分子大模型升级:Uni-Mol+加速量子化学属性预测,深势科技与北京大学研究登上《自然》子刊
编辑日期:2024年08月27日

编辑 | KX
深势科技于2022年发布了Uni-Mol,这是一款基于分子三维结构的通用大模型。由于其卓越的性能和强大的泛化能力,Uni-Mol在小分子性质预测、蛋白质靶点预测、量子化学性质预测以及MOF材料吸附性能预测等多个任务中均表现出色,超越了现有解决方案。
今年3月,深势科技与清华大学合作,推出了基于Uni-Mol的专用模型Uni-MOF,该模型能够预测不同条件下纳米多孔材料对各种气体的吸附性能,预测精度高达0.98。
近日,深势科技与北京大学合作,发布了新一代模型Uni-Mol+。经过迭代升级,Uni-Mol+具备了更大的参数量和更多的预训练数据,展现了更强的通用性。
Uni-Mol+是一种利用3D构象进行精确量子化学属性预测的深度学习方法。基准测试结果显示,Uni-Mol+显著提升了各种数据集中QC属性预测的准确性。
相关研究成果以“Data-driven quantum chemical property prediction leveraging 3D conformations with Uni-Mol+”为题,于8月19日发表在《Nature Communications》上。
量子化学(QC)性质预测对于计算材料和药物设计至关重要,但传统方法依赖于昂贵的电子结构计算,例如密度泛函理论(DFT)。深度学习方法通常使用1D SMILES或2D图作为输入来加速这一过程,但在精度方面难以达到高水平,因为大多数QC性质都依赖于精细的3D分子平衡构象。
为了解决这一挑战,深势科技开发了一种名为 Uni-Mol+ 的新方法。通过精心设计的模型架构和训练策略,Uni-Mol+ 在各项基准测试中展现了卓越的表现。
主要的研究贡献可归纳如下:
对于任意分子,Uni-Mol+ 首先利用低成本的方法(如来自 RDKit 和 OpenBabel 的基于模板的方法)获取初步的 3D 构象。接着,通过迭代更新初始构象的过程来学习目标构象,即经 DFT 优化后的平衡构象。在最后一步中,根据所学得的构象预测量子化学属性。
为了高效地学习这一构象更新过程,研究人员提出了一种双轨 Transformer 模型架构和一种创新的训练方法。
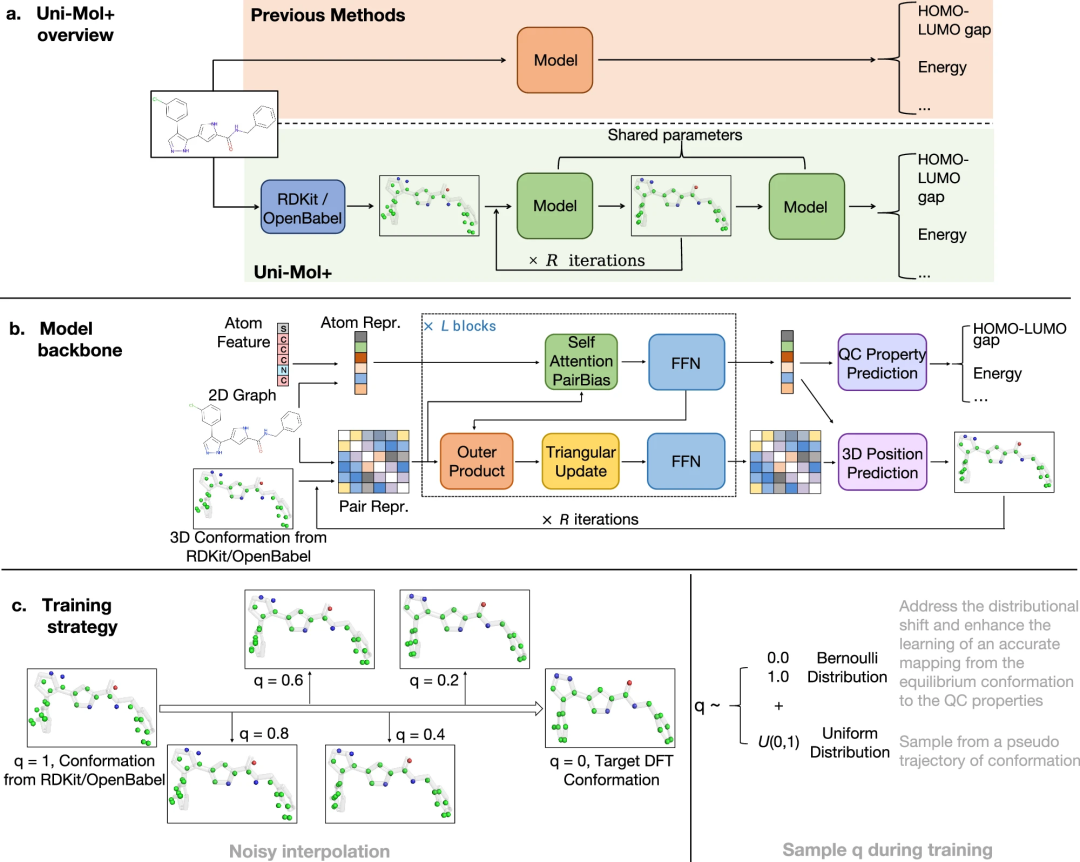
Uni-Mol+ 的模型架构是一种双轨 Transformer,包括一个原子表示轨道和一个对表示轨道。
相较于之前的 Uni-Mol 使用的 Transformer 架构,Uni-Mol+ 进行了以下两项重要改进:
-
通过原子表示的外积(称为 OuterProduct)增强对表示,实现原子到对的信息传递,并使用三角算子(称为 TriangularUpdate)来增强 3D 几何信息。这两种算子已在 AlphaFold2 中得到验证并证明其有效性。
-
采用迭代过程不断更新 3D 坐标以达到平衡构象。用 R 表示构象优化的轮次。
为了学习构象更新过程,研究人员提出了一种新颖的训练策略。从 RDKit 生成的初始构象和 DFT 平衡构象之间的轨迹中采样构象,并将这些采样得到的构象作为输入来预测平衡构象。需要注意的是,在许多数据集中,实际的轨迹通常是未知的;因此,研究人员采用了一个假设两个构象之间存在线性过程的伪轨迹。
此外,还设计了一种采样策略,用于从伪轨迹中提取构象,作为模型在训练期间的输入。该策略结合了伯努利分布和均匀分布。伯努利分布解决了两个问题:(1) 训练与推理之间的分布差异;(2) 加强了从平衡构象到量子化学属性之间精确映射的学习。同时,均匀分布生成额外的中间状态作为模型输入,有效增强了输入构象的多样性。研究人员在两个大规模数据集基准 PCQM4MV2 和 Open Catalyst 2020 (OC20) 上评估了 Uni-Mol+ 的性能。
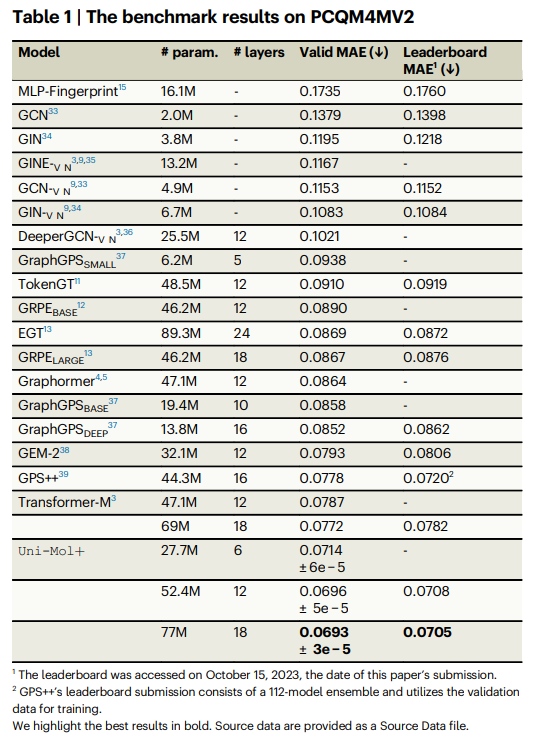
首先,将之前提交给 PCQM4MV2 排行榜的模型作为基准。除了默认的 12 层模型外,研究人员还评估了 Uni-Mol+ 的两个变体,分别为 6 层和 18 层,以探究当模型参数大小变化时,其性能如何变化。
结果如下:
- Uni-Mol+ 在单模型性能验证数据上的表现比之前的 SOTA 高出 0.0079,相对提升了 11.4%。
- Uni-Mol+ 的所有三种变体均显示出显著的性能提升。
- 尽管 6 层的 Uni-Mol+ 模型参数较少,但其性能仍优于所有之前的基线。
- 将层数从 6 层增加到 12 层可以显著提高准确度,并以较大优势超越所有基线。
- 18 层的 Uni-Mol+ 表现出最高性能,以显著优势超越所有基线。这些发现强调了 Uni-Mol+ 的有效性。
- 单个 18 层的 Uni-Mol+ 模型在排行榜(测试开发集)上的表现尤其值得关注,因为它超越了之前最先进的方法,而无需使用集成或其他技术。相比之下,之前最先进的 GPS++ 依赖于 112 个模型的集成,并且包含验证集进行训练。
Open Catalyst 2020 (OC20) 数据集专门用于推动催化剂发现和优化的机器学习模型开发。在这项研究中,重点考察了初始结构到松弛能量(IS2RE)任务。
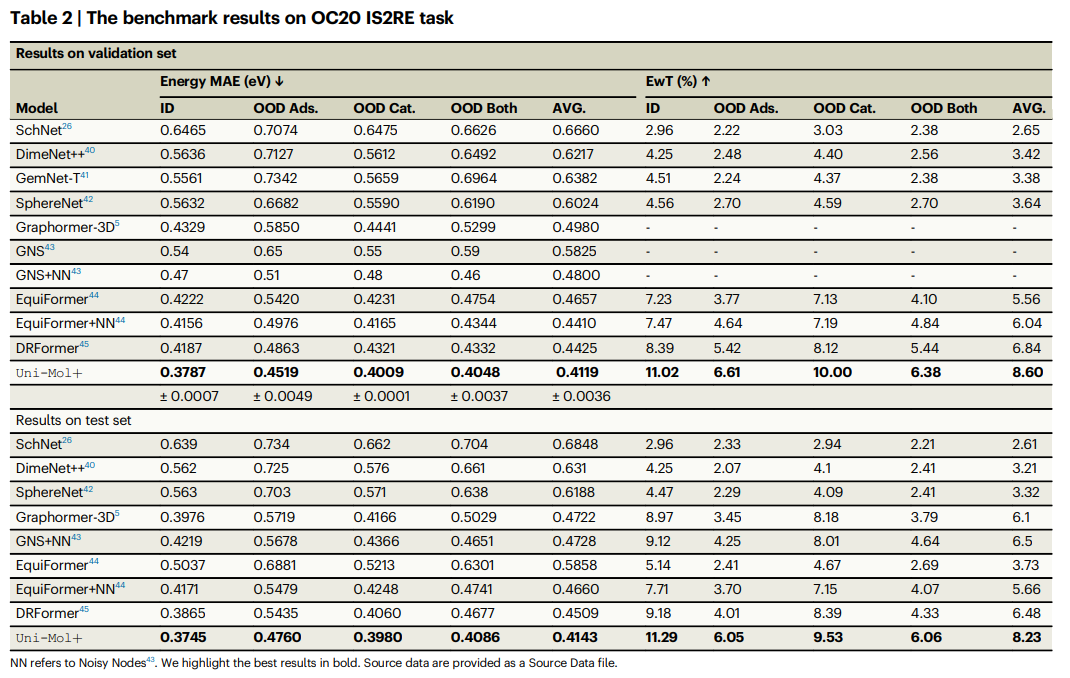
研究人员对 OC20 IS2RE 验证和测试集上的多种模型进行了性能比较,如表 2 所示。从表中可以看出,Uni-Mol+ 在平均绝对误差 (MAE) 和阈值内能量 (EwT) 方面均显著优于所有先前的基线模型。这证明了 Uni-Mol+ 的卓越性能。研究结果强调了 Uni-Mol+ 在捕捉材料系统中复杂相互作用的有效性,及其在各类计算材料科学任务中的广泛应用潜力。
研究人员还对 Uni-Mol+ 进行了全面的消融研究。在 PCQM4Mv2 数据集上,采用了默认的 12 层 Uni-Mol+ 配置。研究结果总结在表 3 中,其中 No.1 是默认设置,No.2–7 重点检查模型主干,No.8–17 重点检查训练策略。
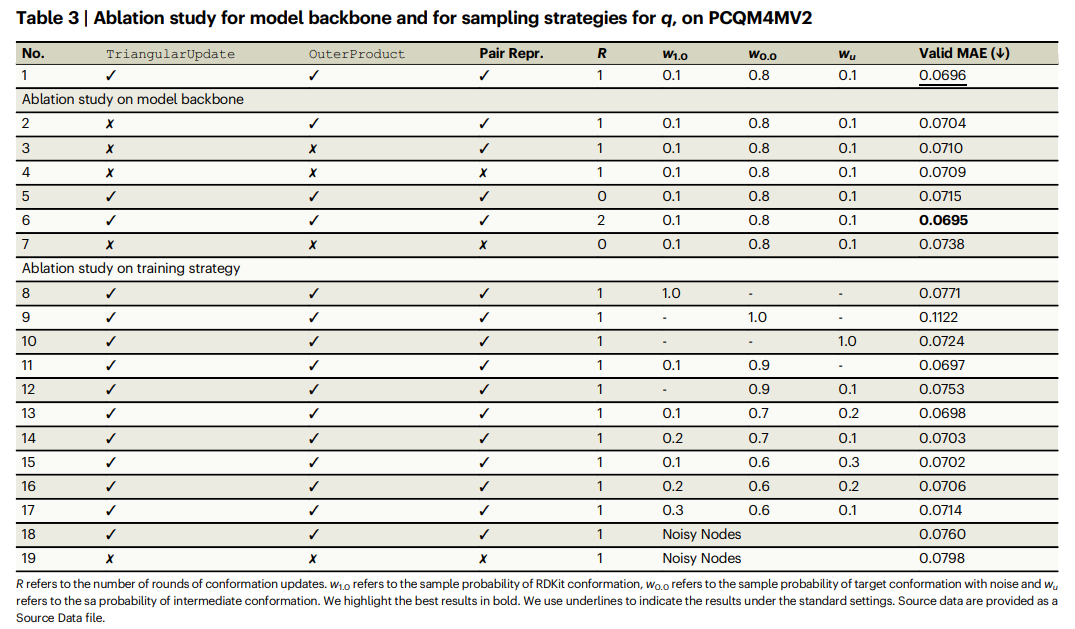
研究结果如下:
(1)比较 No.8、No.9 和 No.10,发现仅从一种构象中采样效果不佳。
(2)通过比较 No.8、No.9 和 No.11,可以推断出从 RDKit 和目标构象的混合中采样会产生令人满意的结果(有效 MAE 为 0.0697)。然而,如果仅从目标和中间构象(No.12)采样,则结果并不理想(有效 MAE 为 0.0753)。这一结果表明,从 w1.0 中采样是必要的,因为它减少了训练和推理之间的分布偏移。
(3)从三种构象类型中采样的默认策略(No. 1)表现最佳。 (4)调整混合分布中的权重(No. 13-17)并未能超越默认策略的表现。并且,随着 w0.0 的减小,性能有所下降。这表明默认的加权方案适用于此任务。
(5)通过比较 No. 18 和 No. 1 的结果,可以看出 Noisy Nodes(No. 18,有效 MAE 为 0.0760)的性能明显不如 Uni-Mol+(No. 1,有效 MAE 为 0.0696)。这种显著的性能差异(0.0760 vs. 0.0696)表明所提出的训练策略比之前的策略更为高效。
(6)对比 No. 19 和 No. 18 的结果,可以看到,在使用噪声节点策略时,之前研究中采用的模型结构效果不如使用 Uni-Mol+ 主干结构的结果。这一发现进一步证实了 Uni-Mol+ 的主干结构优于之前提出的模型架构。
综上所述,消融研究验证了 Uni-Mol+ 中默认采样策略的有效性,强调了利用不同构象混合物以实现卓越性能的重要性。
除了预测量子化学性质之外,Uni-Mol+ 还能够预测平衡构象。尽管本研究主要集中在量子化学属性预测上,并且已经证明了 Uni-Mol+ 的有效性,但可视化结果有助于更好地理解其工作原理。因此,研究人员还提供了对 PCQM4MV2 数据集中 Uni-Mol+ 构象学习的两个额外分析。
第一个分析是评估预测的构象。如图 2 所示,Uni-Mol+ 能够有效预测平衡构象。此外,随着迭代次数的增加,RMSD 减小,进一步证明了所提出的迭代坐标更新方法的有效性。
第二个分析旨在证明 Uni-Mol+ 能够预测较低能量的构象,并逐步接近平衡构象。如图 3 所示,Uni-Mol+ 能够预测出能量较低的构象。此外,初始构象与预测构象之间的能量差分布,与初始构象与平衡构象之间的能量差分布非常一致。这种相似性证明了 Uni-Mol+ 在准确预测平衡构象方面的有效性。
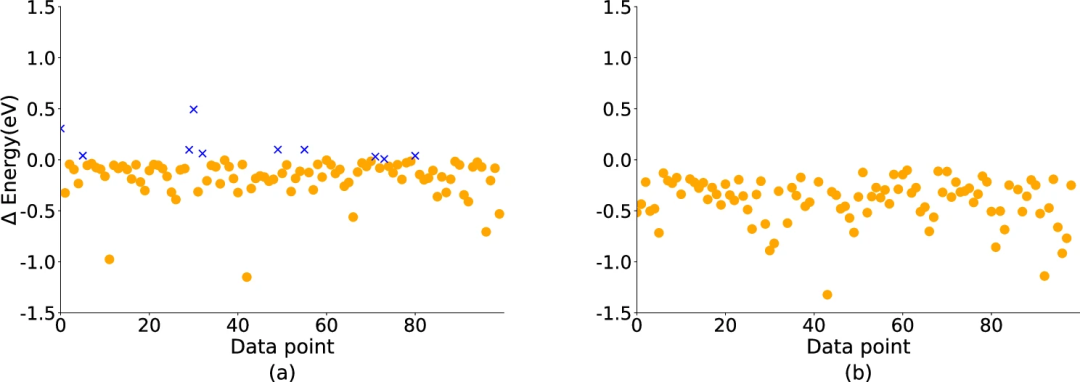
上述结果为所提出的 Uni-Mol+ 的有效性提供了进一步的证据,表明它确实能够预测较低能量的构象,并逐步逼近目标 DFT 构象。
总之,该研究提出了一种新颖的方法,通过辅助任务——构象优化,准确预测量子化学性质。这种方法有望提高高通量筛选的效率,并促进创新材料和分子设计。