Yann LeCun不太看好强化学习:"我确实更偏好于模型预测控制(MPC)"。请注意,这里的MPC翻译可能需要根据上下文来确定,原文的MPC是指Model Predictive Control,一种控制方法,但在非专业领域可能直接称为“模型预测控制”会引起困惑,一般非专业语境下提到的MPC可能是Multi-Protocol Controller(多协议控制器)或者其他含义,需根据具体语境判断。在此句中,我们假设讨论的是控制理论中的Model Predictive Control。
编辑日期:2024年08月26日
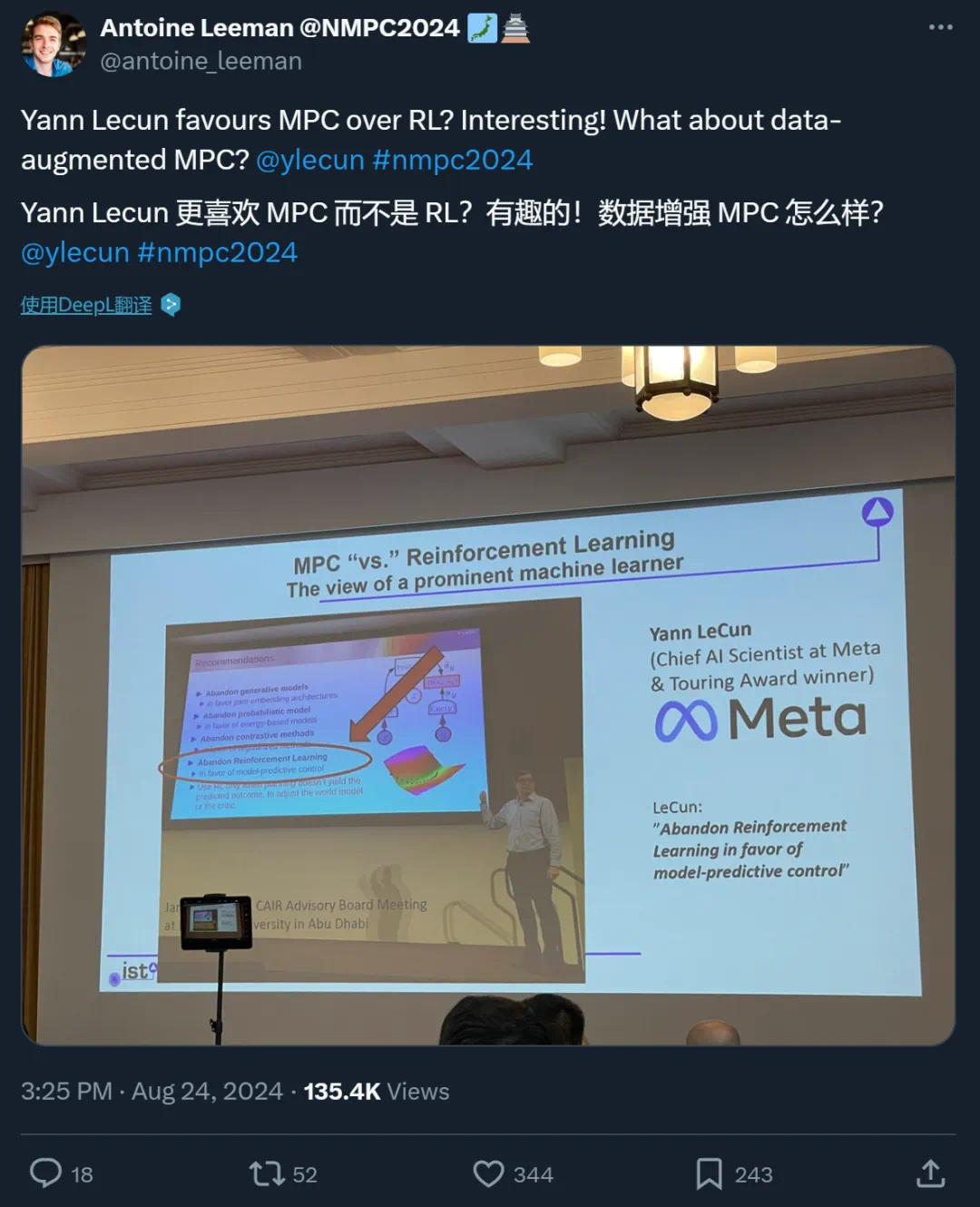
在最近发布的一篇博文中,Meta 的首席人工智能科学家 Yann LeCun 表达了他的观点:“相较于强化学习(RL),我个人更倾向于模型预测控制(MPC)。自从2016年起,我一直强调这一立场。强化学习在学习新任务时往往需要进行大量的尝试,而模型预测控制则展现出零样本学习的能力:只要拥有一个精确的世界模型和明确的任务目标,它就能无需特定任务的学习来解决新任务。这是规划的力量所在。这并不意味着强化学习毫无价值,但其应用应作为最后的选择。”
一直以来,Yann LeCun 对强化学习持批评态度。他认为该方法过于依赖大量的实验数据,效率低下,与人类的学习方式大相径庭——婴儿并非通过观察成千上万的相同物品或盲目尝试危险行为来学习,而是通过观察、预测以及与环境的互动来获取知识,即便缺乏直接监督。
在他半年前的一次演讲中,他甚至提出“应该放弃强化学习”(详情参考《GPT-4 的研究方向是否有前景?Yann LeCun 对自回归模式提出了质疑》)。不过,在后续的访谈中,他澄清了自己的观点,并非彻底摒弃强化学习,而是尽可能减少其使用;正确的系统训练方法应是从观察(可能辅以少量交互)中学习关于世界及其模型的有效表示。
同时,LeCun 还强调,相比强化学习,他更青睐于 MPC(模型预测控制)。
模型预测控制(MPC)是一种基于数学模型实时优化控制系统的先进技术,在限定的时间内实现最佳控制效果。自从20世纪六七十年代首次被提出以来,它已经在化学工程、石油提炼、先进制造、机器人技术和航空航天等多个领域得到了广泛应用。例如,波士顿动力公司最近分享了他们运用MPC进行机器人控制的经验和技术细节(详情请参考《波士顿动力技术揭秘:后空翻、俯卧撑与翻车,6年经验、教训总结》)。MPC的最新进展之一是将其与机器学习技术相结合,形成所谓的ML-MPC。这种方法利用机器学习算法来估计系统模型、进行预测以及优化控制行为。将机器学习与MPC相结合有可能在控制性能和效率方面带来显著提升。
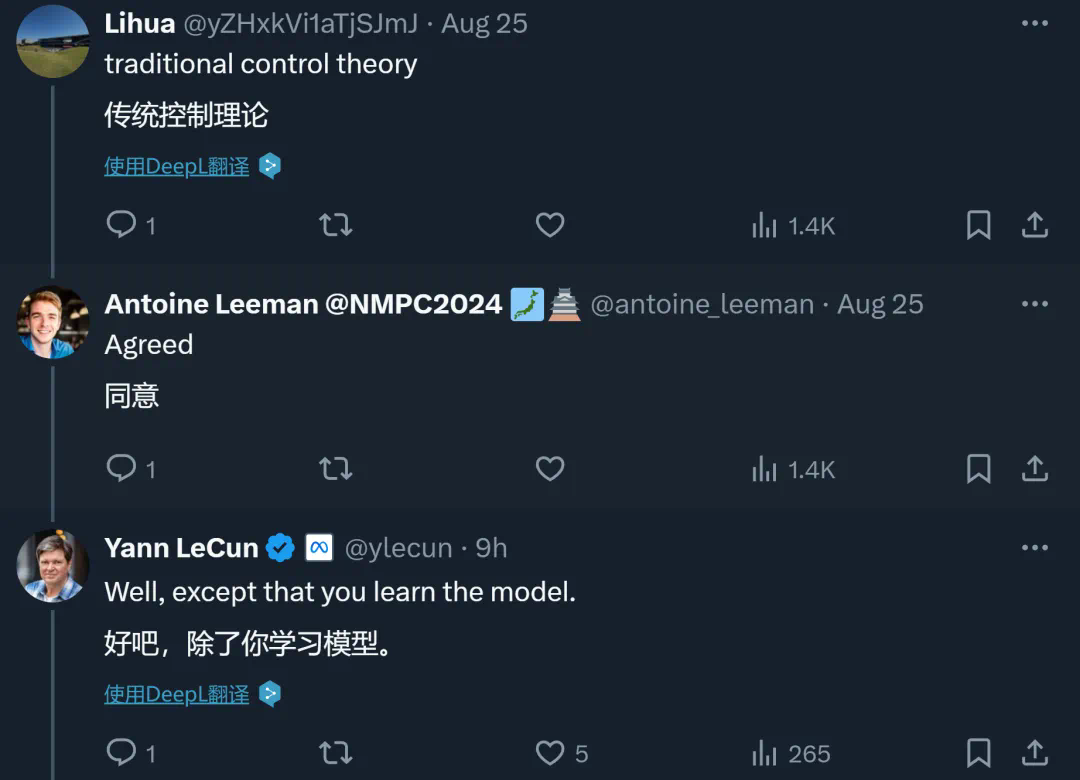
LeCun在其世界模型的研究中也采用了MPC的相关理论。
最近,LeCun对MPC的青睐再次引起了AI社区的关注。
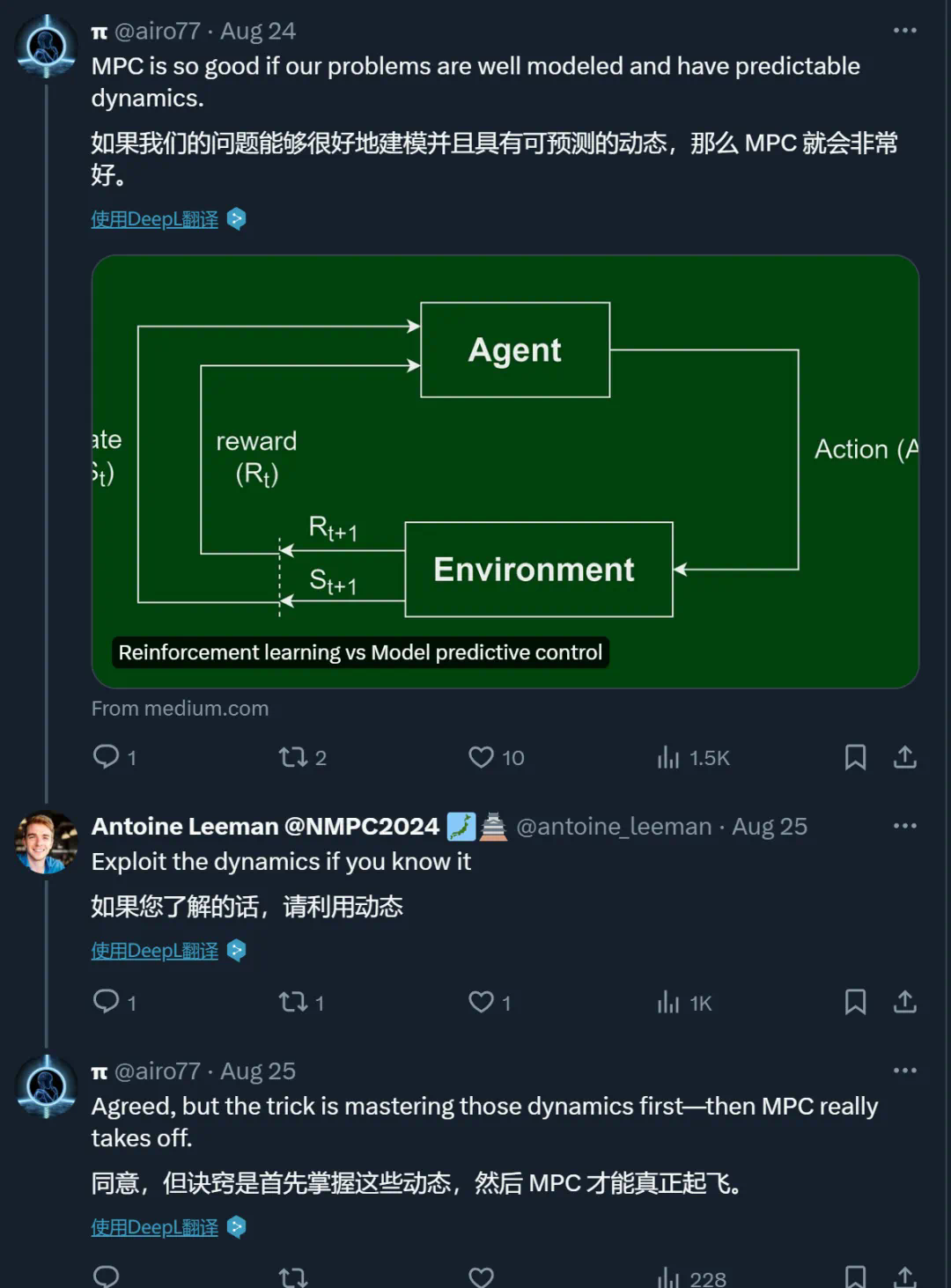
一些人认为,如果问题可以被很好地建模并且具备可预测的动力学特性,那么MPC就能发挥出色的效果。
对于计算机科学家而言,信号处理和控制领域仍有许多值得探索的内容。
然而,也有人指出,精确求解MPC模型是一个极具挑战性的问题,并且LeCun观点中的前提——“如果你有一个良好的世界模型”——本身就难以达成。
有人认为,强化学习与MPC之间不一定非此即彼,它们可能各自适用于不同的场景。
事实上,已经有一些研究尝试结合这两种方法,并取得了很好的成果。
强化学习与MPC对比
在此前的讨论中,有网友推荐了一篇Medium文章,详细分析比较了强化学习与MPC。
接下来,我们将依据这篇技术博客,具体探讨这两种方法的优缺点。
强化学习(RL)和模型预测控制(MPC)都是优化控制系统的关键技术。每种方法都有其独特的优势和局限性,选择最佳解决方案取决于特定问题的实际需求。
那么,这两种方法各自的优势、劣势是什么?它们又适合解决哪类问题呢?
强化学习
强化学习是一种依赖试错机制进行学习的机器学习方法,尤其适用于处理复杂动态系统或未知模型的问题。在此过程中,智能体通过与环境互动并采取行动来获得最大化的奖励信号。智能体依据观察到的状态做出行动,并根据行动的结果得到奖励或惩罚。经过一段时间的学习,智能体能逐渐掌握那些能带来更积极结果的行动方式。强化学习在控制理论中具有广泛应用,旨在为系统行为优化提供一种动态自适应的方法。具体应用实例包括:
-
自主系统:在如自动驾驶汽车、无人机及机器人等领域中采用强化学习来制定最佳控制策略,实现有效的导航与决策。
-
机器人技术:强化学习帮助机器人学习并改进其控制策略,在复杂的动态环境中完成诸如物体抓取、操作以及移动等任务。
强化学习(RL)的工作流程
智能体
- 学习者和决策者
环境
- 与智能体交互的环境或实体。智能体从中观察状态并采取行动,从而影响环境。
状态
- 对当前世界状态的完整描述。智能体可能完全或部分地观察这些状态。
奖励
- 反馈给智能体的一个标量值,用以指示其表现好坏。智能体的目标是最大化长期累积的奖励。奖励机制会促使智能体调整其策略。
动作空间
- 指在特定环境中智能体可执行的有效行动集合。如果动作数量有限,则称为离散动作空间;反之,如果动作数量无限,则称为连续动作空间。
模型预测控制 (MPC)
模型预测控制是一种广泛应用的控制策略,在过程控制、机器人技术、自主系统等多个领域都有所应用。
MPC 的核心理念在于利用系统的数学模型来预测未来的动态行为,并据此生成控制指令以优化特定的性能指标。
经过多年持续的改进与完善,模型预测控制 (MPC) 现已能够应对越来越复杂的系统及挑战性的控制难题。如以下示意图所示,在每个控制周期内,MPC 算法都会计算出控制时段内的开环序列,以此来优化预测时段内被控对象的行为。
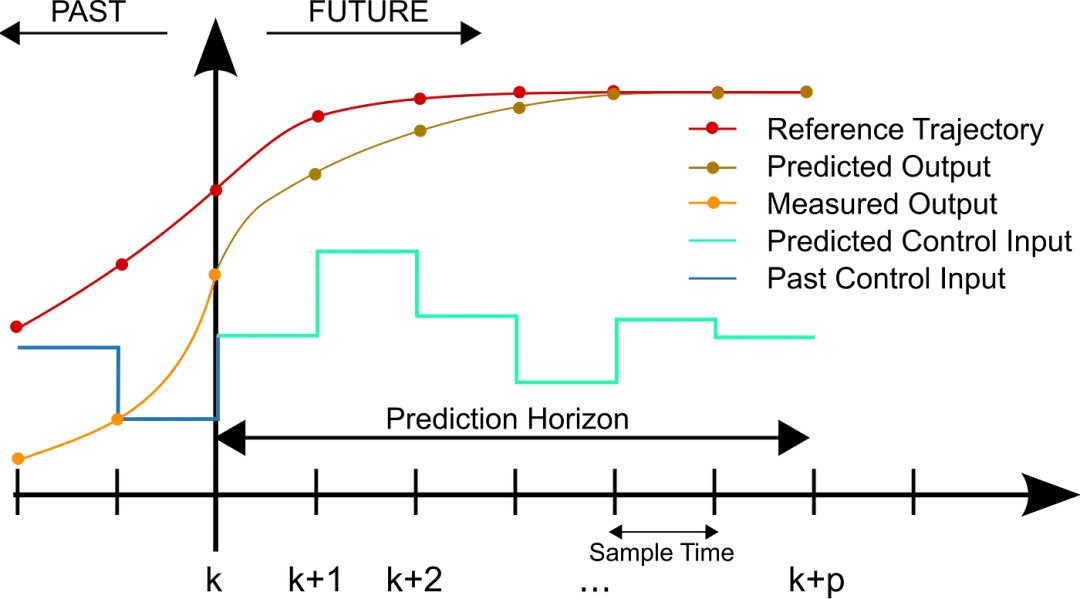
这是离散 MPC 的实施方案。
MPC 在控制系统中的应用领域包括:
- 过程工业
- 电力系统
- 汽车控制
- 机器人技术
特别是在机器人系统中,MPC 被用于规划和优化运动轨迹,确保机械臂和机器人平台能在制造和物流等应用场景中平滑高效地运行。
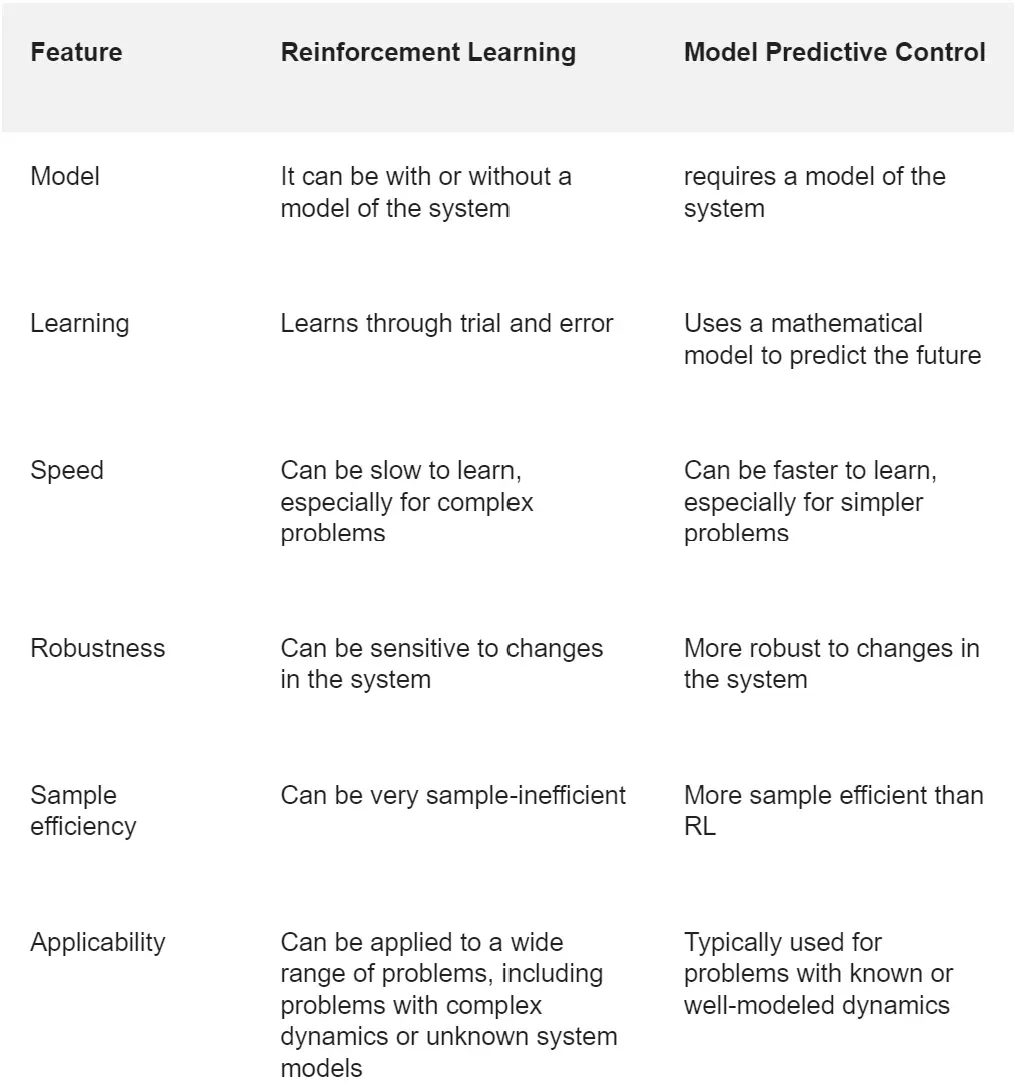
下表总结了强化学习与 MPC 在模型、学习方式、速度、稳健性、样本效率以及适用场景等方面的差异。通常来说,对于难以建模或者动态复杂的问题,强化学习是一个较好的选择。而对于那些模型建立清晰并且动态行为可预测的情况,MPC 则更为适合。
MPC 的最新进展之一是将其与机器学习技术相结合,形成所谓的 ML-MPC。ML-MPC 采取不同于传统 MPC 的方式来进行控制,利用机器学习算法对系统模型进行估计、预测,并生成控制动作。其核心思想在于利用数据驱动的模型来克服传统 MPC 的局限性。
基于机器学习的 MPC 能够实时适应不断变化的条件,这使得它非常适合于动态且难以预测的系统。与基于模型的传统 MPC 相比,基于机器学习的 MPC 能够提供更高的准确度,尤其是在复杂且难以建模的系统中。
此外,基于机器学习的 MPC 还能降低模型的复杂度,从而更加便于部署与维护。然而,与传统 MPC 相比,ML-MPC 也存在一些局限性,例如需要大量的数据来训练模型以及模型的可解释性较差等问题。
看来,要想真正将MPC引入人工智能领域,计算机科学家们仍有很长的路要走。参考链接:https://medium.com/@airob/reinforcement-learning-vs-model-predictive-control-f43f97a0be27