元象发布国内首款基于物理的3D动作生成模型MotionGen
编辑日期:2024年08月28日
www.MotionGen.cn

只需一句话即可生成复杂的3D动作,效果令人惊叹!测试期间可申请免费试用。
在3D内容制作领域,生成逼真的角色动作一直是个难题,传统方法需要大量手工调整或昂贵的动作捕捉设备,导致效率低下、成本高昂,并且难以应对复杂的场景和交互任务。
元象XVERSE推出了国内首款基于物理的3D动作生成模型MotionGen,该模型创新性地结合了大模型、物理仿真和强化学习等前沿算法,使用户通过简单的文本指令即可快速生成逼真、流畅且复杂的3D动作,效果惊艳,标志着中国3D AIGC领域的重大突破。
现在,即使是零经验的创作者也能轻松上手,创造出高质量的动画,为动画、游戏、电影和虚拟现实行业带来极高的创作自由度。
作为国内领先的AI+3D公司,元象已研发了多款创新的AIGC工具,包括广东首批获得国家备案的大模型、图文多模态大模型、基于3DGS革命性技术的3D场景生成工具,以及让“虚拟世界活起来”的3D动作自动生成算法。元象的目标是持续提升认知智能(AI)和感知智能(3D),加速迈向通用人工智能(AGI),让每个人都能自由地“定义你的世界”。




MotionGen技术实现
传统3D动作生成方法面临诸多挑战:运动控制器方法虽然可以在设定参数后生成简单的动作,但无法生成复杂动作;时空优化方法能够生成流畅且复杂的动作,但需要精心设计目标函数并手动调整参数,工作量巨大,且生成的动作难以在变化的环境或任务中复用;运动学方法能够生成高质量的单个动作,但在处理重力和惯性等物理约束时表现不佳,导致连续动作不够真实;基于物理的运动控制方法虽然确保动作符合物理规律,但无法直接应用于传统的生成模型。
MotionGen工具基于元象自主研发的MotionGenGPT算法,创造性地融合了物理仿真、模仿学习、强化学习、矢量量化变分自编码器(VQ-VAE)和Transformer模型等多种复杂算法,无需人工设定或调整参数,即可直接生成逼真流畅的复杂3D动作,并适用于任何角色的骨架驱动。
强化学习 + 物理仿真:让动作自然逼真
目前业界普遍采用动捕数据来训练动作生成模型,但原始动捕数据通常存在抖动和误差,导致生成的动作不够自然且不符合物理规律。我们结合深度强化学习,在仿真环境中通过模仿学习[1,2,3,4]来生成更自然的动作。这种方法利用统一的模仿误差作为优化目标,无需设计特定的目标函数。通过在训练过程中引入扰动和改变目标,训练出的控制器可以适应不同目标动作的变化,呈现出自然的过渡动作。
VQ-VAE:提取特征并复用
矢量量化变分自编码器(VQ-VAE)用于从动捕数据中提取关键特征,从而实现动作的高效复用。这种技术不仅提高了动作生成的质量,还简化了模型的训练过程,使得生成的动作更加真实且易于扩展。
基于矢量量化变分自编码器(VQ-VAE)[5]
近期的研究表明,矢量量化变分自编码器(VQ-VAE)能够提供一种高效且紧凑的动作表征方法。许多运动学中的动作生成模型[6, 7, 8]已经验证了VQ-VAE这种离散但紧凑的隐空间表示不仅适用于大规模数据集的训练,还能应用于多种下游任务。受到这些研究的启发,我们将VQ-VAE训练得到的动作表征与GPT相结合,实现了基于物理模拟的文本生成动作。
Transformer:文本与动作的高效连接
在文本生成动作的任务中,Transformer 结构发挥了重要作用。受近年来序列模型发展的启发,我们利用 Transformer 的注意力机制[9],在文本与动作表征之间建立了复杂而精准的联系。通过双 Transformer 设计,模型不仅生成了基础动作编码,还进一步细化了这些编码,捕捉到了运动的微妙细节。这种多层次编码方式使生成的动作既符合物理规律,又展现出自然的流动性和多样性,显著提升了文本驱动动作生成的表现力。该设计使得 MotionGenGPT 能够从文本中生成多样且高度逼真的运动序列,实现了自然语言与运动控制的无缝连接。
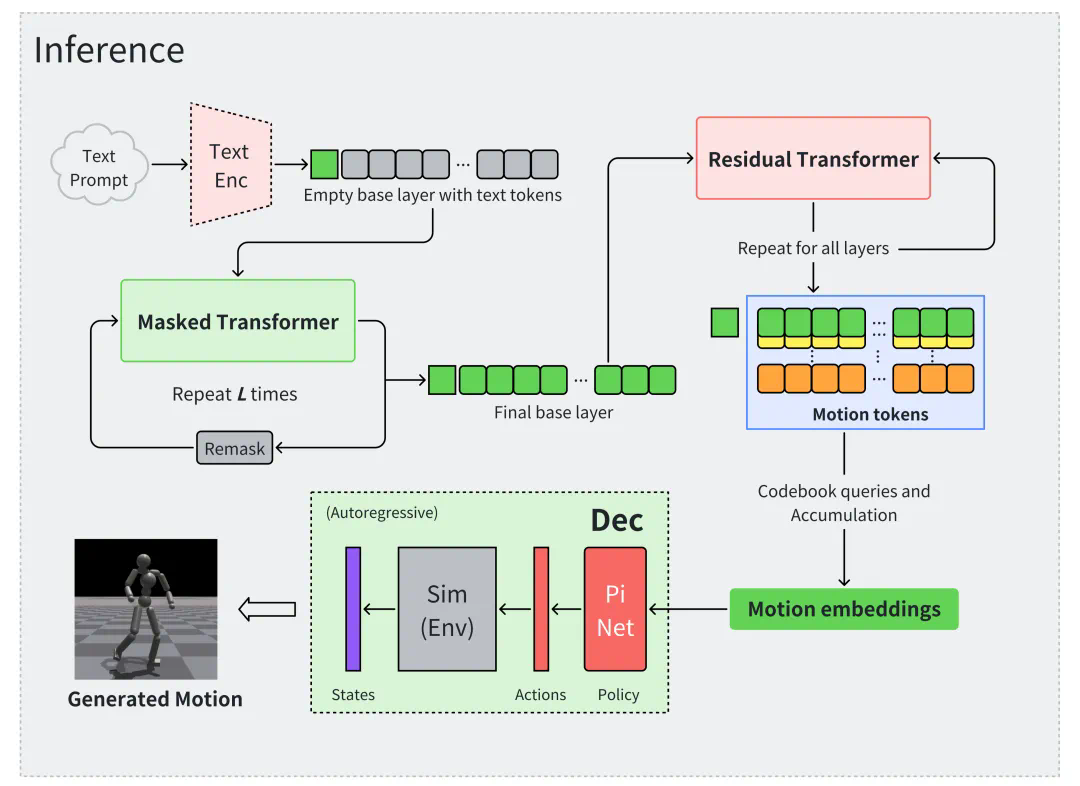
MotionGenGPT 算法的两大框架
第一部分:学习物理正确的动作表征(motion embeddings)
研发团队基于物理模拟的运动控制,采用残差矢量量化变分自编码器(Residual VQ-VAE)结合强化学习,从大量的非结构化人类运动数据集中学习动作表征(motion embeddings)。通过引入离散的动作表征,有效捕获多样化的运动技能,为后续文本编码器的接入提供了稳健的先验分布接口。
元象发布国内首款基于物理的3D动作生成模型
第二部分介绍了生成模型的应用。算法框架通过自注意力机制(Self-attention mechanism)训练了两个 Transformer 模型。第一个模型是掩码 Transformer(Masked Transformer),负责从文本编码中推导出基础层(base layer)的动作编码。第二个模型是残差 Transformer(Residual Transformer),在此基础上生成更精细的残差矢量化动作编码。
这种设计提高了生成动作的细节表现力,并增强了与文本指令的匹配度,为文本生成动作的任务提供了有力支持。
引用
- Levi Fussell, Kevin Bergamin, and Daniel Holden. 2021. SuperTrack: Motion Tracking for Physically Simulated Characters Using Supervised Learning. ACM Transactions on Graphics 40, 6 (Dec. 2021), 197:1–197:13.
-
Libin Liu, Michiel Van De Panne, and Kangkang Yin. 2016. Guided Learning of Control Graphs for Physics-Based Characters. ACM Transactions on Graphics 35, 3 (May 2016), 29:1–29:14.
-
彭雪斌、Pieter Abbeel、Sergey Levine 和 Michiel van de Panne。2018年。DeepMimic:基于示例引导的深度强化学习实现物理角色技能。《ACM图形学汇刊》第37卷,第4期(2018年7月),第143篇,页码1-14。
-
王廷武、郭云蓉、Maria Shugrina 和 Sanja Fidler。2020年。UniCon:适用于基于物理的角色运动的通用神经控制器。CoRR abs/2011.15119(2020年)。arXiv:2011.15119。
-
Aaron van den Oord、Oriol Vinyals 和 Koray Kavukcuoglu。2017年。神经离散表示学习。第31届神经信息处理系统国际会议论文集(NIPS'17)(美国加利福尼亚州长滩)。Curran Associates Inc.,纽约州红钩,页码6309-6318。
-
何源瑶、宋振华、周宇阳、敖腾龙、陈宝权、刘利斌。MoConVQ:通过可扩展的离散表示实现统一的基于物理的运动控制。arXiv预印本 arXiv:2310.10198,2023。
-
郭川、穆宇轩、Muhammad Gohar Javed、王森、程莉。MoMask:3D人体动作的生成掩码建模。arXiv预印本 arXiv:2312.00063,2023。
-
朱庆旭、张赫、兰梦婷、韩磊。基于神经分类先验的物理角色控制。《ACM图形学汇刊》第42卷第6期,文章编号178(2023年12月),共16页。
-
Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N Gomez、Łukasz Kaiser 和 Illia Polosukhin。注意力机制就是一切。《神经信息处理系统进展》(NeurIPS),2017。2, 4, 6。