得益于Transformer,Mamba现在更强大了!仅使用1%的计算量就达到了新的状态-of-the-art(SOTA)水平。
编辑日期:2024年08月24日
Mamba 的作者领头打造:
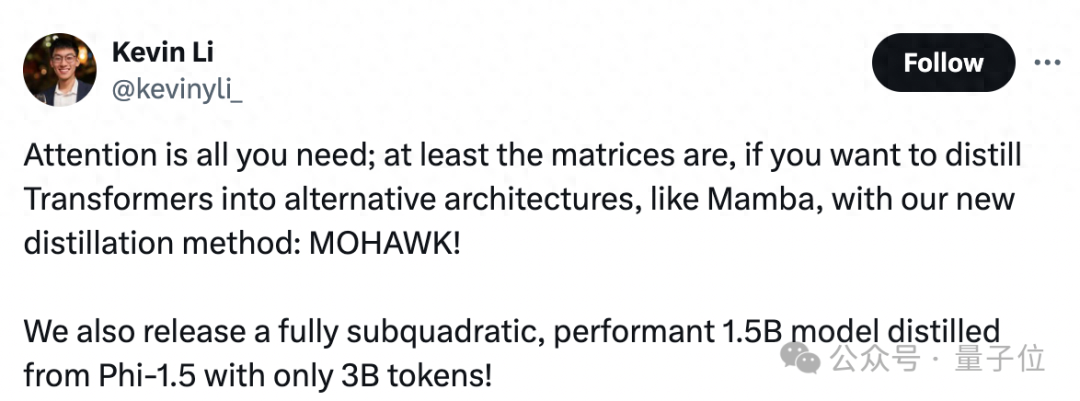
“Attention is all you need” —— 至少在 Mamba 架构中确实如此。
Mamba 架构最新突破:只需原先 1% 的计算量,新模型即可达到最前沿的状态(State-Of-The-Art, SOTA)表现。
这一切成就,皆得益于 Transformer 的加持。
通过高效地将 Transformer 模型中的知识迁移到 Mamba 等其他架构上,新模型能够在保持较低计算成本的同时实现更优的表现。
这一成果由 Mamba 的主要创作者之一 Albert Gu 领衔完成。
值得注意的是,这种方法不仅适用于 Mamba,还可以应用于其他非 Transformer 架构。
由于 Transformer 依赖于二次自注意力机制,这导致其计算量较大。
这种机制虽然能使模型有效地捕捉序列数据中的长程依赖关系,但因二次时间复杂度(即当输入规模翻倍时,模型所需的计算时间会增加四倍),处理长序列时计算成本高昂。
为解决这一问题,学术界提出了许多新架构,例如 Mamba 和 RWKV,这些架构的微调与推理成本更低。
鉴于 Transformer 模型预训练已投入了大量的计算资源,研究者们思考是否可以在已有基础上进一步提升效率?
因此,在这项研究中,他们提出了一种名为 MOHAWK 的蒸馏方法,利用预训练的 Transformer 模型来训练 SSMs 模型。
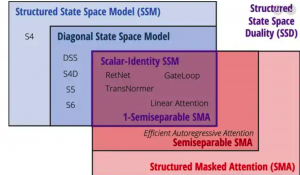
该方法的核心在于注意力机制、线性注意力、以及 Mamba 的结构化掩码注意力 SMA 等,这些机制均作为跨输入长度的序列变换,各自具有相应的矩阵混合器,如 softmax。
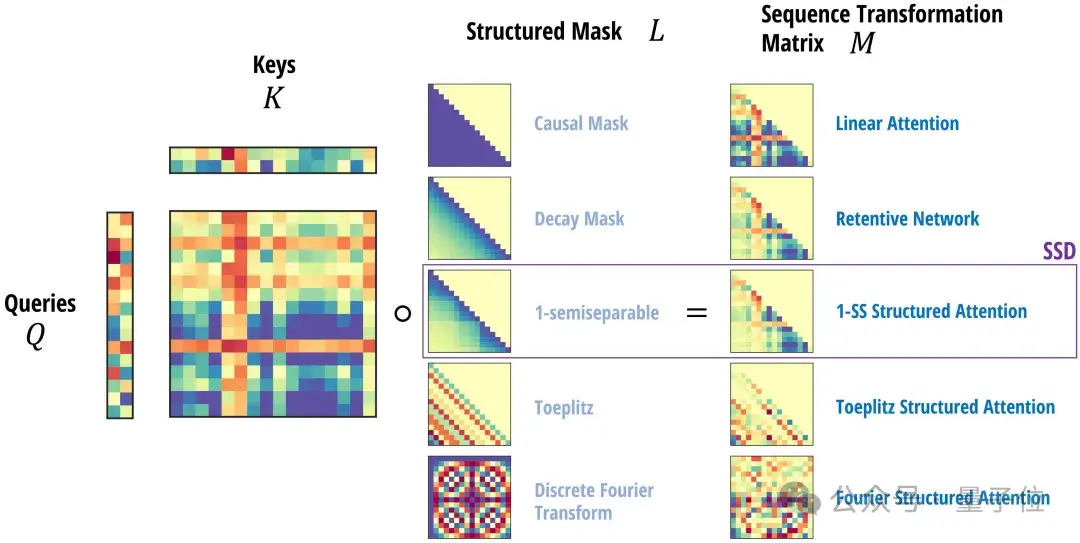
可以通过将注意力机制和状态空间模型 (SSMs) 视为运用不同类型的矩阵来混合各令牌嵌入的方法,来解析序列模型架构,将其拆解为独立的序列混合与通道混合模块。例如,Transformer 由注意力模块(序列混合器)和多层感知机(MLP,通道混合器)构成,采用这样的拆解方式有助于提炼模型的各个组成部分。
具体提炼过程可分为三个步骤:
第一步:矩阵定向(Matrix Orientation)。即对序列变换矩阵本身进行对齐。
第二步:隐藏状态对齐(Hidden-State Alignment)。即对网络每一层的隐藏状态表示进行对齐,并确保不会损害已预学习的表示。
第三步:权重迁移与知识蒸馏(Weight-Transfer and Knowledge Distillation)。通过端到端的训练阶段实现权重迁移,并最终仅用一小部分训练数据来蒸馏网络的输出结果。
实际操作时,我们可以采用这种方法来调整一个模型,例如 Phi-Mamba。
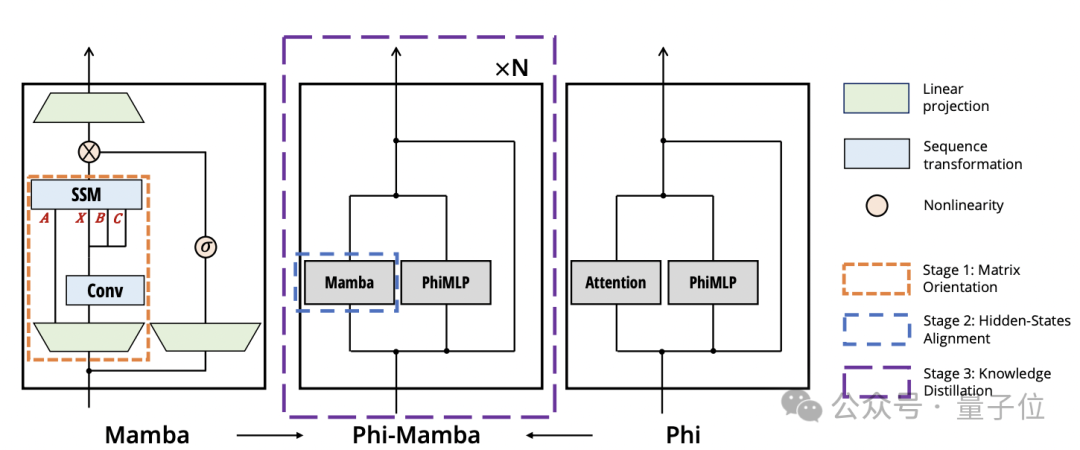
该模型融合了 Mamba-2 和 Phi-1.5 的特点。
借助 MOHAWK 方法,此模型既能从预训练的 Transformer 模型中学习,又具备状态空间模型的特点,在处理长序列方面比传统的 Transformer 架构更为高效。
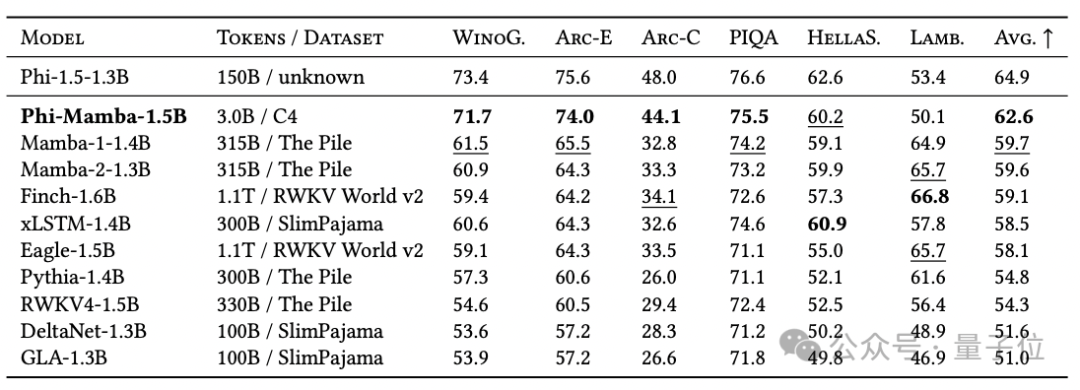
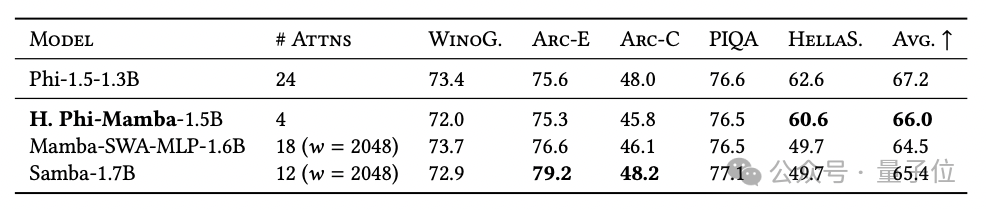
尽管 Phi-Mamba 只用了 3B 个令牌来进行蒸馏,其数据量仅为从零开始训练模型所需数据的 1%,但其性能达到了开源非 Transformer 架构中的顶尖水平(State-of-the-Art, SOTA)。
实验表明,优化隐藏状态对齐能够进一步提升后续阶段的表现。
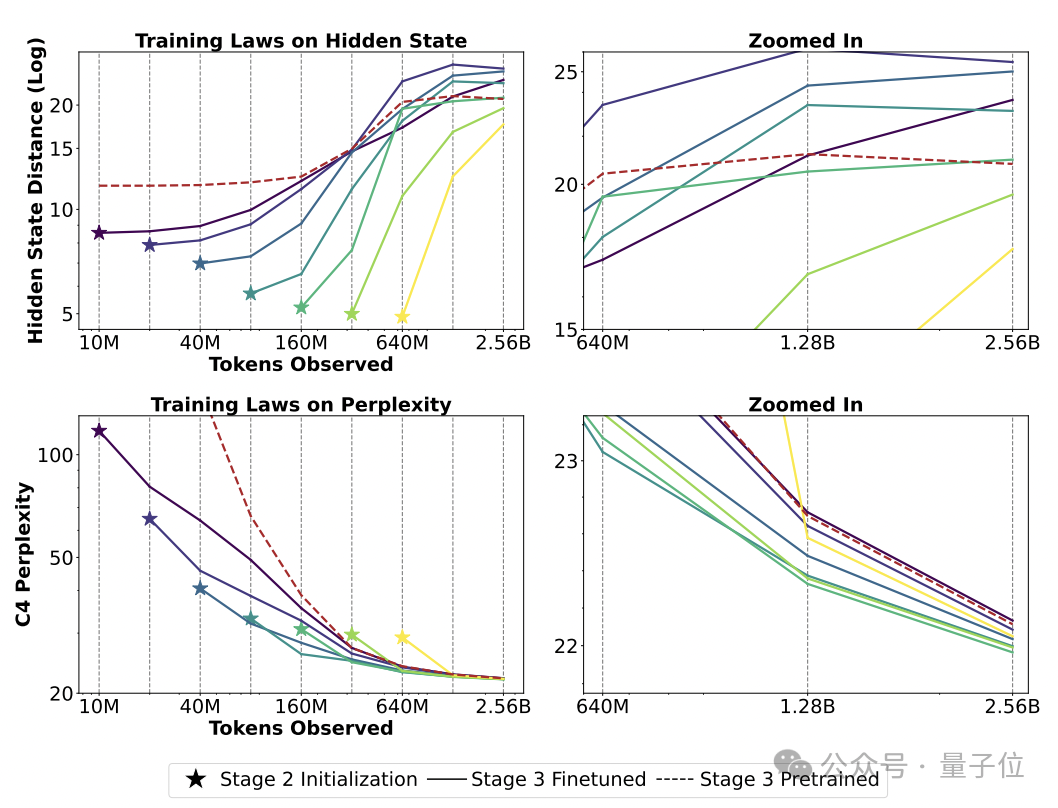
研究团队还推出了混合Phi-Mamba-1.5B模型,该模型通过5B tokens的蒸馏过程开发而成,其性能与同类混合模型相当,但仅使用了4层注意力层。
值得注意的是,这种蒸馏方法不仅适用于Mamba模型。
这项研究由CUM助理教授、同时也是Cartesia AI的联合创始人及首席科学家Albert Gu领导进行。
去年,Albert Gu与FlashAttention的作者Tri Dao共同提出了Mamba模型,这是首个真正意义上在性能上媲美Transformer的时间序列线性模型。
论文链接:https://arxiv.org/abs/2408.10189

Mistral AI与Mamba的结合堪称强强联手,

本文将深入解析“Transformer挑战者”的两大核心理念,
并介绍如何统一两种序列建模架构,

最终融合两者优势,创造出混合模型Jamba。
审稿人要求的实验成本高达5万美元,这都要“归功于”Transformer技术,Mamba。
只需要一份PyTorch的笔记即可。
(注:图片链接并未提供实际内容,因此在文本转换中未使用到图片信息。)