








RTX3090可以运行,360AI团队开源了最新的视频模型FancyVideo,连穿红衣的大叔都赞不绝口。
编辑日期:2024年08月26日
论文作者之一马奥,拥有中国科学院计算技术研究所硕士学位,在微软亚洲研究院视觉计算组及阿里通义实验室有过学术研究与算法实施的经历。目前担任奇虎360-AIGC团队中负责视频生成方向的主管,专注于视觉生成领域的研究及应用,并积极投身于开源社区的建设。
近期,开源社区迎来了一项强大的“视频生成”成果,它能够在消费级显卡(例如GeForce RTX 3090)上生成各种分辨率、比例、风格以及不同动态幅度的视频,其衍生模型还能实现视频扩展和回溯等功能。这项成果即是由360AI团队与中山大学共同研发的FancyVideo,一种基于UNet架构的视频生成模型。
以下是根据已开源的61帧模型的实际测试效果:
- 支持不同分辨率与比例的适应;
- 支持多种风格;
- 能够生成不同动态特性的视频。




论文链接:https://arxiv.org/abs/2408.08189
项目主页:https://fancyvideo.github.io/
代码仓库:https://github.com/360CVGroup/FancyVideo
论文标题:FancyVideo:通过跨帧文本引导实现动态且连贯的视频生成
摘要
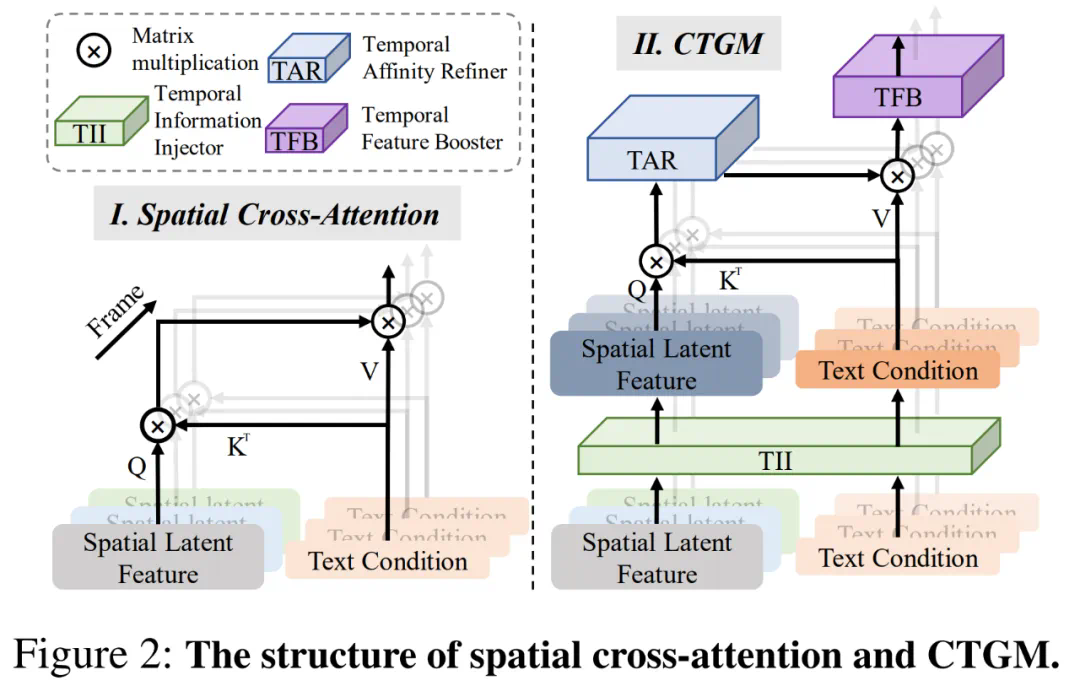
在视频生成的研究中,作者们注意到当前文本到视频(T2V)的方法普遍采用空间交叉注意力机制,这种方法简单地将文本信息应用于各帧的生成过程,而未能充分考虑不同帧间的差异性和灵活性(如左侧图所示)。这种处理方式导致模型难以准确捕捉提示词中的时间逻辑,并限制了其生成连贯动作视频的能力。
为了解决上述问题,FancyVideo 引入了一种新的跨帧文本引导模块(Cross-frame Textual Guidance Module, CTGM,如右侧图所示),以优化现有的文本控制机制。该模块包含以下三个关键子组件:
-
时序信息注入器 (Temporal Information Injector, TII):该组件负责将每帧特有的潜在特征信息融入文本条件中,从而形成跨帧的文本条件。
-
时序特征提取器 (Temporal Affinity Refiner, TAR):此部分沿着时间轴进一步精炼跨帧文本条件与潜在特征之间的关联性矩阵。
-
时序特征增强器 (Temporal Feature Booster, TFB):这个组件增强了潜在特征的时间一致性,确保生成视频的连贯性。
通过这三个子模块的协同作用,FancyVideo 能够更有效地利用文本信息指导视频生成过程,显著提升了生成视频的质量和连贯性。
图片说明
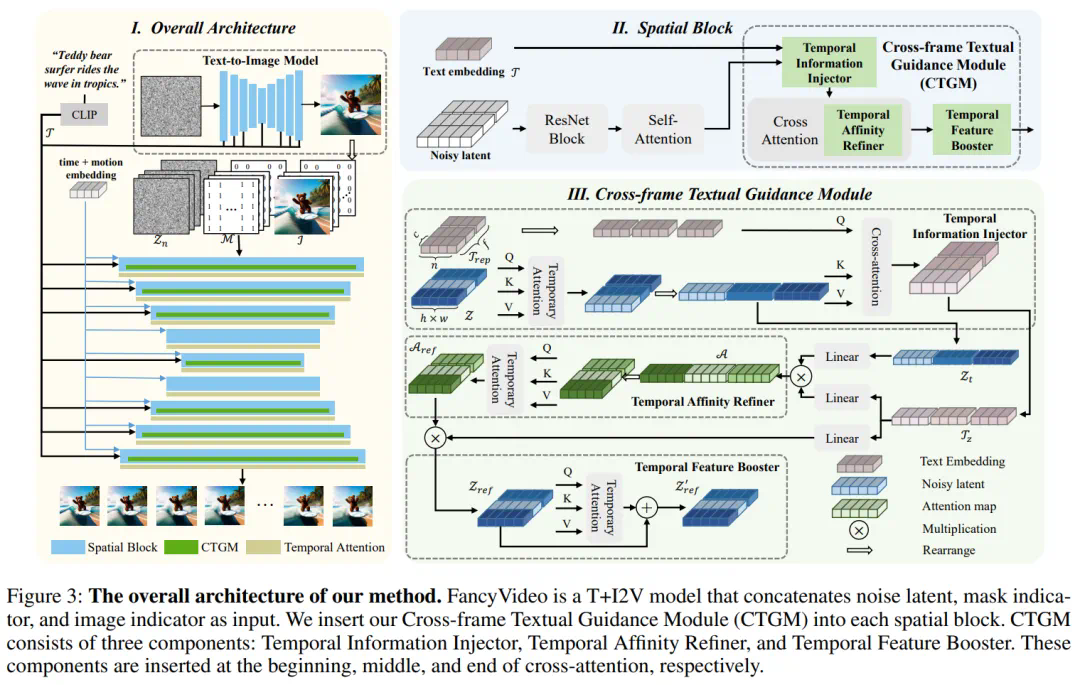
上图展示了 FancyVideo 的训练流程。
下面是 FancyVideo 的整体训练流程图。在模型架构上,FancyVideo 采用了在 2D T2I(文本到图像)模型的基础上插入时序层和基于 CTGM 的运动性模块来构建 T2V(文本到视频)模型的方法。在生成视频的过程中,先执行 T2I 操作生成第一帧,然后继续完成 I2V(图像到视频)的过程。这种方法不仅保留了 T2I 模型的优势,确保了视频的整体画质较高,而且还大幅度降低了训练成本。为了实现对运动性的控制,FancyVideo 在训练阶段将基于 RAFT 技术提取的视频运动信息以及时间嵌入一同输入到网络中。
实验结果
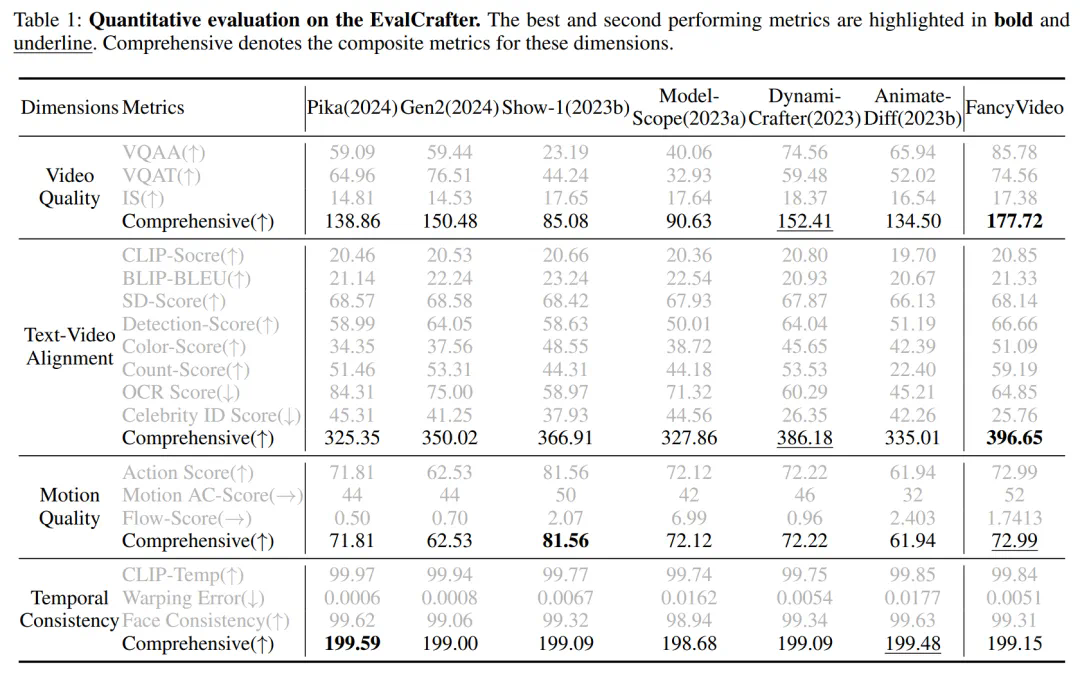
作者从定量与定性两个维度评估了模型的表现。首先,他们在 EvalCrafter Benchmark 上对比了 FancyVideo 与其他 T2V 模型,结果表明 FancyVideo 在视频生成质量、文本一致性、运动性及时序一致性等方面均表现出色。
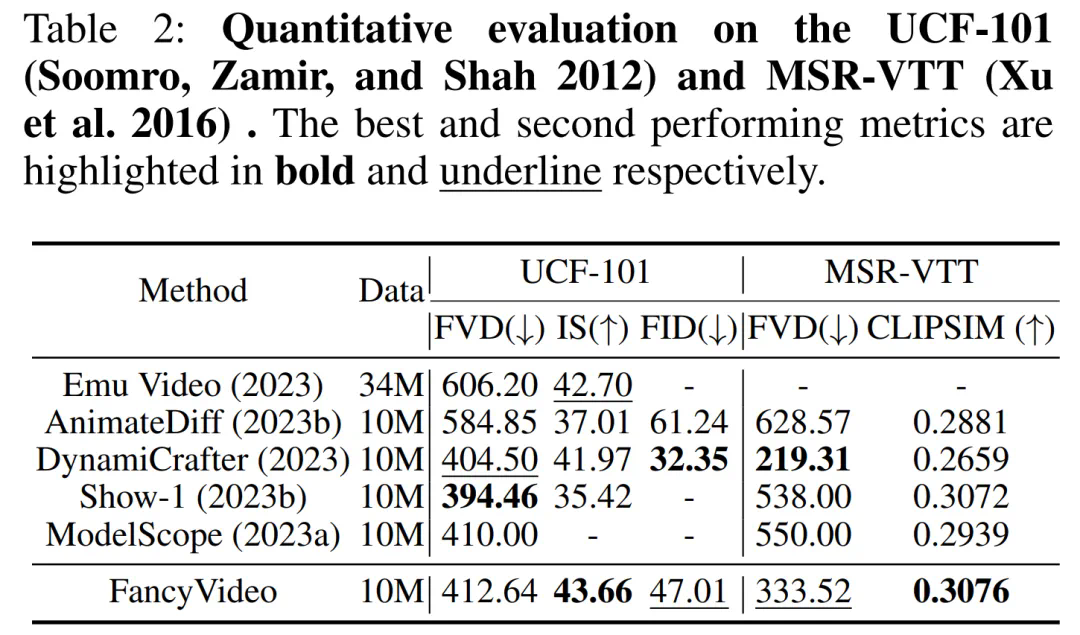
此外,该研究还在 UCF-101 和 MSR-VTT Benchmark 上进行了零样本测试。在衡量视频丰富度的 IS 指标及文本一致性的 CLIPSIM 指标方面,FancyVideo 取得了最先进的结果。
同时,研究还根据 FancyVideo 模型的 T2V 和 I2V 能力进行了人工评估,结果显示 FancyVideo 在视频生成质量、文本一致性、运动性及时序一致性等方面均领先于先前的方法。
最后,论文通过消融实验探讨了CTGM的不同子模块对视频生成结果的影响,以此来验证每个子模块的合理性和有效性。
基于这样的训练流程与策略,FancyVideo不仅能实现T2V(文本到视频)和I2V(图像到视频)功能,还能在此基础上执行关键帧插入操作:
此外,FancyVideo在开源社区上线不到一周的时间里,热心的用户已经自行开发了FancyVideo的ComfyUI插件,使得大家能够在自己的设备上畅享乐趣:
不仅如此,据作者了解,FancyVideo团队计划不仅将推出更长且效果更佳的模型版本供开源社区使用,还打算发布一个网页版应用,让所有人可以免费体验。在这个AIGC(人工智能生成内容)的时代里,每个人都能成为一位“能诗会画”的艺术家。
总结而言,相较于SORA等视频生成产品的进展,开源社区中的视频生成模型更新迭代速度稍显缓慢,而FancyVideo的出现为普通用户提供了更多可能性。我们有理由相信,在社区成员的共同努力下,视频生成这项目前看来耗时耗力的工作,未来将成为更多普通人日常生活中不可或缺的一部分。


















