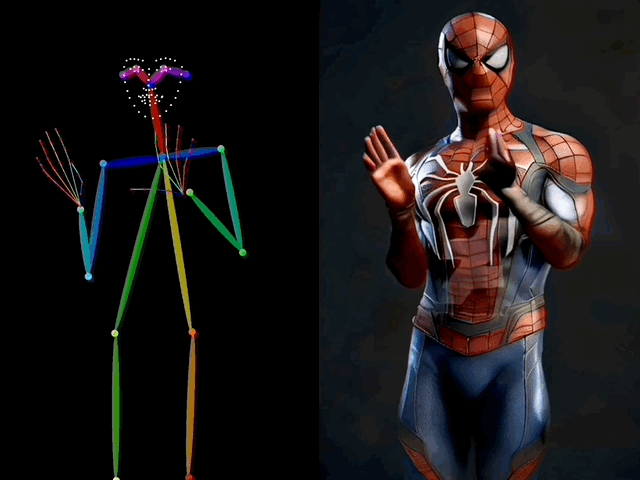
甚至可以让一把椅子长出手来跳同样的舞蹈,虽然这有些抽象,但单纯从动作来看,复制得还算不错。
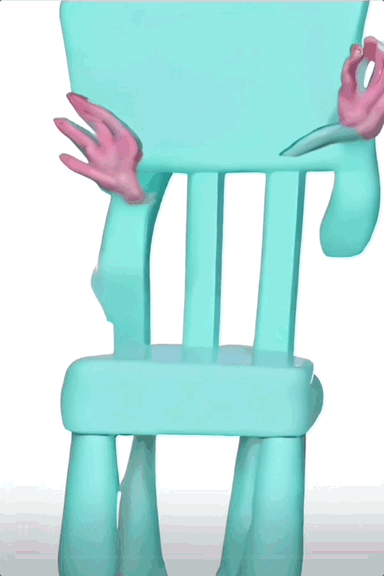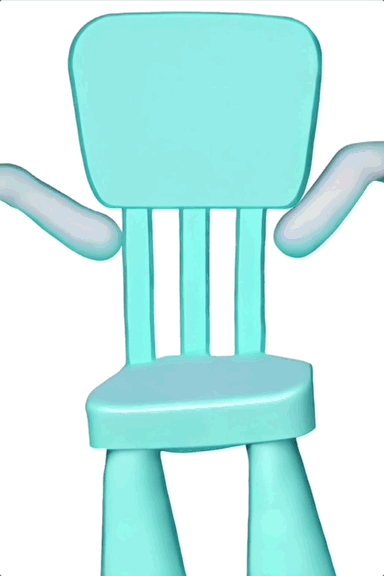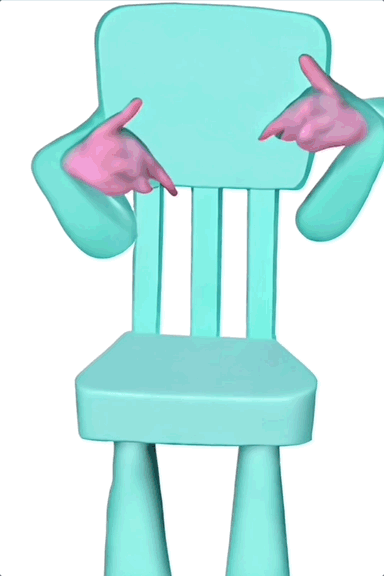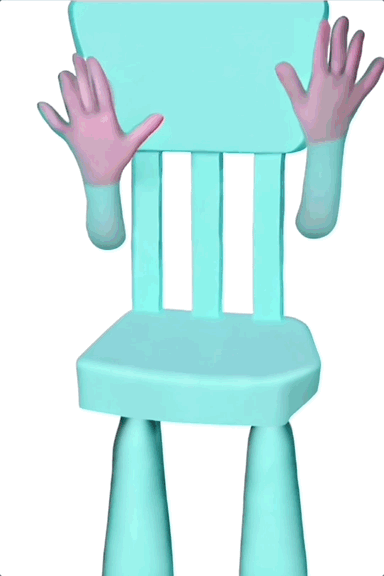
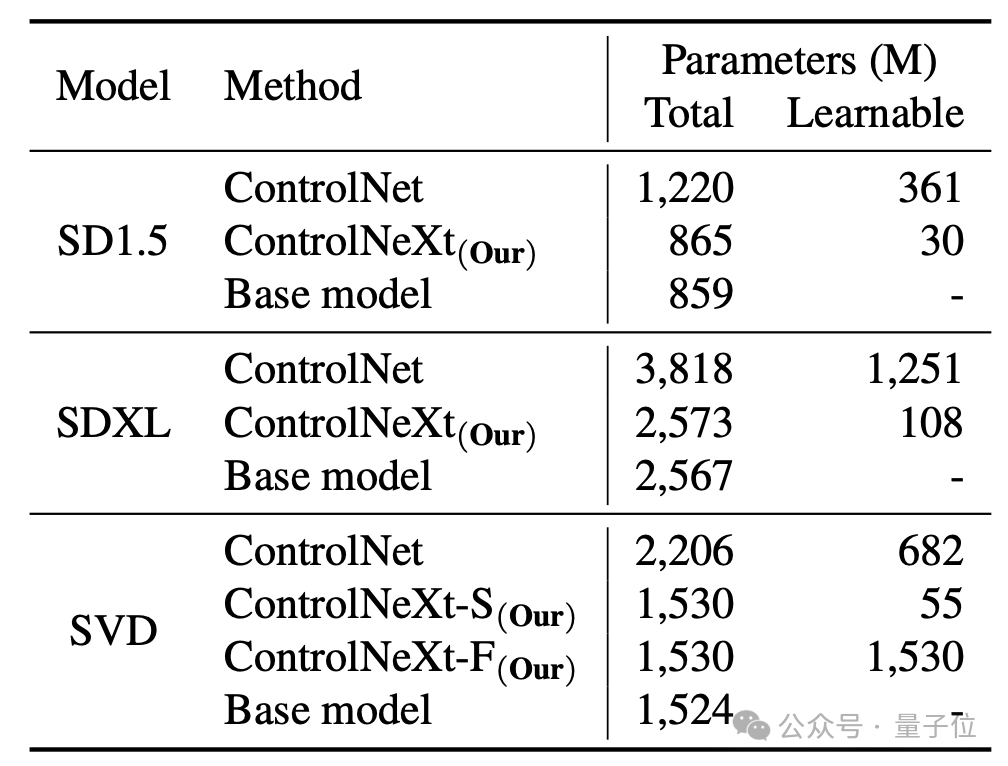
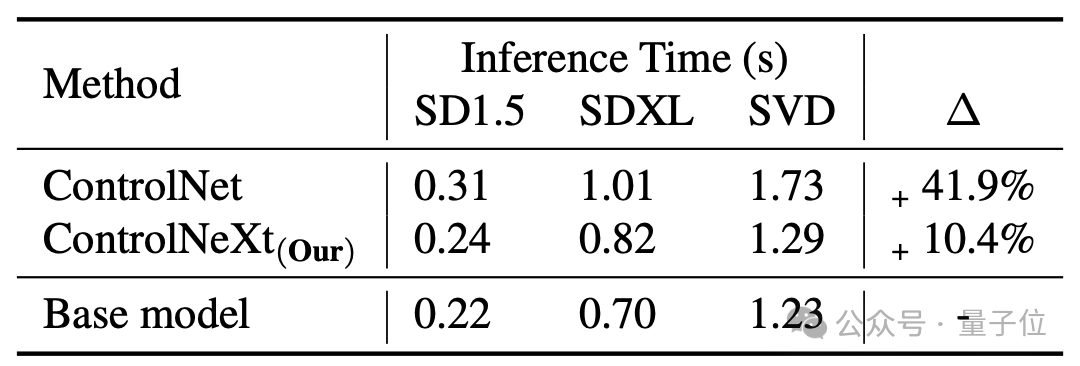
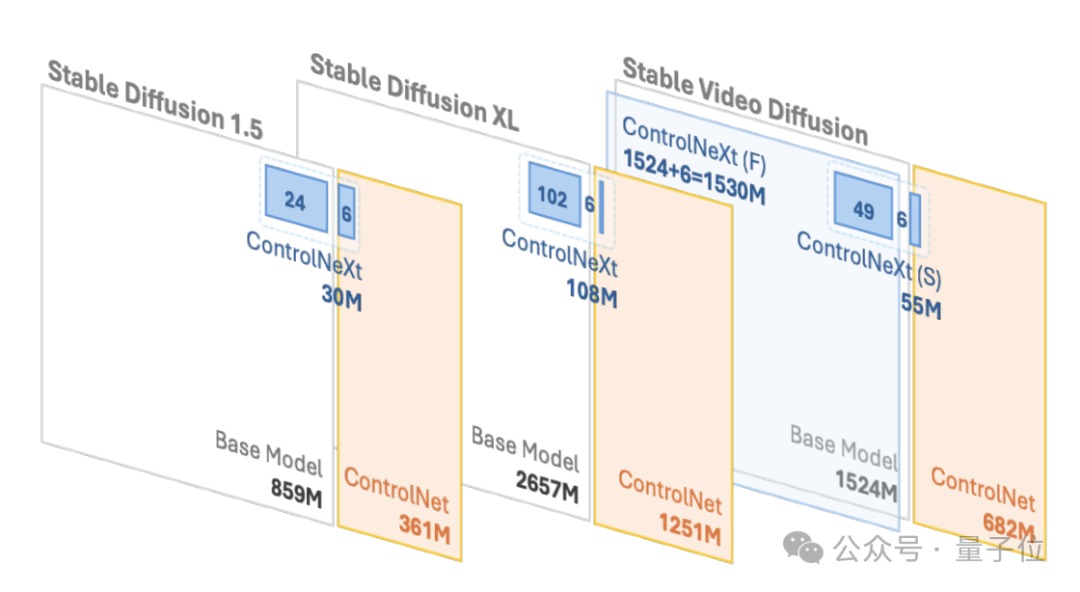
而且,相比原始的 ControlNet,ControlNeXt 所需的训练参数更少,收敛速度也更快。
例如,在SD1.5和SDXL中,ControlNet所需的学习参数分别为3.61亿和12.51亿,而ControlNeXt分别仅需3千万和1.08亿,不足ControlNet的10%。
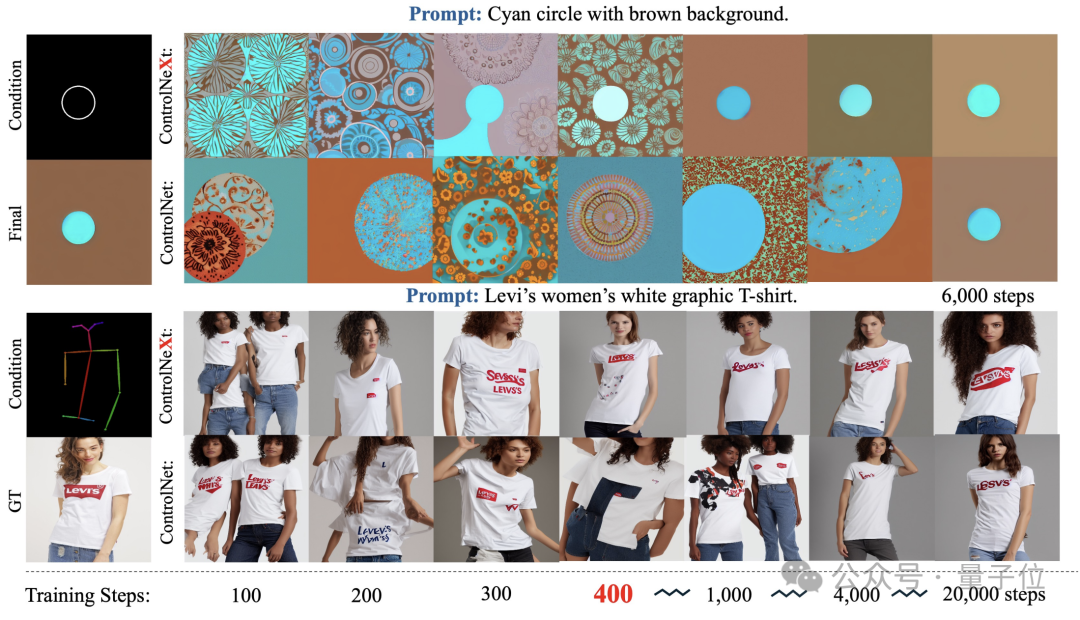
在训练过程中,ControlNeXt 大约在 400 步左右就已经接近收敛,而 ControlNet 则需要十倍甚至数十倍的步数。
生成速度也比 ControlNet 快,平均而言,ControlNet 相对于基础模型会增加 41.9% 的延迟,而 ControlNeXt 仅增加 10.4%。
那么,ControlNeXt 是如何实现的,它对 ControlNet 做出了哪些改进呢?
首先,通过一张图来了解 ControlNeXt 的整体工作流程。
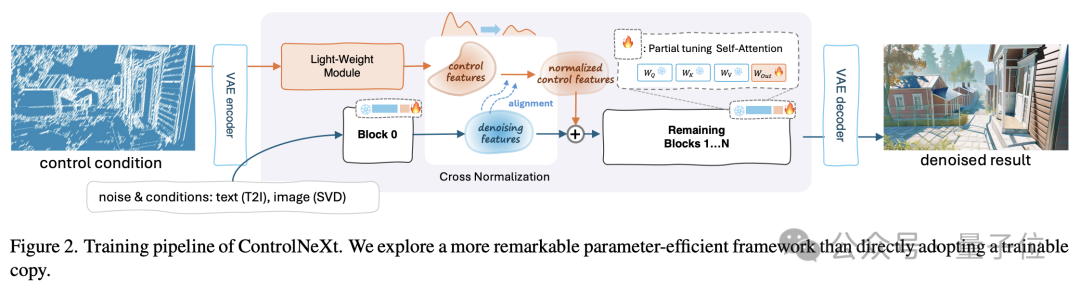
其中实现轻量化的关键在于,ControlNeXt移除了ControlNet中的大型控制分支,而是采用了一个由少数ResNet块组成的轻量级卷积模块。
这个模块负责提取控制条件的特征表示,例如语义分割掩码、关键点先验等。
其中的训练参数量通常不到 ControlNet 中预训练模型的 10%,但仍能很好地学习如何将输入的条件控制信息进行处理。这种设计大大减少了计算成本和内存使用。
具体而言,它从预训练模型的不同网络层进行中等距采样,以形成用于训练的参数子集,而其余的参数则保持冻结状态。
在设计ControlNeXt的架构时,研究团队还保持了模型结构与原始架构的一致性,从而实现了即插即用的功能。
不论是ControlNet还是ControlNeXt,条件控制信息的注入都是一项重要环节。
在这个过程中,ControlNeXt研究团队主要深入研究了两个关键问题:如何选择注入位置和设计注入方式。
研究团队观察到,在大多数可控生成任务中,用于指导生成的条件信息形式相对简单,并且与去噪过程中涉及的特征高度相关。
因此,团队认为没有必要在去噪网络的每一层都加入控制信息,他们选择仅在网络的中间层将条件特征和去噪特征进行聚合。
聚合的方式也被设计得尽可能简单 —— 在使用交叉归一化来对齐两组特征的分布之后,直接将它们相加。
这样既能保证控制信号对去噪过程产生影响,又避免了因采用复杂操作如注意力机制而引入额外学习参数和不稳定性的风险。
其中的交叉归一化也是 ControlNeXt 的一项核心关键技术,它取代了之前常用的那种零卷积等渐进式初始化策略。
传统的方法通过逐步释放新模块的影响,从零开始以缓解坍塌问题,但这通常会导致收敛速度变慢。
交叉归一化直接利用主干网络中去噪特征的均值 μ 和方差 σ 对控制模块产生的特征进行归一化,以尽可能地使两者的数据分布保持一致。
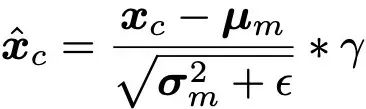
(注:ϵ 是为了数值稳定性而添加的一个小常数,γ 是缩放参数。)
归一化的控制特征通过调整尺度和偏移参数来调节幅度和基线,然后与去噪特征相加。这种方法既规避了参数初始化的敏感问题,又能确保控制条件在训练早期就能产生影响,从而加速收敛过程。
此外,ControlNeXt 还通过控制模块学习将条件信息映射到隐空间特征,从而使这些特征更加抽象和语义化,更有助于泛化到未曾遇到的控制条件。
项目主页:
论文链接:
GitHub:
(注:似乎您提供的文本不完整,如果有多于 "GitHub:" 的内容,请提供完整的信息以便我能更准确地帮助您重写。)
本文出自微信公众号:量子位(ID:QbitAI),作者:克雷西