多模态模型评估框架lmms-eval已发布!它实现了全面覆盖、低成本和零污染。
编辑日期:2024年08月21日
随着对大型模型研究的不断深化,将其应用扩展到更多模态已成为学术界和产业界关注的焦点。近期发布的闭源大型模型,如GPT-4o、Claude 3.5等,已展现出卓越的图像理解能力;同时,像LLaVA-NeXT、MiniCPM、InternVL这样的开源领域模型也在不断逼近闭源模型的表现。
在这个模型性能飞速提升、新成果层出不穷的时代,建立一套简单、标准且可复现的多模态评估框架显得尤为重要,但实现起来却颇具挑战。
为应对这些挑战,南洋理工大学LMMs-Lab的研究人员共同开源了LMMs-Eval,这是一款专门为多模态大型模型设计的评估框架,旨在为多模态模型(LMMs)的评测提供一站式、高效的解决方案。

- 代码仓库: https://github.com/EvolvingLMMs-Lab/lmms-eval
- 官方主页: https://lmms-lab.github.io/
- 论文地址: https://arxiv.org/abs/2407.12772
- 榜单地址: https://huggingface.co/spaces/lmms-lab/LiveBench
自 2024 年 3 月发布以来,LMMs-Eval 框架已经获得了来自开源社区、企业及学术界的广泛合作与贡献。目前,该项目已在 GitHub 上收获了 1,100 颗星标,吸引了 30 多位贡献者参与,共计整合了 80 多个数据集与 10 多种模型,并且这些数字仍在持续增长中。
标准化测评框架
为打造一个标准化的测评平台,LMMs-Eval 具备以下特点:
-
统一接口:基于文本测评框架 lm-evaluation-harness 进行改进与扩展,LMMs-Eval 定义了统一的模型、数据集及评估指标接口,使用户能够轻松地集成新的多模态模型与数据集。
-
一键式启动:项目在 HuggingFace 上托管了 80 多个(并且持续增加中)数据集,这些数据集均经过精心转换,涵盖了所有变体、版本和分割。用户仅需执行一条命令,即可自动下载并测试多个数据集与模型,几分钟后即可获取结果。
-
透明可复现:内置统一的日志工具确保了每一道题目及其答案的正确性都被完整记录,从而保证了实验结果的可复现性和透明度。这也有助于直观地比较不同模型之间的优劣。
LMMs-Eval 致力于让未来的多模态模型开发者不必再自行编写数据处理、推理逻辑及提交代码。在当前多模态测试集相对集中的情况下,这样的工作模式不仅效率低下,所得分数也难以与其他模型进行直接比较。通过采用 LMMs-Eval,模型开发者可以更加专注于模型本身的提升与优化,而非在评估与结果对齐上花费过多时间。
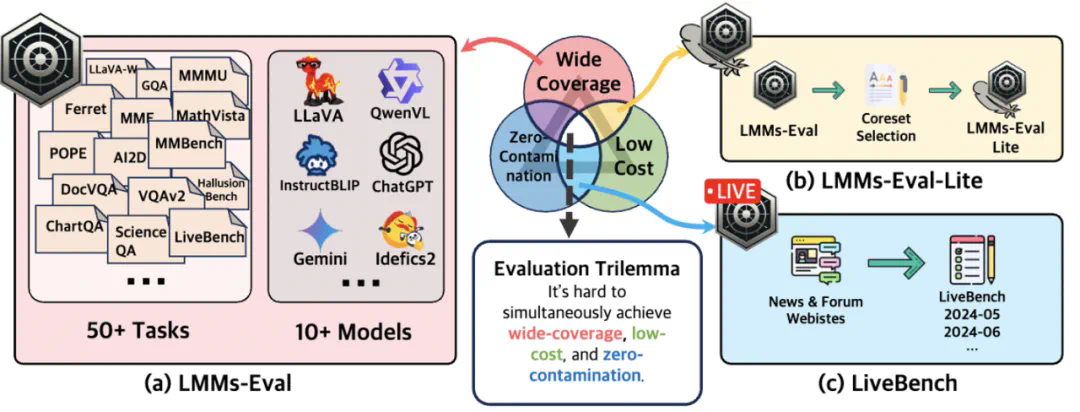
面对测评的“不可能三角”,LMMs-Eval 努力寻求平衡。
LMMs-Eval 的终极目标是寻找一种方法来评估多模态模型 (LMMs),这种方法需要满足三个条件:1. 范围广泛 2. 成本低廉 3. 数据零泄漏。即便有了 LMMs-Eval,作者团队仍然发现要同时实现这三个要求极其困难,甚至可能是无法达成的。如以下示意图所示,当评估数据集的数量扩展至超过 50 个时,对所有这些数据集进行全面评估会变得极其耗时。此外,在训练过程中,这些基准测试还容易遭受数据污染的影响。为了解决这些问题,LMMs-Eval 引入了 LMMs-Eval-Lite,以实现范围广泛与成本低廉之间的平衡。同时,他们也设计了 LiveBench 来确保成本低廉与数据零泄漏。
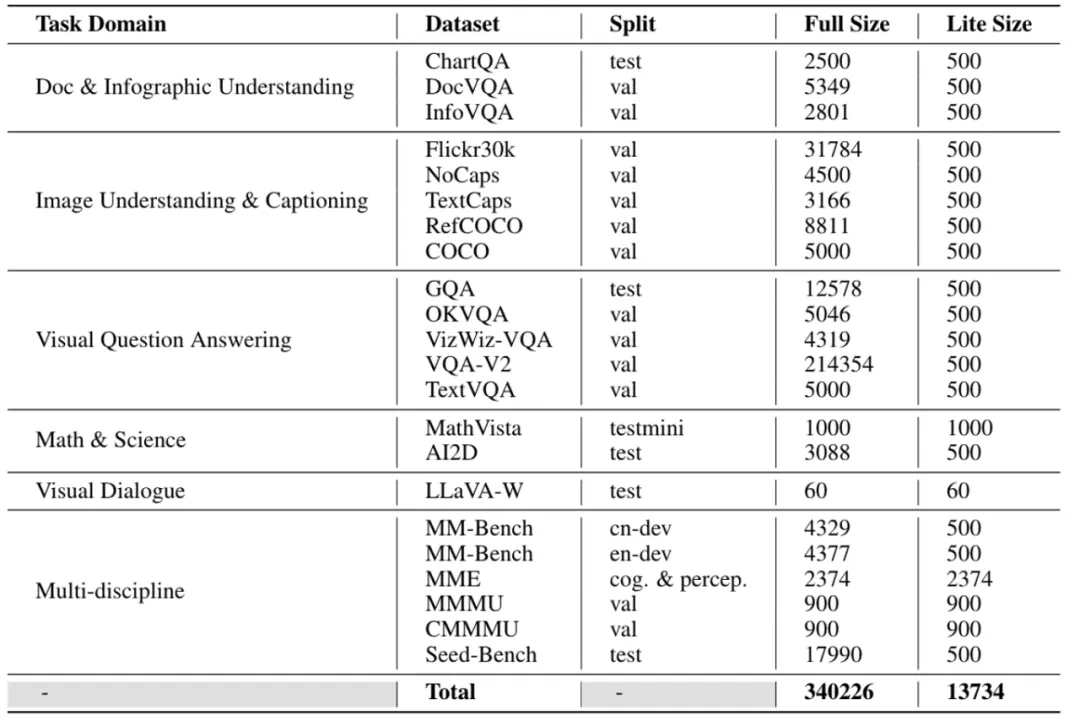
LMMs-Eval-Lite: 范围广泛的轻量级评估
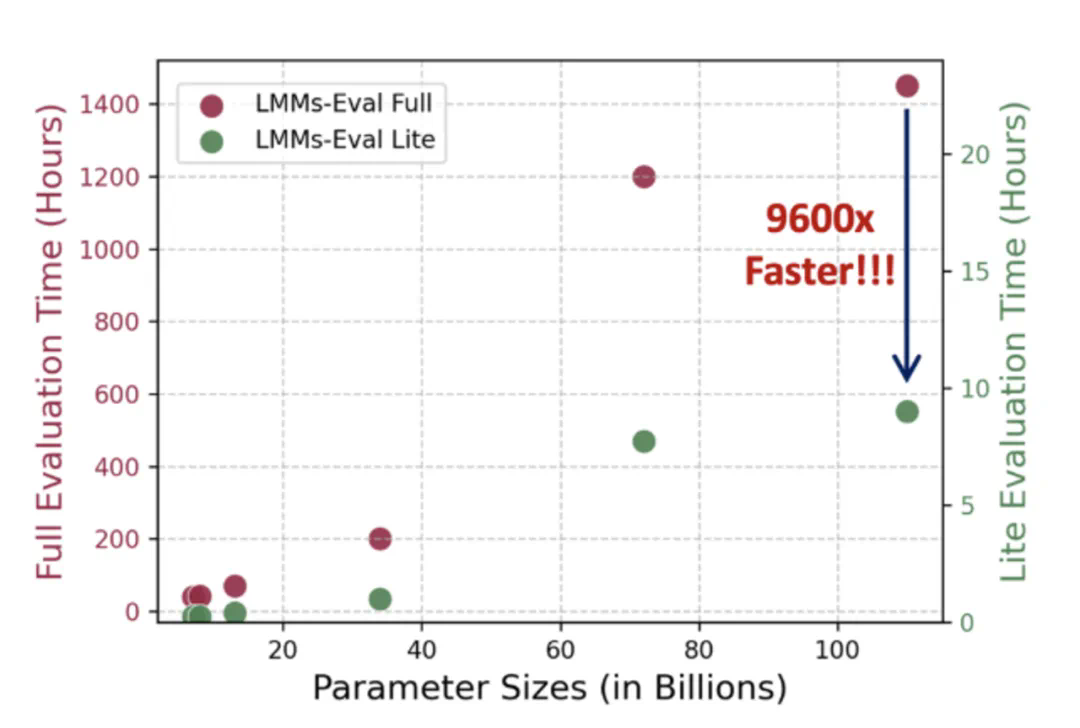
在评估大型模型时,通常由于模型参数量庞大以及测试任务繁重,会导致评估时间和成本急剧增加。因此,人们往往选择使用较小或特定的数据集来进行评估。然而,这种有限的评估往往会导致对模型能力理解的缺失。为了同时保证评估的多样性和控制成本,LMMs-Eval 推出了 LMMs-Eval-Lite。
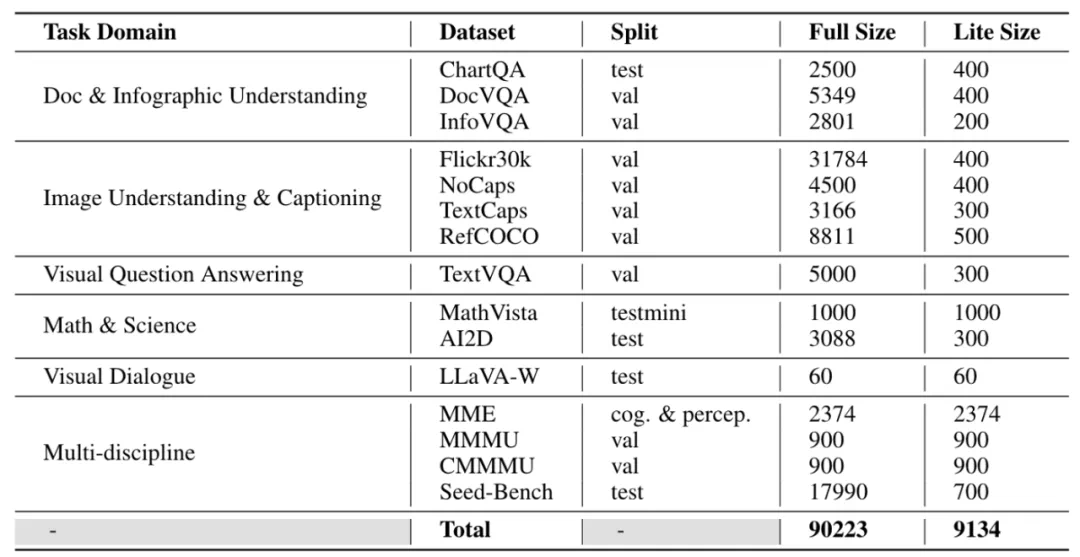
LMMs-Eval-Lite 的目标是创建一个简化的基准测试集,以便在模型开发过程中提供有效而迅速的反馈,避免当前测试集过于庞大的问题。如果能找到现有测试集中的一部分样本,使得模型在这部分样本上的绝对得分和相对排名与完整数据集相近,那么我们可以合理地认为精简这些数据集是可行的。为了识别数据集中的关键数据点,LMMs-Eval 首先利用 CLIP 和 BGE 模型将多模态评估数据转化为向量嵌入,并采用 k-贪婪聚类方法来确定关键数据点。实验表明,这些较小规模的数据集依然能展现出与完整数据集类似的评估效果。
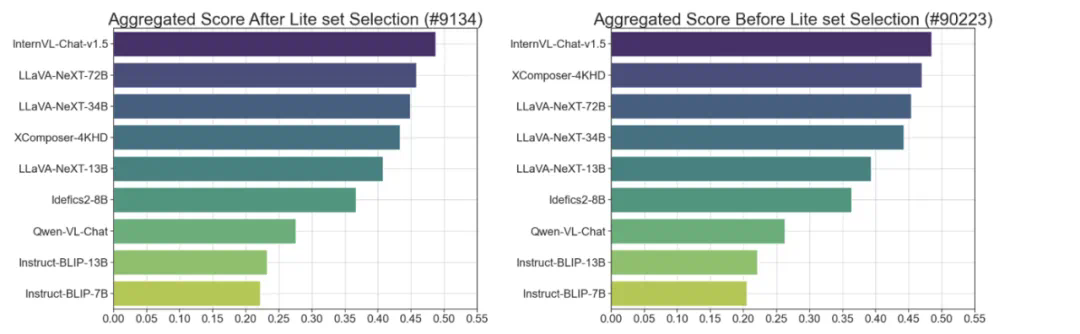
接下来,LMMs-Eval 采用了同样的方法创建了一个包含更多数据集的 Lite 版本,这些数据集旨在帮助降低模型开发过程中的评估成本,以便更快地评估模型性能。
LiveBench:LMMs 动态测试
传统的基准测试侧重于使用固定的问答对进行静态评估。随着多模态研究的发展,开源模型在评分上往往超越商用模型(如 GPT-4V),但在实际用户体验方面却存在差距。动态的、以用户为中心的 Chatbot Arenas 和 WildVision 等评估方式逐渐受到青睐,但这类评估需要收集大量的用户偏好信息,成本非常高昂。
LiveBench 的核心理念是在持续更新的数据集上评估模型的表现,以此实现无污染且成本低廉的测试环境。作者团队从互联网上搜集评估数据,并建立了一条自动化流水线,用于从新闻站点与社区论坛等网站自动收集最新的全球资讯。为了确保信息的新鲜度与真实性,他们选择了包括 CNN、BBC、日本的朝日新闻与中国新华通讯社在内的60多家新闻机构及Reddit等论坛作为信息源。具体流程如下:首先捕捉网站主页的截图并移除广告和其他非新闻内容。
接下来,利用当前最先进的多模态模型(例如GPT4-V、Claude-3-Opus 和 Gemini-1.5-Pro)来设计问题及其答案集。然后,通过另一个模型审核并修正这些问题,确保其准确性与相关性。
最后,人工审核这套最终的问答集,每月大约收集500个问题,从中筛选出100至300个问题作为LiveBench的最终问题集。
评分则参照LLaVA-Wilder和Vibe-Eval的标准进行——评分模型依据提供的标准答案给分,分数范围是1到10分。默认的评分模型是GPT-4o,同时也包括Claude-3-Opus 和 Gemini 1.5 Pro作为备选方案。最终报告中的结果会将这些分数转换为0到100的准确率指标。
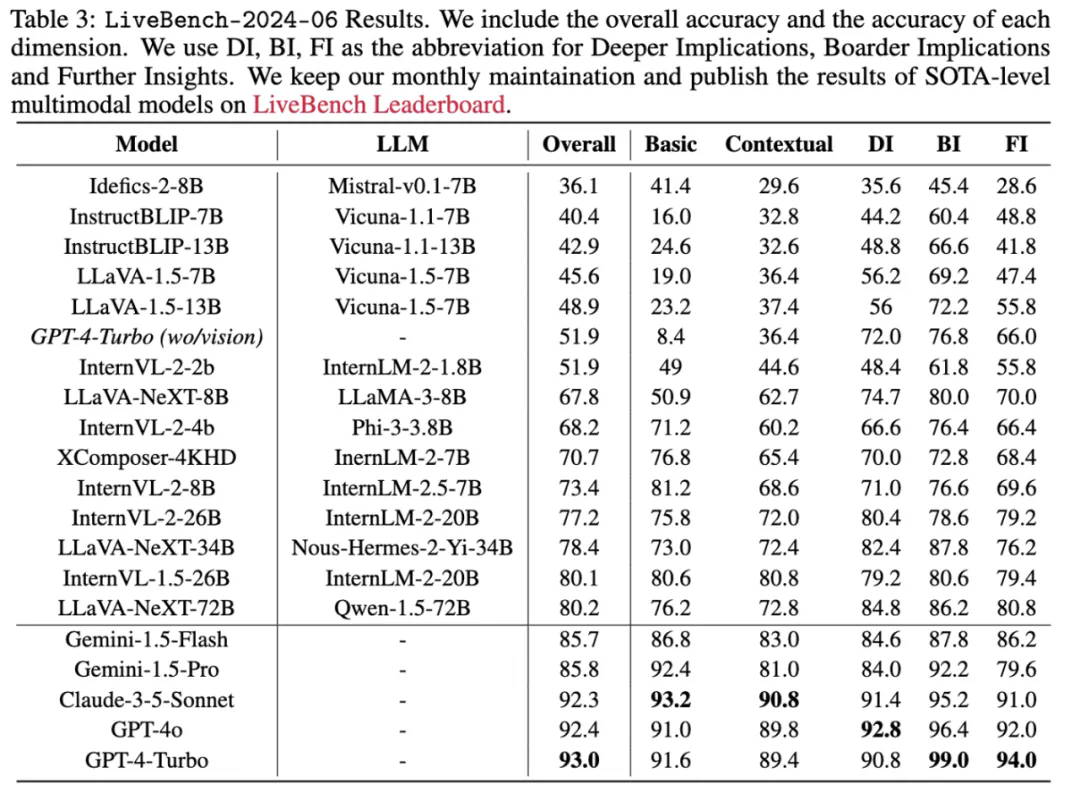
未来,你还可以通过我们动态更新的排行榜查看多模态模型在每月更新的数据集上的表现,以及它们在排行榜上的最新成绩。