微软发布了Phi-3.5系列人工智能模型:具备128K的上下文窗口,并首次采用混合专家模型。
编辑日期:2024年08月21日

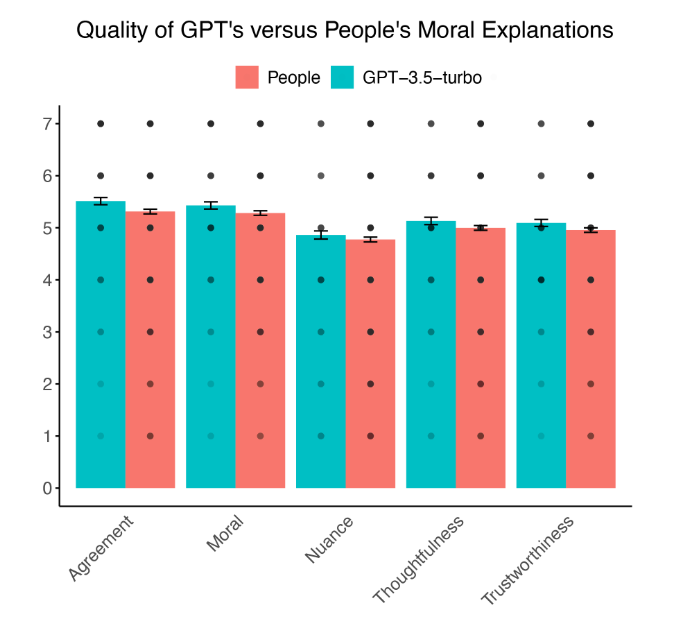
本次发布的 Phi-3.5 系列涵盖了三个轻量级的 AI 模型:Phi-3.5-MoE、Phi-3.5-vision 与 Phi-3.5-mini。这些模型是基于合成数据及经过筛选的公开网站内容构建而成,具备 128K 的上下文窗口。目前,所有这些模型均已按照 MIT 许可协议在 Hugging Face 平台上提供访问。以下是相关介绍:
Phi-3.5-MoE是Phi系列中首次采用混合专家(MoE)技术的模型。该模型基于16个3.8B的MoE模型,通过仅激活2个专家实现了66亿个参数,并且在4.9T的标记上使用512个H100进行了训练。
微软的研究团队从零开始设计此模型,旨在进一步提升其性能。在标准的人工智能基准测试中,Phi-3.5-MoE的表现超越了Llama-3.1 8B、Gemma-2-9B及Gemini-1.5-Flash,并且接近当前的领先者GPT-4o-mini。
Phi-3.5-vision拥有42亿个参数,采用256个A100 GPU在500B标记上进行了训练,现在支持多帧图像理解和推理。
Phi-3.5-vision 在 MMMU(从 40.2 提升到 43.0)、MMBench(从 80.5 提升到 81.9)以及文档理解基准 TextVQA(从 70.9 提升到 72.0)上的表现均有提升。
Phi-3.5-mini 是一个拥有 38 亿参数的模型,它超越了 Llama3.1 的 80 亿参数和 Mistral 的 70 亿参数模型,甚至可以与 Mistral NeMo 的 120 亿参数模型相媲美。
该模型在3.4T的标记上利用512个H100进行了训练。尽管该模型仅包含3.8B的有效参数,但在多语言任务中的表现极具竞争力,甚至可以媲美那些拥有更多有效参数的大型语言模型(LLMs)。
此外,Phi-3.5-mini现在支持128K的上下文窗口,而其主要竞争对手Gemma-2系列仅支持8K。
大家在看