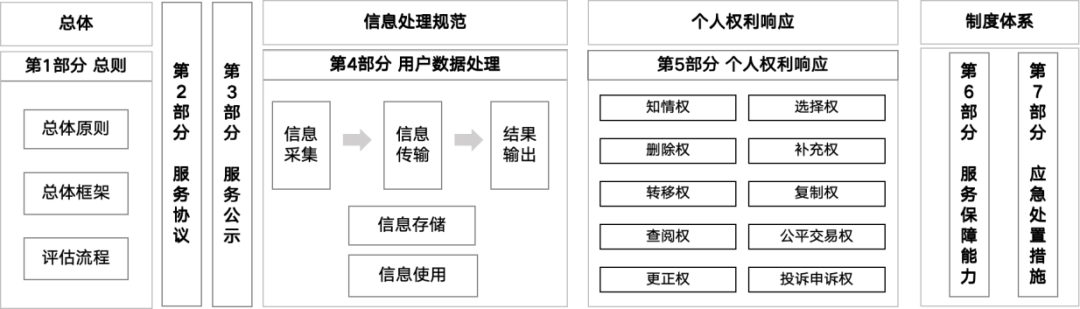
Meta开发新方法:融合语言与扩散AI模型,以减少计算量、提升运行效率并优化生成图像。
编辑日期:2024年08月24日
根据团队的介绍,Transfusion 结合了语言模型在处理文本等离散数据方面的优点,以及扩散模型在生成图像等连续数据方面的能力。
Meta解释称,当前的图像生成系统通常采用预训练的文本编码器来处理输入的提示词,随后将其与独立的扩散模型结合以生成图像。
许多多模态语言模型的工作原理与此相似,它们将预训练的文本模型与专门用于其他模态的编码器相结合。
不过,Transfusion 使用单一且统一的 Transformer 架构,适用于所有模式,并对文本及图像数据进行端到端的训练。对于文本和图像,它采用了不同的损失函数:文本使用下一个标记预测,而图像则使用扩散模型。
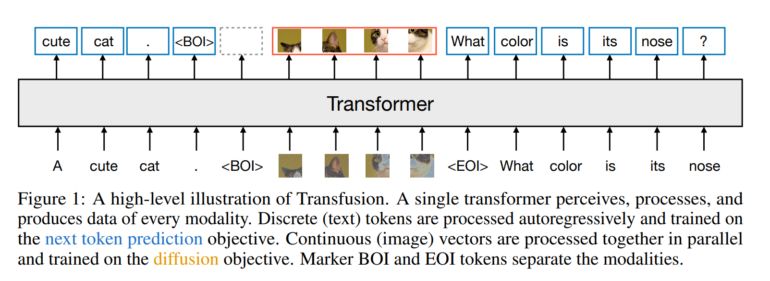
为了同时处理文本和图像,图像被转化为图像片段序列。这样一来,模型能够在同一个序列中同时处理文本标记和图像片段,而特殊的注意力掩码还能使模型捕捉到图像内部的关系。
与Meta现有的Chameleon方法(将图像转换为离散标记,然后以处理文本的方式进行处理)不同,Transfusion保留了图像的连续表示,从而避免了因量化而导致的信息损失。
实验同样显示,在与同类方法的比较中,“融合”展现了更高效的可扩展性。在图像生成领域,它以显著降低的计算成本实现了接近专业模型的效果,更令人惊喜的是,图像数据的融入还进一步提升了文本处理的能力。

研究人员在一个拥有70亿参数的模型上进行了2万亿个文本和图像标记的训练。该模型在图像生成方面的表现可与DALL-E 2等成熟系统相媲美,同时还能够处理文本任务。
请附上参考地址。
(注:原文并不是一个完整的句子,因此重写时添加了一些词汇以形成完整的句子。)