浪潮信息发布的源2.0-M32大模型4位/8位量化版本:运行时只需23GB显存,其性能宣称可与LLaMA3媲美。
编辑日期:2024年08月24日
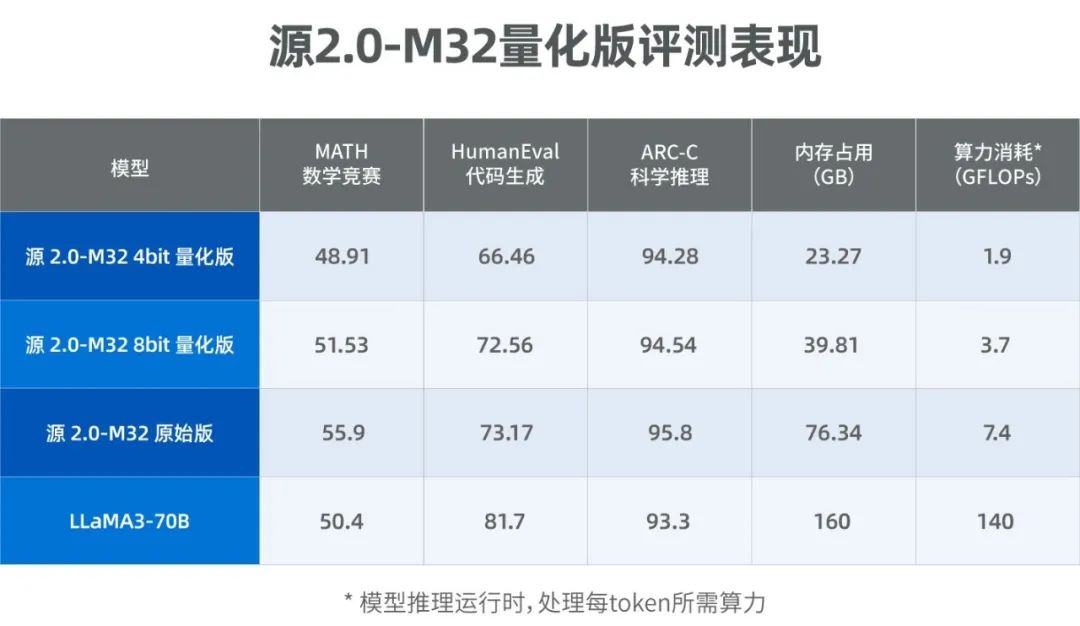
4位量化版本的推理运行显示内存只需23.27GB,处理每个token所需的计算力约为1.9 GFLOPs,其计算力消耗仅为同等规模的大模型LLaMA3-70B的1/80。相比之下,LLaMA3-70B的运行显示内存为160GB,所需计算力为140 GFLOPs。
根据浪潮信息的介绍,源2.0-M32量化版是由“源”大模型团队推出的一个版本,旨在提升模型计算效率并减少大型模型部署和运行时所需的计算资源。该版本将原始模型的精度量化到了int4和int8级别,同时保持了模型性能的基本稳定不变。
源2.0-M32大型模型是浪潮信息“源2.0”系列大型模型的最新版,它构建了一个包含32个专家(Expert)的混合专家模型(MoE),在模型运行时激活的参数数量为37亿。
评测结果表明,在MATH(数学竞赛)和ARC-C(科学推理)任务中,源2.0-M32量化版的表现超越了拥有700亿参数的LLaMA3大型模型。
源2.0-M32量化版已经开放源代码,以下为下载链接:
ModelScope平台的下载链接