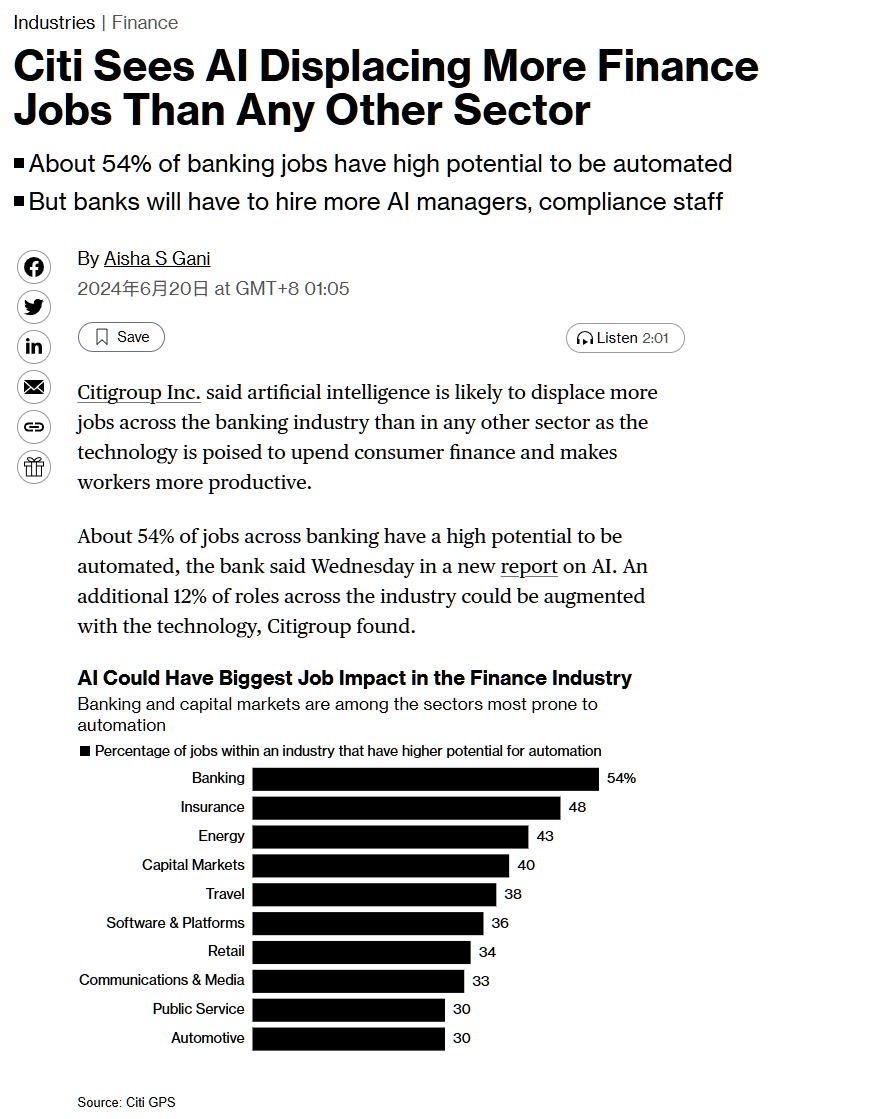
真香!智谱大模型现在提供了首个免费的API。
编辑日期:2024年08月27日
大模型API,正式迈入Flash时代
近段时间,国内外的大模型行业掀起了一股“快速版”热潮。
5月的谷歌I/O大会上,新推出的Gemini 1.5大模型系列中加入了Flash版本,主打轻量化和快速响应。到了7月,OpenAI基于GPT-4推出了Mini版本,宣称其性能超越最先进的小型模型,且成本更低。
如今,如果你访问ChatGPT,会发现原来的默认模型GPT-3.5已被替换为GPT-4 Mini。自2022年底以来一直使用的GPT-3.5终于退出历史舞台,让人感叹AI技术的进步之迅速。
这一轮技术迭代背后的核心在于直接面向应用的底层逻辑。新一代大语言模型不仅保持了多模态和长上下文处理的优势,还因速度和效率的显著提升赢得了更多开发者的青睐。
在实际应用场景中,新模型特别适合处理高频次且相对简单的任务,能够承受频繁调用。现在,开发一款基于生成式AI技术的产品变得更加容易。
最近,国内大模型平台市场占有率领先的智谱也宣布推出新模型,并提供了一系列提高AI开发效率的工具。
大模型开发更加便捷
智谱此前已经上线了一键微调工具,此次更是决定将GLM-4-Flash免费开放。
智谱最新的大模型GLM-4-Flash于6月发布,其API价格低至每100万token只需0.1元,吸引了众多开发者使用。无论在国内还是国外,许多人在社交网络上分享了自己的使用体验。
这款大模型API的实际表现如何呢?我们也亲自试用了一下。
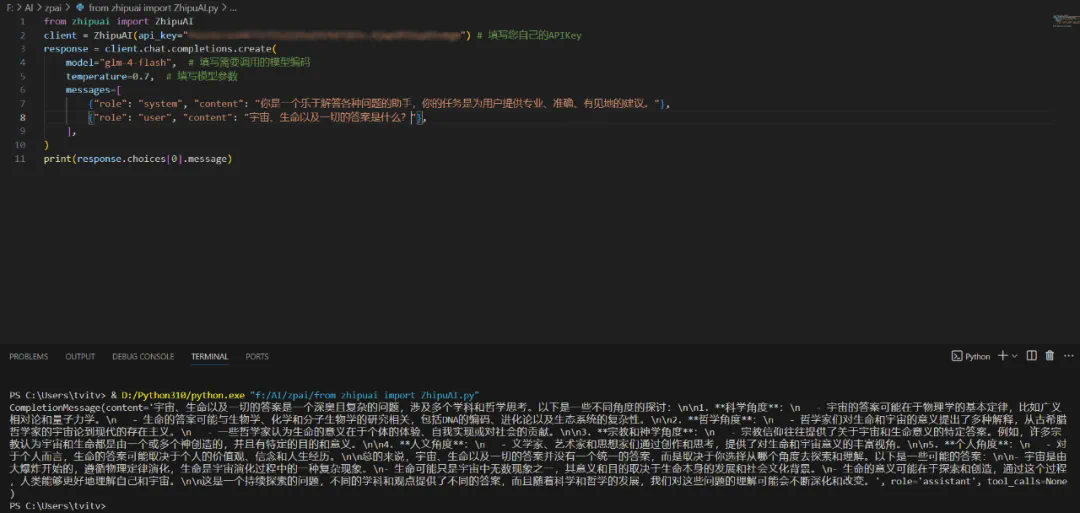
首先,若要体验和调用大型模型的能力,最简便的方式是通过Python脚本来实现。智谱在其官方网站上提供了几个示例脚本,只需要替换里面的api key为你自己的,并根据需要调整内容,便能轻松使用这个大型模型,例如,在VS Code中进行操作。如下图所示:
此外,你还可以将这一模型集成到任何支持API接入的应用程序中。例如,可以将它引入笔记软件Obsidian。具体来说,可以通过安装并启用BMO Chatbot插件来实现这一点。在插件的设置选项中,找到“API Connections”下的OpenAI部分。之所以选择OpenAI,是因为GLM-4-Flash的API协议与OpenAI的几乎相同。
接下来,在“OpenAI-Based URL”中输入智谱模型的链接:https://open.bigmodel.cn/api/paas/v4/,同时在“OpenAI API Key”处输入你的api key。为了能够使用GLM-4-Flash模型,还需编辑该插件的data.json文件,把“glm-4-flash”添加到“openAIBaseModels”列表中。
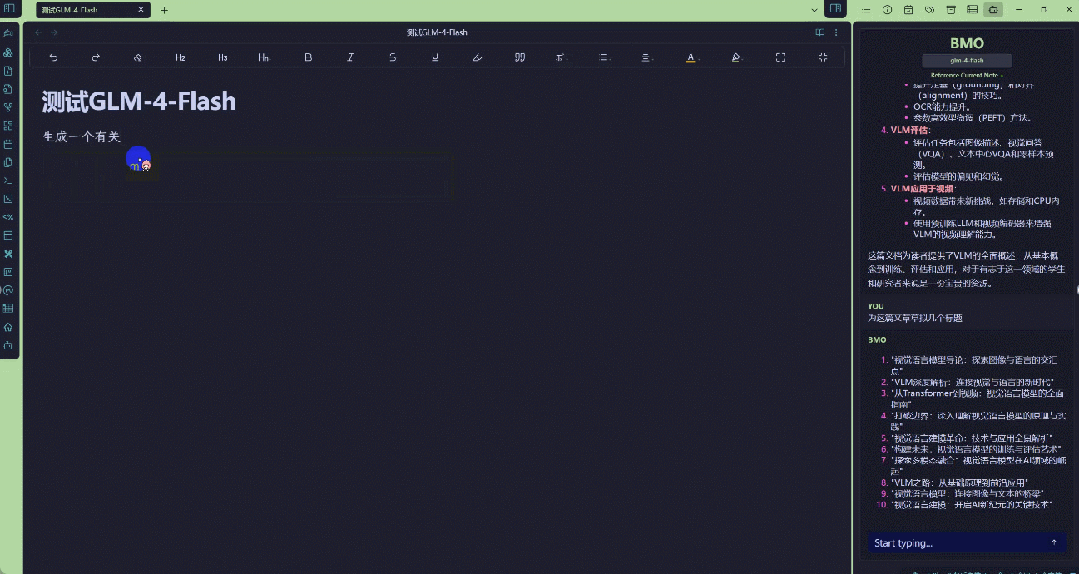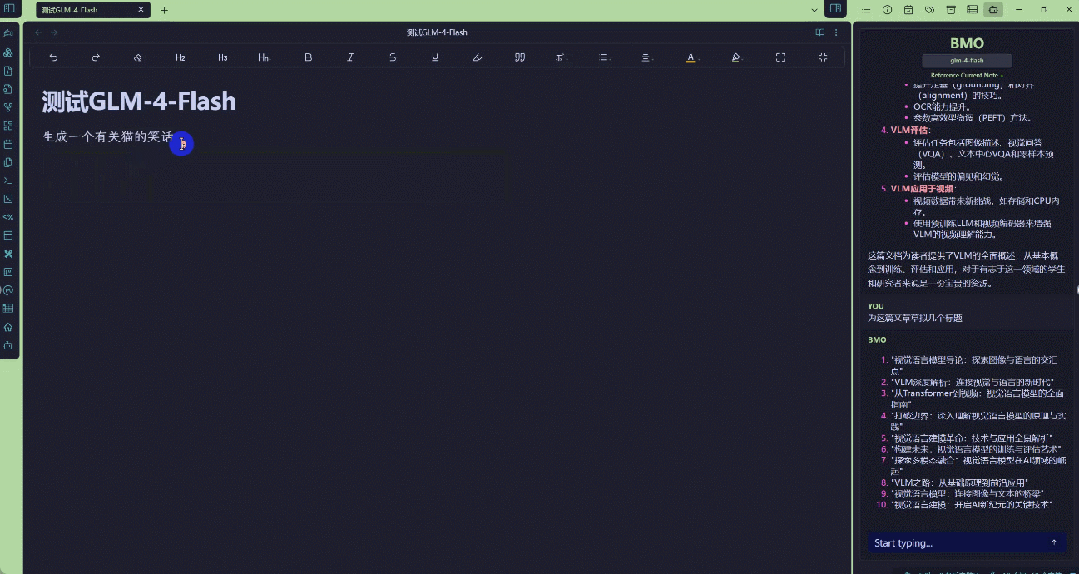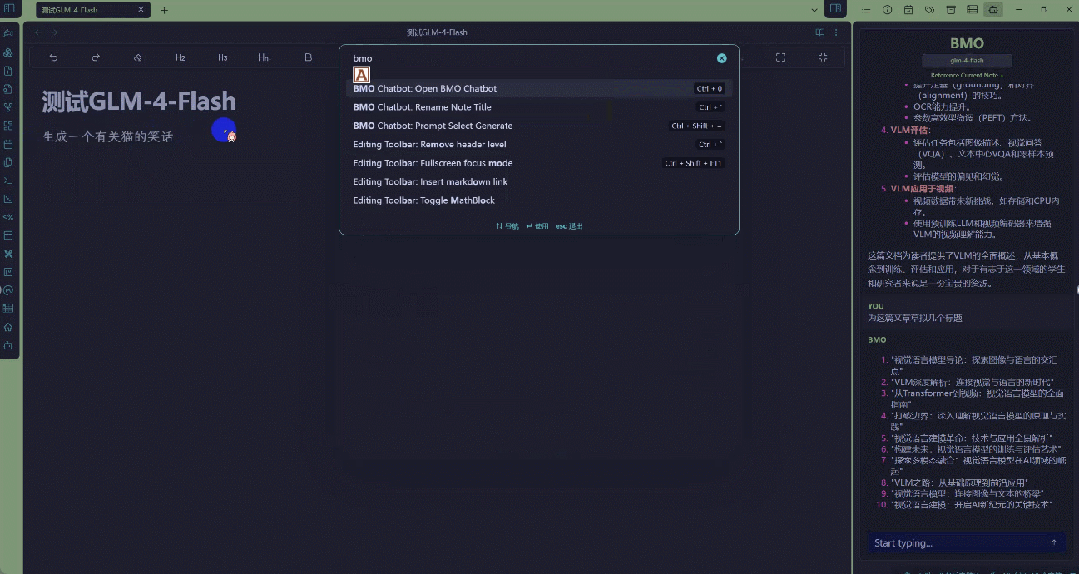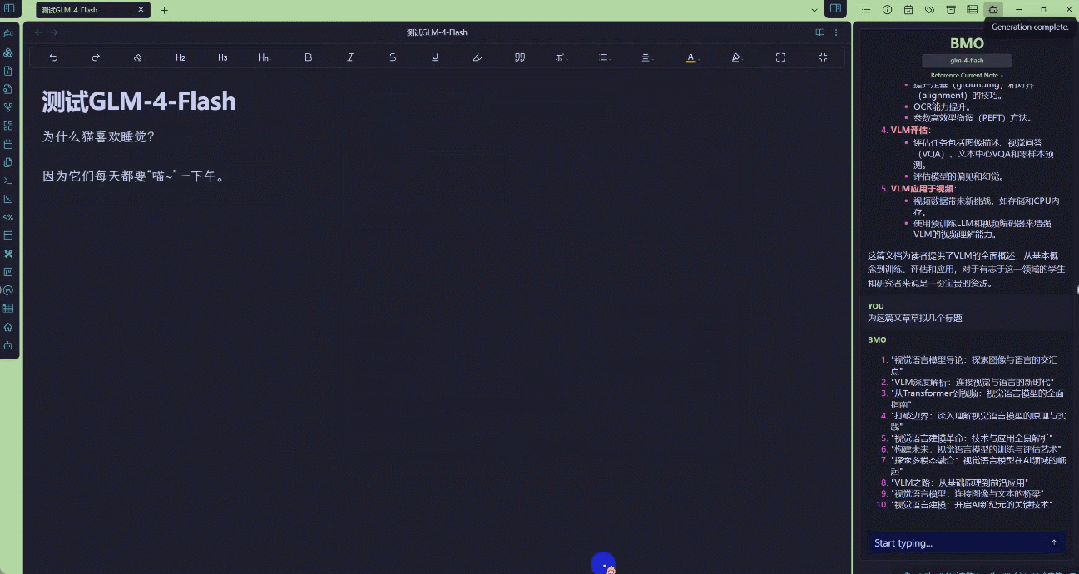
这样一来,你就可以在笔记工作中利用GLM-4-Flash了。下图展示了一个应用实例,其中GLM-4-Flash被用来分析一篇关于视觉语言模型的文章,并提出了几个可能的标题。

当然,你也可以直接利用GLM-4-Flash生成文本笔记。
 效果看起来都非常出色。
效果看起来都非常出色。
提到大模型微调,上周二,OpenAI 正式推出了大模型微调功能,引起了AI领域的广泛关注。
OpenAI 的初衷是帮助开发者以较低成本构建个性化应用。此次智谱发布的大模型微调功能,使我们能够利用微调工具,结合自身独特的场景数据,对平台提供的基础模型进行微调,迅速实现定制化。这种方式不仅贴合具体业务场景,而且无需复杂的调整或重新训练。
如果基础模型难以满足复杂任务的需求,微调功能将能显著提升效果。它可以使大模型展现出特定风格,或增强输出的可靠性,从而更好地应对复杂任务。
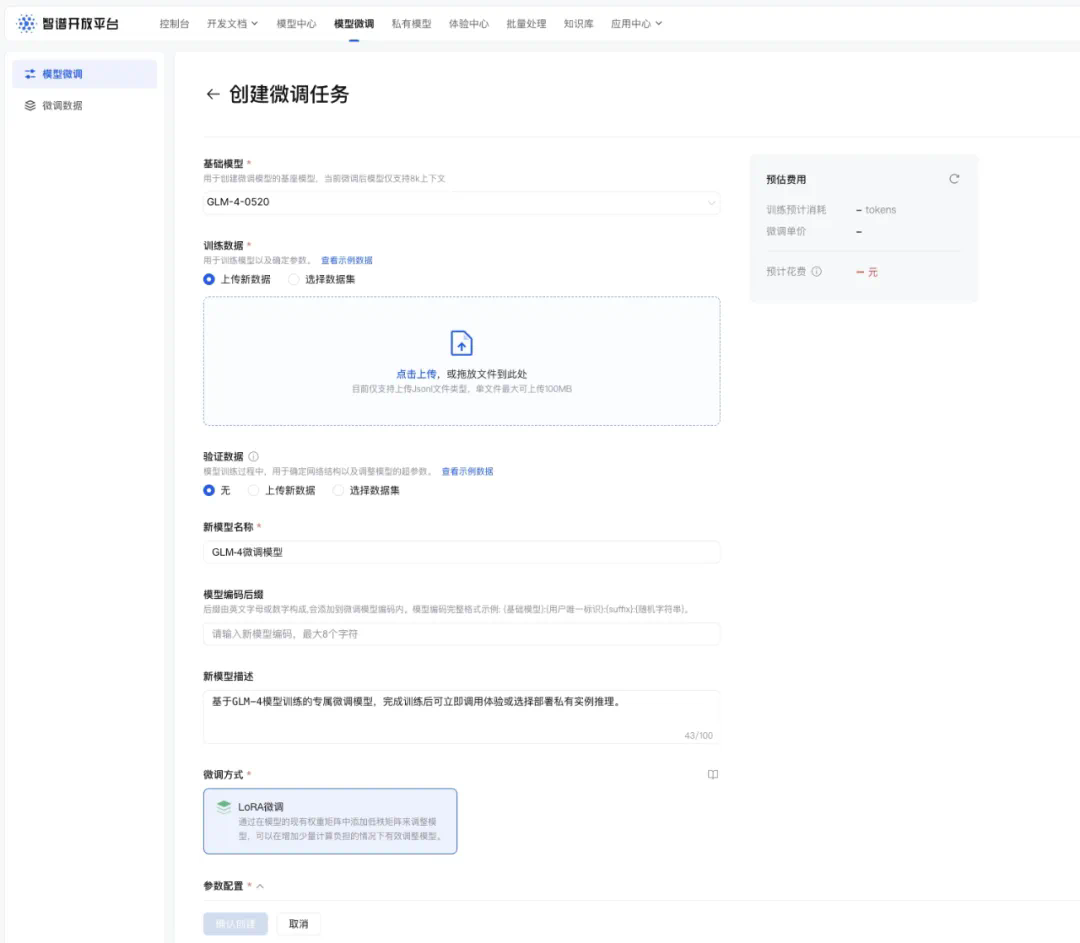
目前,智谱已开放了包括GLM-4-Flash、GLM-4-9B在内的多个模型的LoRA微调与全参数微调功能。在微调过程中,用户需准备并上传训练数据来优化大模型,并对结果进行部署与评估,最终完成的模型可迅速投入使用。
可以看出,当前各大模型公司推出的产品越来越贴近实际需求。这些为开发者考虑周到且实用的工具,对于AI技术的大规模应用具有重要意义。
那么,“Flash”大模型意味着什么呢?
智谱提供的一系列新功能,背后都基于其核心——GLM-4-Flash大模型的支持。
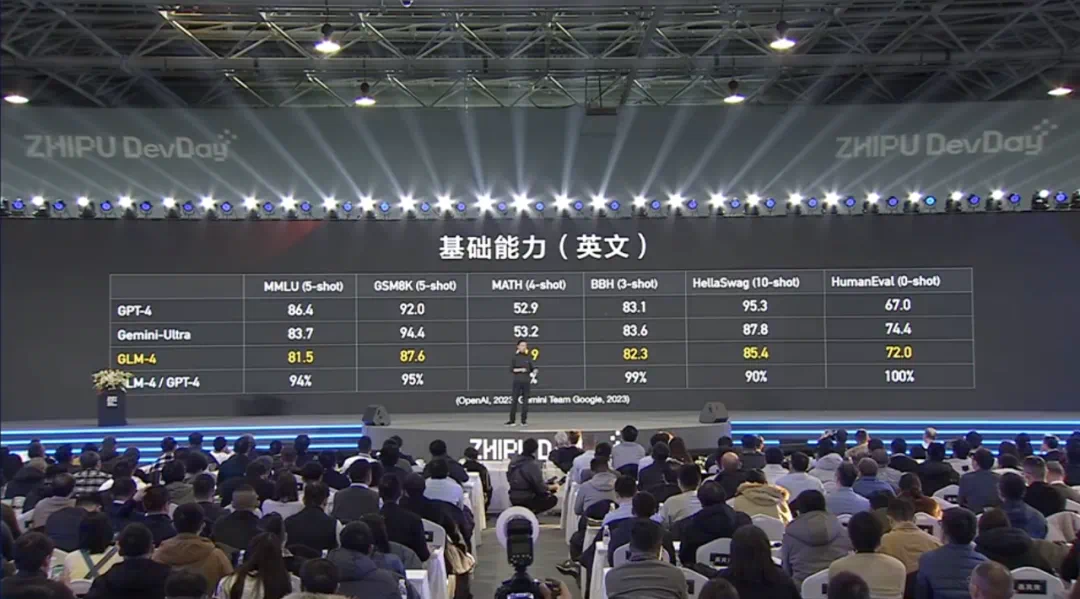
GLM-4 大模型是智谱在今年 1 月发布的新一代基础大模型,在多项指标上接近甚至达到了标杆模型 GPT-4 的水平。同时,GLM-4 在长上下文支持、多模态能力、推理速度以及并发请求方面都有显著提升,大幅降低了推理成本。
在此基础上发展的 GLM-4-Flash 拥有一系列技术优势:
- 数据预训练:引入大规模语言模型参与数据筛选,并使用 10T 的高质量多语言数据进行训练。
- 预训练技术:采用 FP8 技术实现高效预训练,显著提升了训练效率和计算能力。
- 模型能力:GLM-4-FLASH 具备强大的推理性能,支持 128K 长上下文推理及多语言处理。
- 生成速度:输出速度高达 72.14 token/s,相当于每秒 115 个字符。
GLM-4-Flash 模型实测
GLM-4-Flash 在大量测试中展示了其卓越的能力:
- 模型界面:支持多轮对话、自定义系统指令构建(如设定模型身份、任务目标),并提供网页搜索、知识库搜索及函数调用等功能。
- 用户调整:用户可以自由调整对话窗口的最大 tokens 数量(输入上下文长度)、模型温度(控制生成内容的随机性和创造性)及 top_p(控制回答风格,确保输出结果的正确性与多样性)。
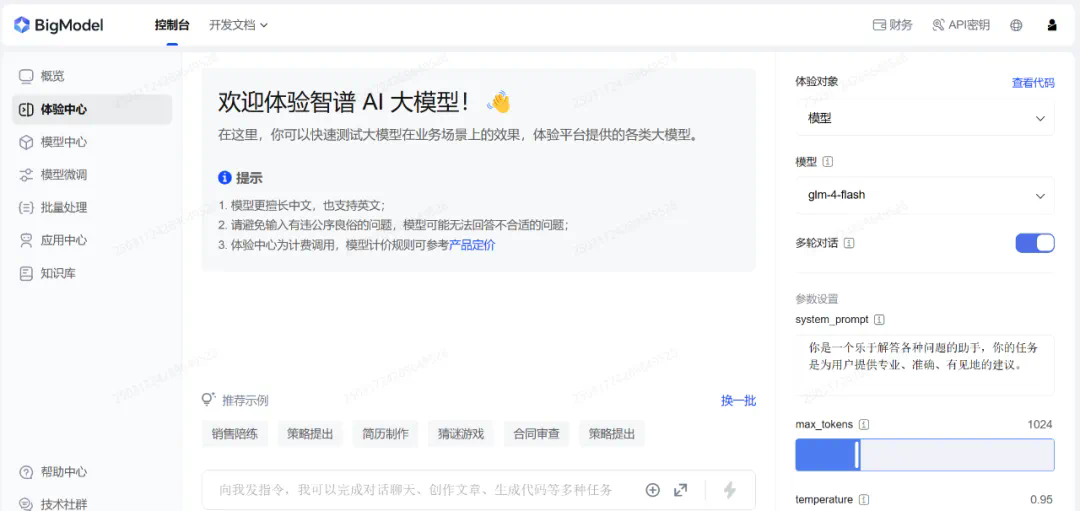
体验地址:https://open.bigmodel.cn/
该模型还具备从简单到复杂的逻辑推理能力,涵盖了一般逻辑推理和数学推理。
测试 1:首先来看一个最近难倒了许多大型模型的问题:“9.11 和 9.9 哪个更大?” GLM-4-Flash 很轻松地答对了。

类似的数字比较问题,GLM-4-Flash 也回答正确。从解题思路来看,GLM-4-Flash 掌握了正确的小数比较方法。

而当前版本的 GPT-4o 却全都出错了。


测试 2:此前研究机构 LAION 发现,GPT-3.5/4、Llama、Gemini、Claude 和 Mistral 等大型模型在回答“爱丽丝(女性)有 N 个兄弟,M 个姐妹,那么爱丽丝的兄弟有多少个姐妹?”这个问题时,正确率很低。
我们让 GLM-4-Flash 尝试回答,结果是正确的。

改变主角的性别和亲属关系后,GLM-4-Flash 依然能够正确理解并给出正确答案。
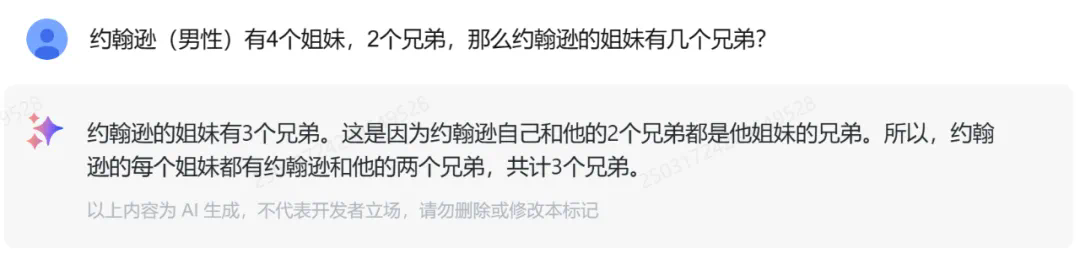
测试 3:在多人真假话判断问题上,GLM-4-Flash 能够理清各种假设情况,并最终给出正确答案。
真香!智谱大模型现在提供了首个免费的API
对比之下,GPT-4o 回答错误。

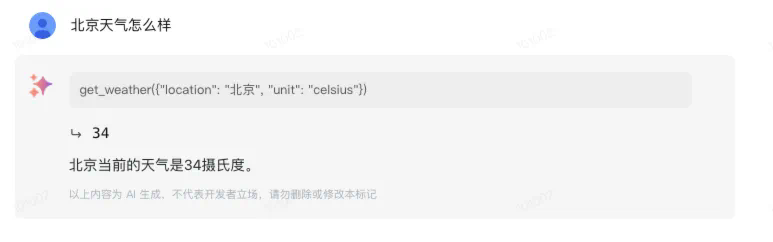
智谱大模型 GLM-4-Flash 现在支持函数调用功能,允许调用外部函数或服务。

此外,还具备网页检索功能,可以实时获取互联网上的最新信息。
例如,2024 年巴黎奥运会中国体育代表团获得的金银铜牌总数,结果准确无误。
除此之外,GLM-4-Flash 还具备代码生成、视频脚本制作、角色扮演、文章扩写等一系列功能,据说效果都非常不错。
通用化 AI 的应用已经开始普及。
目前,GLM-4-Flash 已经上线两个月,许多用户展示了不同的应用场景,或许能为我们带来一些启示。具体介绍如下:
-
生物科学领域:有生物学博士正在利用 GLM-4-Flash 处理复杂的分子数据,显著提高了科研工作中数据处理的效率。通过 AI+Science 的结合,可以深入探索基因序列与人类健康之间的关系。
-
科研数据生成:一些年轻的科研人员正在使用 Flash 模型生成高质量的数据材料。这些数据不仅可用于自身的研究,还可以用于训练其他领域的大模型。
-
翻译应用:有独立开发者发现 Flash 模型可用于高效翻译,并开发了一款中英文翻译 APP。这款 APP 不仅提供翻译功能,还包含互动学习模块,使得儿童可以在轻松愉快的环境中学习英语。该 APP 已经帮助了大量学习者。
广告公司也发现了Flash模型在内容创作方面的巨大潜力。他们开发了应用程序来润色文章,以帮助编辑和撰稿人提高工作效率。AI大模型能够连接网络获取最新信息,并提供创意灵感,确保文案的质量与一致性。看来,在速度更快、性能更强大的GLM-4-Flash版本上,一些需要快速响应的简单垂直应用已经得到了充分验证。
然而,对于通用的大模型而言,仍有许多功能等待人们去发掘。
8月27日,智谱BigModel开放平台正式宣布:GLM-4-Flash完全免费,并且开启了限时免费微调活动。
GLM-4-Flash是智谱首次开放免费API的大模型,支持长达128K的上下文。在用户调用量方面,智谱保持了原有用户的并发量不变,新用户则有两个并发量,并可申请进一步增加。
至于GLM-4-Flash微调赠送额度,如果立即申请,您将获得500万token(3个月)的训练资源包,名额限2000位,先到先得。此外,智谱还将开放GLM-4-Flash模型的微调权重下载,不久之后,人们将可以自由选择部署平台。
这一系列举措展示了国内大模型公司在应用层面的独特优势。在大模型技术达到国际先进水平的同时,国内AI领域的先锋队已经磨练好了“内功”,通过系统优化大幅提升推理效率。
如今,免费开放的大模型已经惠及众多开发者,让他们无需花费一分钱即可上线基于大模型的智能应用。
不管怎样,是时候体验一下大模型的开发了,快来参与吧!
点击此链接,立即开始使用。