已经明确:在文本数据中加入一些代码,训练出来的大模型会更强大、更通用。
编辑日期:2024年08月22日
原来代码知识如此重要。
现在提及大型语言模型(LLM),编程技能似乎已成为“君子六艺”中不可或缺的一部分。
即便不是专为代码设计的大型模型,在预训练数据集里包含代码内容已经成为常态。尽管业内普遍认同代码数据对于通用LLM的表现至关重要,但对于代码如何具体影响非代码任务的研究却相对有限。
在Cohere等机构最近提交的一份研究中,研究人员系统地探讨了代码数据对通用大型模型性能的影响。

论文链接:https://arxiv.org/abs/2408.10914
他们提出了一个问题:“在预训练过程中使用的代码数据,除了代码生成之外,对其他各种下游任务有何影响?”为了回答这个问题,作者们广泛地进行了消融测试与评估,涵盖了多样的自然语言推理任务、世界知识任务、代码基准以及LLM作为裁判时的胜负比率,所用模型的参数规模从4.7亿至2.8亿个不等。
在不同的配置下,研究发现了一致的结果:代码是实现泛化的重要组成部分,其作用远不止于编码任务本身;代码质量的提升对所有任务都产生了显著影响。在预训练阶段重视代码质量和保留代码数据,能带来积极的效果。
几个关键因素包括:确保代码占比适当、通过引入合成代码及与代码相关的数据(如提交记录)来提升代码质量,以及在冷却期等多个训练阶段充分利用代码。研究结果显示,代码是实现泛化的关键基石,其作用远远超越了编码任务的范畴,而代码质量的提高对于表现有着巨大的正面影响。
更进一步地,作者们对一系列基准进行了广泛的评估,覆盖了世界知识任务、自然语言推理、代码生成以及LLM担任评判者的胜率。通过对参数量从4.7亿到28亿的模型进行实验后,以下是详细的发现:
重写文本
-
引入代码能够显著提升非代码任务的表现。利用代码预训练模型进行初始化可以增强自然语言处理任务的效果。具体来说,相较于仅采用纯文本的预训练方式,加入代码后,自然语言推理的能力相对提高了8.2%,对世界知识的理解提升了4.2%,生成内容的质量增加了6.6%,而代码本身的性能则提高了12倍之多。
-
代码的质量及其特征至关重要。使用具有标记风格的编程语言、邻近的代码数据集(如GitHub提交记录)以及合成生成的代码能够优化预训练效果。特别是,相比于使用基于网络的代码数据进行预训练,利用高质量的合成生成代码数据训练模型可以分别将自然语言推理和代码性能提升9%和44%。另外,与未包含任何代码数据的模型相比,含有合成数据的模型通过持续预训练的方式可以使自然语言推理能力和代码性能分别相对提升1.9%和41%。
-
在冷却过程中加入代码数据能进一步改善所有任务的表现。在预训练冷却阶段中加入代码数据,并对高质量的数据集赋予更高的权重,相较于冷却前的模型,自然语言推理的性能提升了3.6%,世界知识的理解增加了10.1%,代码性能提升了20%。更为重要的是,包含代码数据的冷却过程相较于基线模型(无冷却模型)提高了52.3%的成功率,其中,这一成功率比不含代码数据的冷却过程高出了4.1%。
方法概述
在方法部分,研究者从预训练数据、评估标准、训练流程及模型细节四个方面进行了详细的介绍。如下图1所示为整体的实验框架。
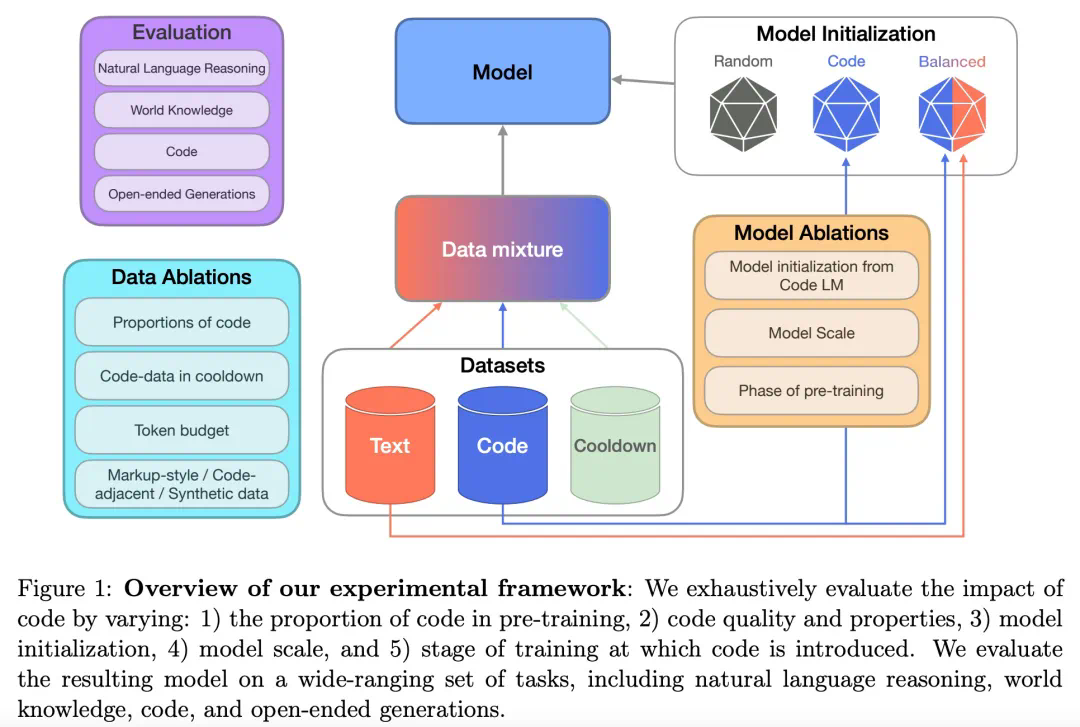
预训练数据
研究者详细阐述了预训练及冷却(Cooldown)数据集的相关信息。他们的目标是在遵循现有SOTA实践的基础上,探究代码在预训练中的作用。因此,他们的预训练流程包括了持续预训练和冷却两个阶段。
持续预训练指的是在一个预训练模型的基础上进行初始化,并在固定的词汇量预算内继续训练该模型。冷却则是在训练接近尾声时提升高质量数据集的重要性,并对较小规模的词汇量实施学习率衰减。对于文本数据集方面,研究者采用SlimPajama预训练语料库作为自然语言文本的主要来源。
至于代码数据集,为了探究不同特性代码数据的效果,研究者利用了多种类型的代码资源,具体包括:
-
基于网络的代码数据:这是最主要的代码数据来源,包括用于训练StarCoder的Stack数据集。此数据集涵盖了从GitHub抓取的开源许可代码数据。研究者通过质量过滤并选取文档数量排名前25位的编程语言。完成所有过滤步骤后,仅代码和标记子集的规模达到139亿个词汇单位。
-
Markdown数据:研究者特别处理了类似Markdown、CSS和HTML这样的标记语言。经过所有过滤步骤后,标记子集的规模总计180亿个词汇单位。
-
合成代码数据:为了进行代码数据集的消融分析,研究者采用了专门生成的合成代码数据集,其中包含正式验证过的Python编程问题。这部分高质量代码数据集最终规模为32亿个词汇单位。
-
相关代码数据:为了进一步探索不同特性的代码数据,研究者还收集了包含GitHub提交、Jupyter笔记本、StackExchange讨论帖等辅助信息的相关代码数据。这类数据总量为214亿个词汇单位。
-
预训练冷却数据集:冷却策略意味着在预训练的后期阶段增加高质量数据集的比重。为此,研究者挑选了一组包含高质量文本、数学、代码及指导性文本的数据集进行预训练冷却混合。
评估如下:
本文旨在系统性地探究代码对通用任务性能影响,并因此采用了一套广泛的评估体系,覆盖了多样化的下游任务,包括代码生成。研究者基于三个方面的基准对模型进行了评估:1)世界知识、2)自然语言推理及 3)代码性能。此外,他们还报告了通过LLM-as-a-judge方法评估得到的胜率。
下表1列出了完整的评估组件及其对应的任务、数据集和评价指标。
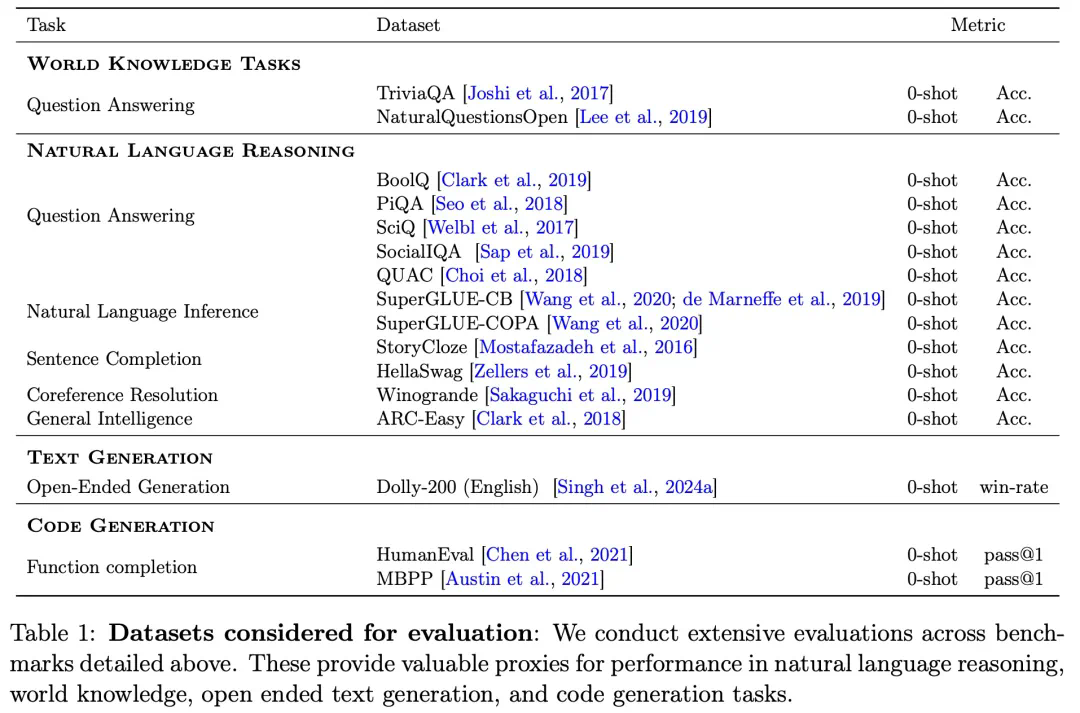
研究者对不同规模的模型(参数量从470M到2.8B)进行了性能测试。考虑到最小规模模型的能力有限,为了确保公平对比,他们仅针对所有模型都能达到随机性能以上的基准进行了比较。
除了针对特定任务的判别性能评估外,研究者还利用LLM-as-a-judge方法评估了模型的生成性能。
训练与模型详情
正如前述,研究者采用了参数量介于470M至2.8B之间的自回归Transformer解码器模型进行预训练。这些模型遵循标准的语言建模目标进行训练。
具体而言,研究者使用了并行注意力层、SwiGLU激活函数、无偏置的全连接层以及具有256,000词汇量的字节对编码(BPE)分词器。所有模型均采用AdamW优化器进行预训练,批处理大小为512,使用余弦学习率调度器,预热步骤为1,325,最大序列长度设定为8,192。
在基础设施方面,研究人员采用TPU v5e芯片来进行模型的训练和评估,并且所有模型均使用FAX框架进行训练。为了确保消融评估的严谨性,研究人员共计预训练了64个模型。每次预训练使用200B tokens的数据量,其中470M参数的模型消耗了4736 TPU小时,而2.8B参数的模型则消耗了13824 TPU小时。冷却运行阶段则使用了40B tokens的数据量,对于470M参数的模型而言,这相当于1024 TPU小时的工作量。
该研究通过一系列系统性的实验来探讨以下关键因素对模型性能的影响:
- 使用包含大量代码数据的语言模型(LM)来初始化大型语言模型(LLM)
- 模型的规模
- 预训练数据中代码数据的比例变化
- 代码数据的质量及其特性
- 预训练冷却过程中代码数据的作用
为了验证使用含有大量代码数据的LM作为初始化能否提升模型性能,研究人员进行了不同预训练模型初始化的实验。根据图2所示,使用100%代码数据进行预训练的模型(code→text)作为初始化,能在自然语言(NL)推理基准测试中取得最佳表现,紧随其后的则是balanced→text模型。
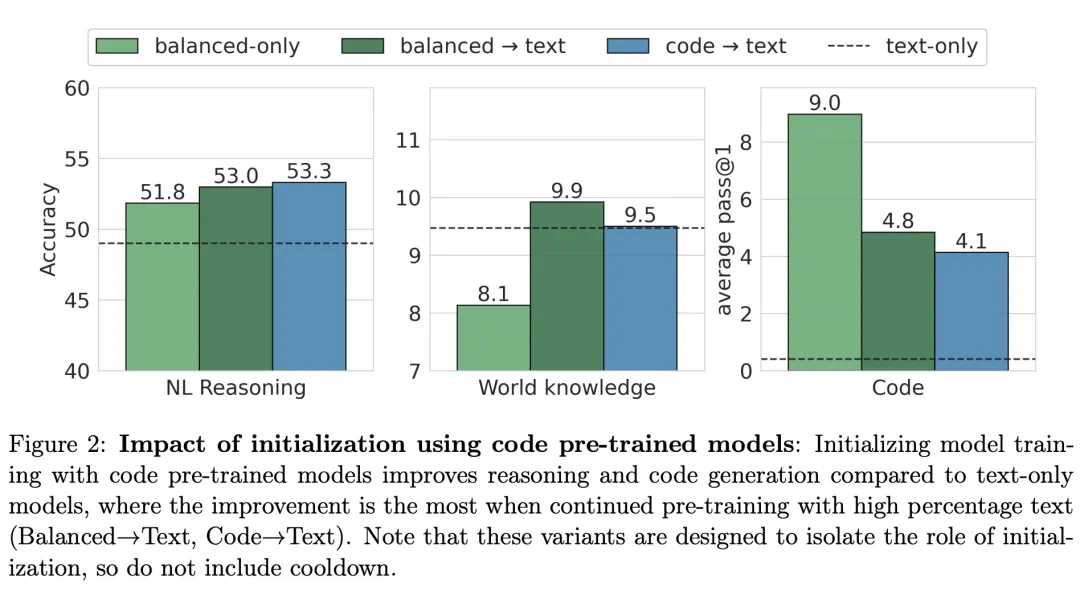
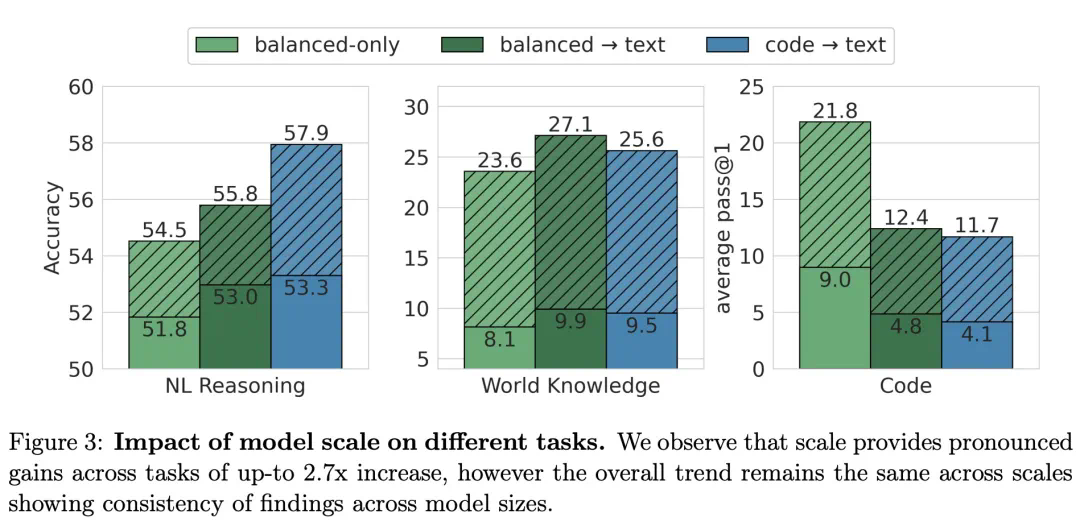
为进一步探究上述结果是否同样适用于更大规模的模型,研究人员以与470M模型相同的token预算训练了一个2.8B参数的模型。下图展示了2.8B模型与470M模型之间的对比结果。
该研究探讨了预训练过程中代码数据占比对不同任务模型性能的影响。研究发现,随着预训练中代码数据比例的增加,代码任务的表现呈现线性提升趋势;而对于自然语言(NL)推理任务及涉及世界知识的任务,则存在一个使效果最优的代码数据比例范围。
如图5(a)所示,在评估代码质量与组成的影响时,研究发现引入不同来源的代码或合成代码都能促进自然语言任务的表现提升。然而,仅当使用合成生成的代码时,代码任务的表现才会得到改善。
图5(b)显示,在自然语言推理任务与代码任务上,采用balanced+synth→text的预训练策略相较于balanced→text分别实现了2%和35%的相对性能提升。这一结果进一步证明,即使是少量的高质量代码数据也能同时增强代码相关与非代码相关任务的表现。
如图6所示,研究发现,在预训练过程中包含代码数据后,模型在自然语言推理上的性能提升了3.6%,世界知识相关的任务表现提高了10.1%,而代码任务的表现则提升了20%。
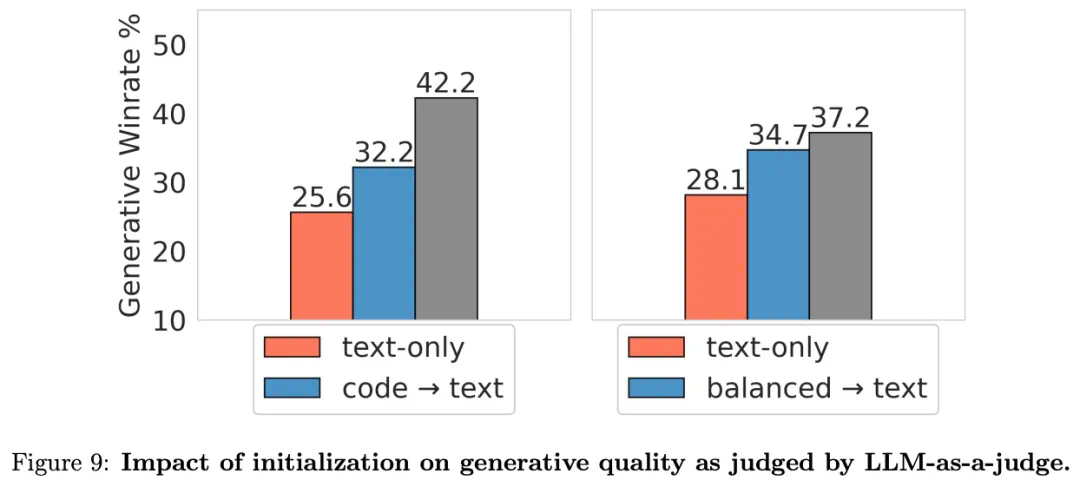
图7揭示了预训练过程中的冷却阶段对生成性能的重要影响,特别是对于通过胜率衡量的生成质量。
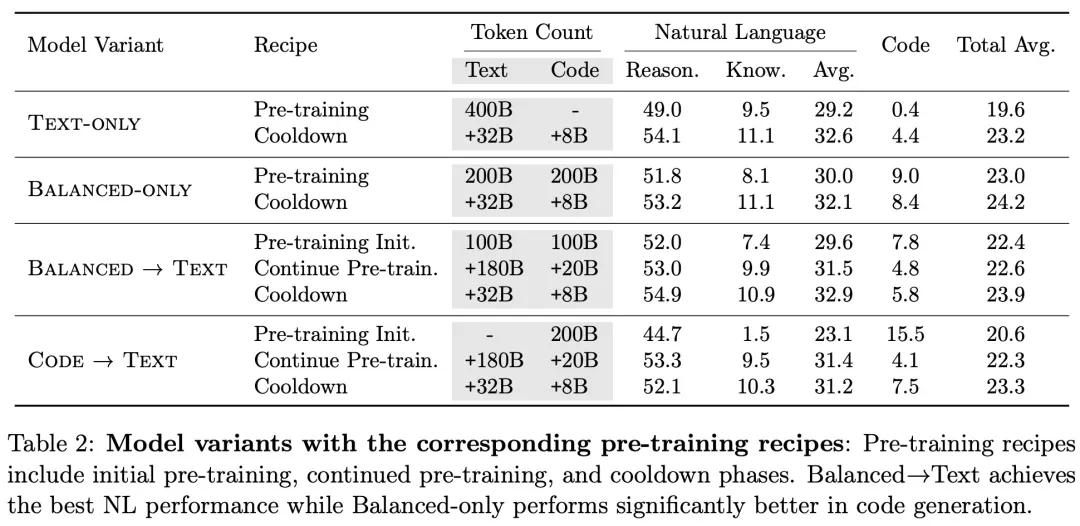
表2汇总了采用不同预训练方案的模型性能对比结果,其中Balanced→Text在自然语言任务上取得了最佳成绩,而Balanced-only在代码生成任务中表现尤为突出。
(注:由于技术限制,这里无法直接显示图片内容,仅提供了图片链接。)