谷歌推出全球首个AI游戏引擎GameNGen:零代码生成《毁灭战士》,或将颠覆2000亿美元产业
编辑日期:2024年08月30日
「黑神话:悟空」热度不减,AI 在游戏中再次创下全新里程碑。历史上首次,AI 无需依赖游戏引擎即可为玩家生成实时游戏画面。
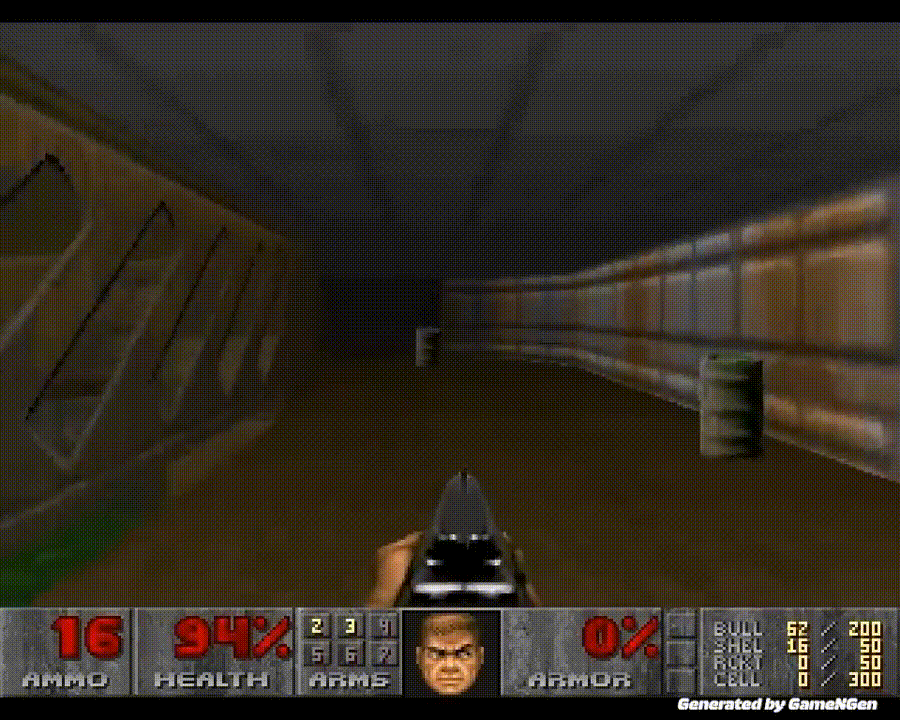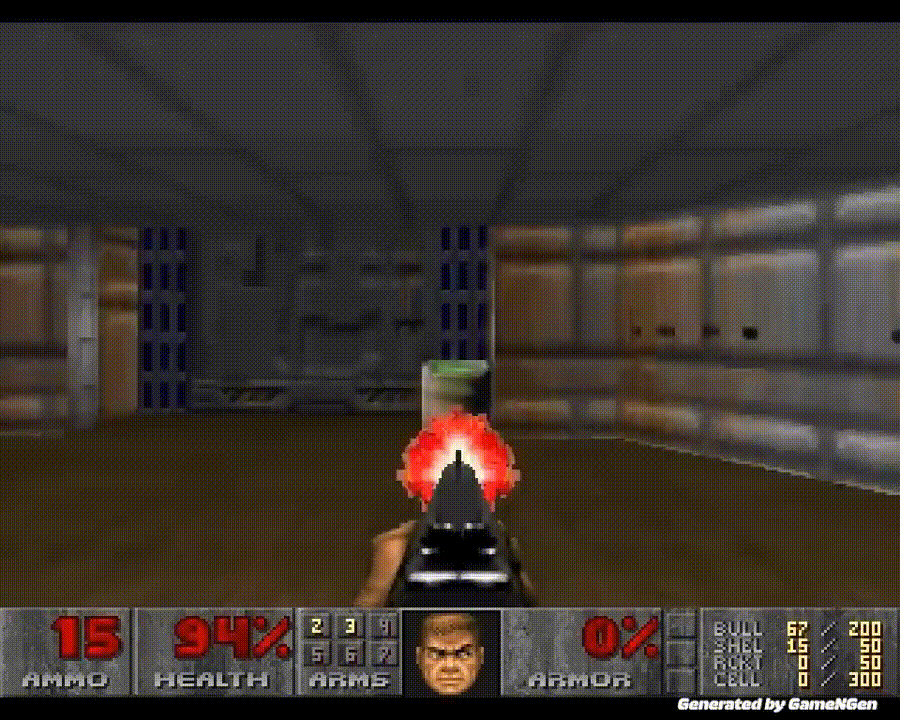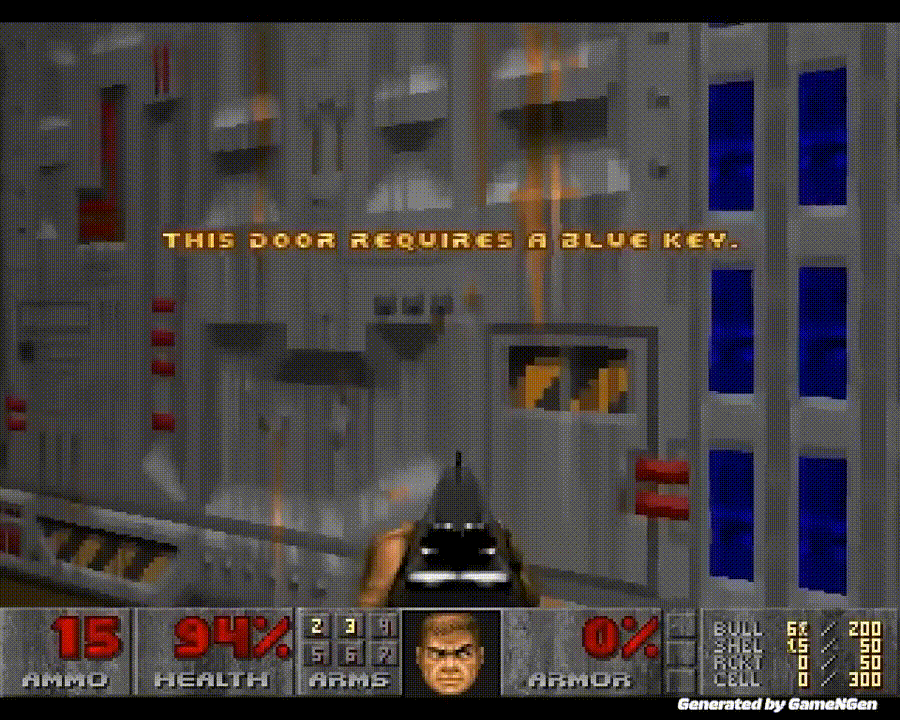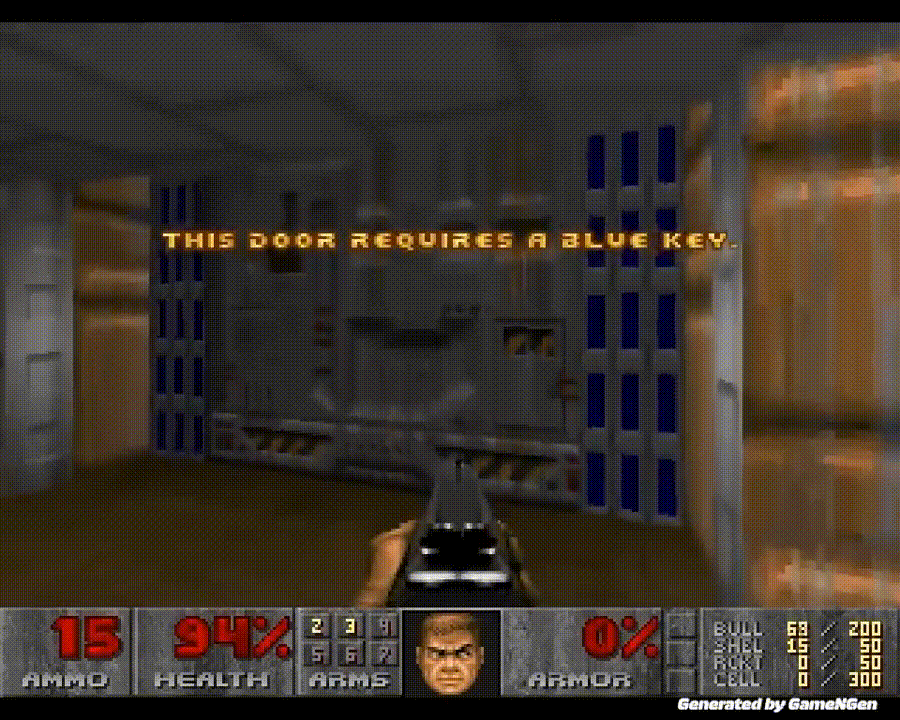
从这一刻起,我们迈入了一个全新的时代:游戏不仅能够被AI玩转,还能由AI来创造和驱动。

谷歌的GameNGen可以在单个TPU上实现每秒20帧的速度,让AI生成实时可玩的游戏。每一帧都是由扩散模型进行预测的。
几年后,实现实时生成3A游戏大作的AI愿望还远吗?
或者:
几年后,实现由AI实时生成3A级游戏大作的目标还会遥远吗?
以上两种表达都可以,根据您的上下文需求选择合适的版本。
从此,开发者无需再手动编写游戏逻辑,这将大幅减少开发时间和成本。全球价值2000亿美元的游戏产业可能会被彻底改变!
谷歌研究人员表示,GameNGen是首个完全由神经模型驱动的游戏引擎,能够在复杂环境中实现高质量的长轨迹实时交互。

论文链接:https://arxiv.org/abs/2408.14837
不仅速度达到实时,其出色的画质也达到了让开发者惊叹的程度。
在模拟《毁灭战士》时,其下一帧的预测峰值信噪比(PSNR)达到了29.4,这已经可以与有损JPEG压缩相媲美。
在神经网络上实时运行时,视觉质量已达到与原始游戏相当的水平。
模拟片段和游戏片段非常相似,以至于许多人类测试者都无法分辨眼前的是游戏还是模拟。

网友感叹:这不仅仅是一款游戏,而是人生模拟器。
小岛秀夫的另一个预言实现了。
3A级电视剧也要来了吗?想象一下,按照自己的喜好生成一版《权力的游戏》。
想象一下,1000 年后或者一百万年后,这项技术会发展成什么样子?到那时,我们进行模拟的概率已经无限接近于 1 了。

AI 首次完全模拟出拥有高质量图形和复杂交互的视频游戏,就能达到这样的水平,实在是令人惊叹。
作为最受欢迎和最具传奇色彩的第一人称射击游戏,《毁灭战士》自1993年发布以来,一直被视为技术标杆。
它被移植到了一系列令人难以想象的平台之上,包括微波炉、数码相机、洗衣机、保时捷等。

而这一次,GameNGen彻底超越了这些早期的改编作品。
从前,传统的游戏引擎依靠精心编写的软件来管理游戏状态和渲染视觉效果。而现在,GameNGen 仅通过 AI 驱动的生成扩散模型,就能自动模拟整个游戏环境。
《毁灭战士》一直以其复杂的3D环境和快节奏的动作著称,而现在,所有这些都不再需要游戏引擎的常规组件了!
AI引擎的意义不仅在于减少游戏的开发时间和成本,更重要的是,这项技术能够彻底实现游戏创作的民主化。无论是小型工作室还是个人创作者,都能够创造出以往难以想象的复杂互动体验。
此外,人工智能游戏引擎还为全新的游戏类型敞开了大门。无论是游戏环境、叙事方式还是游戏机制,都可以根据玩家的行为动态变化。
从此,游戏格局可能会被彻底重塑,行业或将从以热门游戏为中心的模式,转变为一个更多样化的生态系统。
顺便一提,「DOOM」的大小仅为12MB。

HyperWrite 的首席执行官马特·舒默(Matt Schumer)表示,这简直太不可思议了!当用户在玩游戏时,一个模型正在实时生成游戏内容。
如果将大多数AI模型的发展轨迹映射到这里,那么在几年内,我们将能够生成3A级别的游戏。

英伟达的高级科学家 Jim Fan 感叹道,原本被黑客们在各种平台上疯狂运行的《毁灭战士》(DOOM),如今竟然在纯扩散模型中得以实现,每个像素都是生成的。
就连 Sora 与它相比也显得黯然失色。我们只能设置初始条件(一段文本或初始帧),然后被动地观看模拟过程。
由于 Sora 无法进行交互,因此它还不能被称为一个「数据驱动的物理引擎」。
GameNGen 是一个真正的神经世界模型。它以过去的帧(状态)和用户的动作(如键盘/鼠标操作)作为输入,然后输出下一帧的画面。其效果是令人印象最深刻的 DOOM,他从未见过如此高质量的呈现。
随后,他深入探讨了GameNGen中存在的一些限制。
例如,在单一游戏上过度拟合到极致;无法想象新场景,也无法合成新的游戏或交互机制;数据集的瓶颈限制了方法的推广;无法通过提示词创造可玩的世界,或使用世界模型训练出更好的具身AI等。

一个真正有用的神经世界模型应该具备哪些特点?
马斯克的回答是:“特斯拉可以用真实世界的视频来做类似的事情。”
确实,数据是一个难点。
Autopilot团队可能拥有数万亿条数据对(包括摄像头视频和方向盘操作)。凭借如此丰富的实际数据,完全可以训练出一个能够涵盖各种极端情况的通用驾驶模拟器,并使用它来部署和验证新的全自动驾驶(FSD)版本,而无需使用实体车辆。

最后,Jim Fan 总结道:无论如何,GameNGen 仍然是一项非常出色的概念验证——至少现在我们知道,将高分辨率的《毁灭战士》压缩到神经网络中的极限是 9 亿帧。
网友们感叹道:通过网络传播来学习物理引擎和游戏规则的方式真是太疯狂了。
谷歌 DeepMind 的核心贡献者及项目负责人 Shlomi Fruchter 在社交媒体上分享了他开发 GameNGen 的经历。

他表示,“GameNGen 是自己开发道路上的一个重要里程碑。”
弗鲁赫特进行的第一个大型编码项目之一是一个 3D 引擎(如下面的图所示)。早在 2002 年,GPU 还只能用来渲染图形。
还记得吗?第一款图形处理器GeForce 256是在1999年发布的。渲染3D图形需要大量的矩阵运算,而这正是GPU所擅长的。
然后,谷歌的研究人员编写高级着色器语言代码,以计算定制的渲染逻辑并创建新的视觉效果,同时还能保持高帧率。

GameNGen 的诞生源于一个好奇心:
「我们能否在当前的处理器上运行一个隐式神经网络,以实现实时互动游戏?」
对弗鲁赫特和他的团队成员而言,最终的答案是一个令人兴奋的发现。
AI 专家 Karpathy 曾经说过,100% 纯软件 2.0 的计算机,只包含一个神经网络,而没有任何传统的软件。
设备输入(如音频、视频、触摸等)直接进入神经网络,其输出则直接以音频/视频的形式通过扬声器/屏幕展示出来,就是这么简单。
于是,有网友问道:“那是不是意味着它无法运行 DOOM 了?”
对此,Karpathy 表示,如果能够很好地提出请求,它可能会非常接近地模拟 DOOM。
而现在,Fruchter 更加确信它可以运行 DOOM 了。
注:原句中的“它”指代的对象不明确,重写后的句子假设“它”指的是Fruchter本身。如果“它”指的是某个特定的东西,请提供更多信息以便进一步修正。

另一位谷歌作者 Dani Valevski 也转发了这篇帖子,并对这一愿景表示高度赞同。

GameNGen 可能标志着游戏引擎全新范式的开始,想象一下,就像自动生成的图像或视频一样,游戏也可以自动生成。
尽管仍存在一些关键问题,比如如何进行训练、如何最大限度地利用人类输入,以及如何利用神经游戏引擎创建全新的游戏,但作者表示,这种全新范式的潜力令人兴奋。
此外,GameNGen这个名字也藏着一个小彩蛋,你可以试着读一读——它的发音与“Game Engine”非常相似。
在手工制作计算机游戏的时代,工作流程包括:(1)收集用户输入,(2)更新游戏状态,以及(3)将更新后的状态渲染成屏幕像素,计算量取决于帧率。
尽管极客工程师们能够让《毁灭战士》(Doom)在 iPod、相机,甚至微波炉和跑步机等各种设备上运行,但其原理仍然是通过模拟手工编写的游戏软件来实现的。
看似截然不同的游戏引擎,其实也遵循着相同的底层逻辑——工程师们通过手动编程,来指定游戏状态的更新规则和渲染逻辑。
如果将其实时视频生成与扩散模型相结合,乍一看似乎没有什么不同。然而,正如 Jim Fan 所指出的,交互式世界模拟不仅仅是快速的视频生成。

由于无法直接对游戏数据进行大规模采样,因此首先需要教会一个代理(agent)玩游戏,以在各种场景中生成类似人类且足够多样的训练数据。
Agent模型采用深度强化学习方法进行PPO训练,使用简单的CNN作为特征提取网络。该模型生成了900M帧的𝒯_agent数据集,其中包括Agent的动作及其对环境的观察,这些数据用于后续的训练、推理和微调。

GameNGen 使用的 Stable Diffusion 1.4 是一种文本生成图像的扩散模型。该模型最重要的架构调整在于,使其能够根据文本条件适应数据集中的动作数据 a_{<n} 和对先前帧的观察结果 o_{<n}。
具体来说,首先训练一个嵌入模块 A_emb,将代理执行的每个动作(例如特定的按键)转换成一个单独的令牌,并在交叉注意力机制中用编码后的动作序列替换文本。
为了能够接受 o_{<n} 作为条件,同样使用自动编码器 ϕ 将其编码到潜在空间中(即 x_t),并在潜在的通道维度上与噪声隐变量 ε_α 进行拼接。
在实验中,也曾尝试使用交叉注意力来处理o_{<n}输入,但并没有带来明显的改进。
与原来的 Stable Diffusion 相比,GameNGen 在优化方法上进行了改进,采用了速度参数化(velocity parameterization)方法来最小化扩散损失。
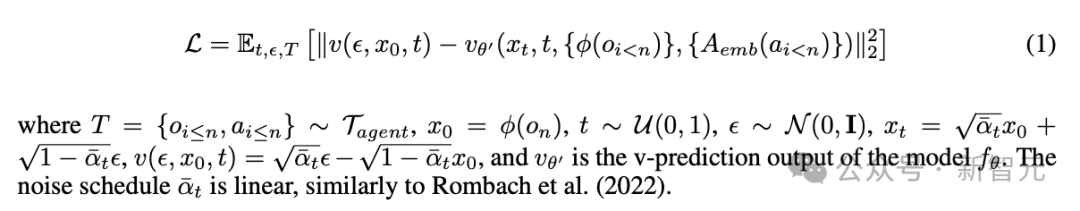
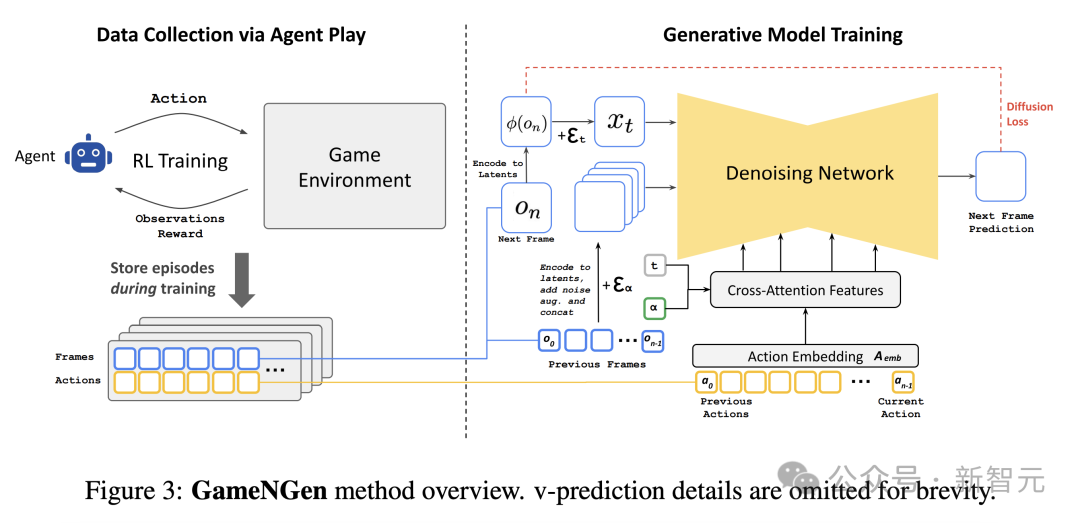
从原始 Stable Diffusion 的教师强制训练转换为游戏引擎中的自回归采样,必然会带来误差的累积,从而导致样本质量迅速下降。
为了解决这个问题,在训练生成模型时,会在编码后的上下文帧中加入不同量的高斯噪声,并且将噪声水平作为模型的输入,这样可以让降噪网络修正先前帧中采样的信息。
这些操作对于随着时间的推移保证帧的质量至关重要。在推理过程中,还可以控制添加的噪声水平,以最大限度地提升生成的质量。

模型在推理过程中使用了DDIM采样方法。能够达到20FPS的实时生成效率,与GameNGen在推理阶段极高的采样效率直接相关。
通常,生成扩散模型(如Stable Diffusion)无法仅通过单个去噪步骤就产生高质量的结果,而是需要数十个采样步骤。
令人惊讶的是,GameNGen 只需 4 个 DDIM 采样步骤就能稳健地模拟 DOOM,并且其质量与使用 20 个或更多采样步骤时相比并没有明显下降。
作者推测,这可能源于多个因素的共同作用,包括可采样图像空间的限制,以及通过先前帧信息施加的强烈条件约束。
通过仅使用四个降噪步骤,U-Net 的推理成本降低至 40 毫秒;结合自动编码器后,总推理成本为 50 毫秒,这相当于每秒可生成 20 帧图像。
实验还发现,经过模型蒸馏并进行单步采样可以进一步提升帧率达到50FPS,但这会牺牲模拟质量。因此,最终还是选择了20FPS的采样方案。
总的来说,在图像质量方面,GameNGen 在长时间轨迹上的预测达到了与原始游戏相当的模拟效果。
对于短时间轨迹,人类评估者在区分模拟片段和真实游戏画面时,其准确性略高于随机猜测。
这表示什么意思?
AI 生成的游戏画面过于逼真和沉浸式,有时人类玩家根本无法分辨。

图像品质
在这里,评估过程中采用了LPIPS和PSNR作为评价指标。这些测量是在强制教学设置下进行的,即根据真实的过去观察来预测单个帧。
在对5个不同关卡中随机抽取的2048个轨迹进行评估时,GameNGen达到了29.43的PSNR和0.249的LPIPS。
图5展示了模型预测结果与相应的真实样本示例。

视频的质量
针对视频质量,研究人员采用了自回归方法,即模型根据自身的过往预测来生成后续帧。
然而,预测轨迹与实际轨迹在几步之后会出现偏差,主要原因是帧间移动速度的微小差异不断累积。
如图 6 所示,随着时间的推移,每帧的 PSNR 值下降,LPIPS 值上升。
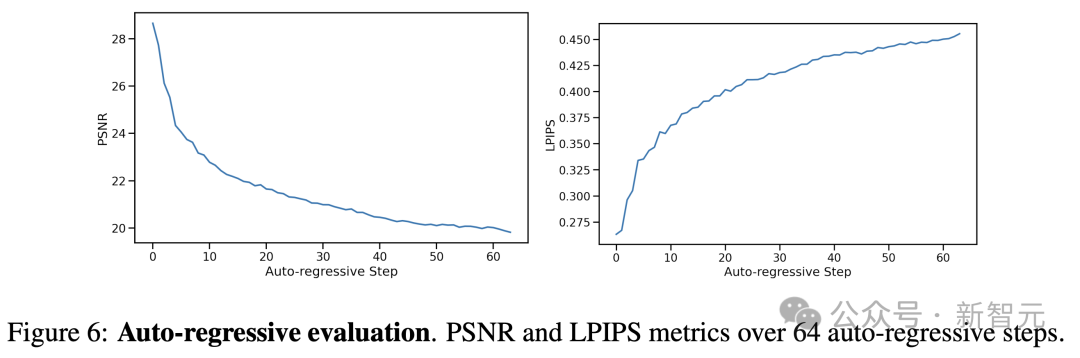
预测的轨迹在内容和图像质量上仍然与实际游戏相似,但在捕捉这些细节方面,逐帧指标的能力有所局限。
因此,研究团队测量了在512个随机保留轨迹上计算得到的FVD(用于衡量预测轨迹和真实轨迹分布之间的差距)。
这里,分别对 16 帧(0.8 秒)和 32 帧(1.6 秒)这两种不同的模拟长度进行了测试。
最终获得的FVD值分别为114.02和186.23。
人工评估指的是由人来进行的评价或估测。
注:仅根据提供的文本内容进行了直译,如果能提供更多的上下文信息,我可以更好地帮助你进行语言的优化或者调整。
为了获得更真实的评估,研究人员向10名人类评估者提供了130个随机短片段(长度分别为1.6秒和3.2秒)。
此外,将 GameNGen 模拟的游戏与真实游戏并列对比,如下所示。

评估者的任务是识别出这些中哪个是真正的真实游戏。
注:原句意稍微有些不清晰,我的改写可能更贴近原意,但具体语境未知,若有更准确的上下文信息,可能会有更好的翻译。
研究结果显示,在生成时长为1.6秒的游戏片段中,有58%的情况下,人们认为GameNGen生成的游戏是真实的。而在生成时长为3.2秒的片段中,这一比例上升到了60%。
接下来,研究人员评估了架构中不同组件的重要性,通过从评估数据集中采样轨迹,并计算真实帧与预测帧之间的 LPIPS 和 PSNR 指标。
请提供需要重写的文本内容。
通过训练 N∈{1, 2, 4, 8, 16, 32, 64} 的模型,测试不同过去观测数量 N 对结果的影响。(标准模型使用了 N=64)。
这影响了历史帧和动作的数量。
(原文已经是中文,所以没有进行重写。)
在保持解码器冻结的状态下,训练模型 200,000 步,并在包含 5 个关卡的测试集上进行评估。
结果如下表1所示,正如预期,研究者观察到,随着上下文的增加,GameNGen的生成质量有所提升。
更有趣的是,在1帧到2帧之间,改进效果非常显著,但之后很快就接近了阈值线,改进的质量逐渐减缓。
即使使用最大的上下文(64帧),GameNGen模型也只能访问略超过3秒的历史信息。
另一个发现是,大多数游戏状态可能会持续更长的时间。
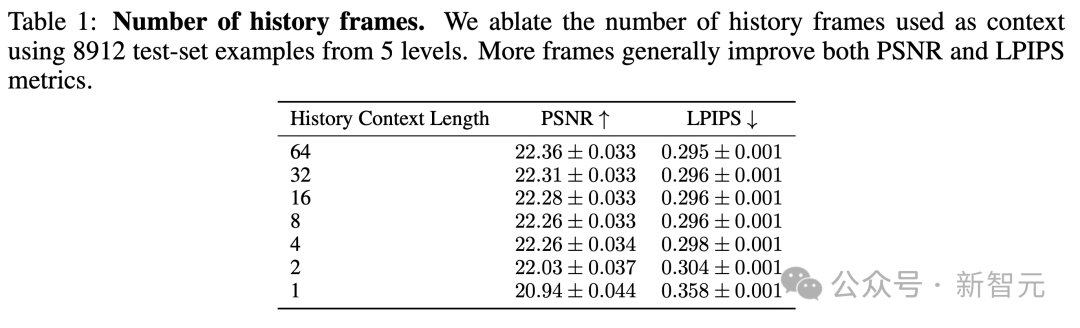
表1的结果很好地说明了未来可能需要对模型架构进行调整,以支持更长的上下文。同时,也需要探索更有效的方法,利用过去的帧作为条件。
噪声增强(Noise Enhancement)
注:这里假设原句意指一种技术或过程,如果"噪声增强"在特定上下文有特定含义,请提供详细上下文。否则根据语境不同,可能存在其他更合适的翻译。
为了消除噪声增强的影响,研究人员还训练了一个未添加噪声的模型。
通过对比评估,在加入噪声增强的标准模型与未添加噪声的模型(在训练 200,000 步后),以自回归方式计算预测帧与真实帧之间的 PSNR 和 LPIPS 指标。
如图 7 所示,展示了每个自回归步骤的平均指标值,总共包含 64 帧。
这些评估是在随机保留的512条轨迹上进行的。
(原文已经是中文,因此未做修改。)
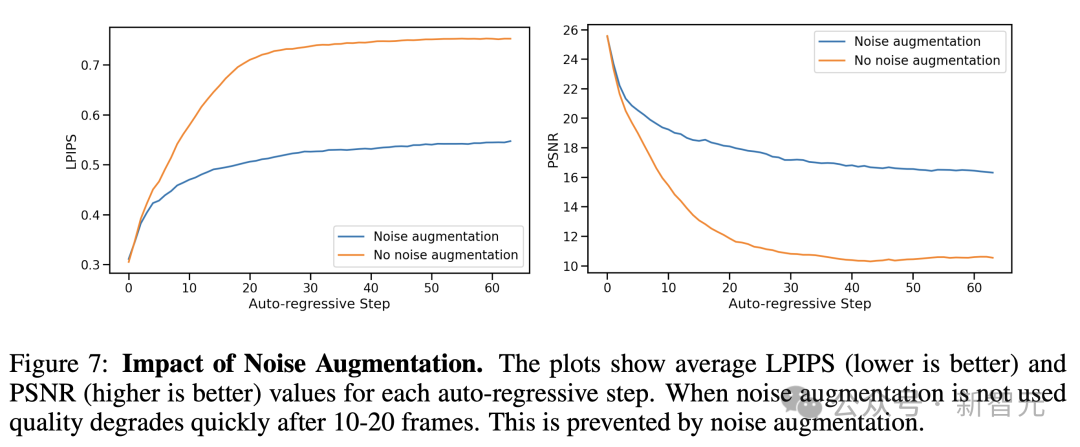
结果显示,在没有噪声增强的情况下,与真实值的 LPIPS 距离增加得比研究标准噪声增强模型更快,而 PSNR 也下降了,这表明模拟结果与真实值之间的偏差增大。
代理人
最后,研究人员将通过智能体生成的数据进行训练的结果,与使用随机策略生成的数据进行训练的结果进行了比较。
这里,通过训练两个模型及解码器,每个模型均训练了70万步。
他们在一个人类游戏轨迹的数据集上进行了评估,该数据集包含5个关卡的2048条记录。
此外,研究人员还比较了在64帧真实历史上下文条件下生成的第一帧与经过3秒自回归生成后的帧。
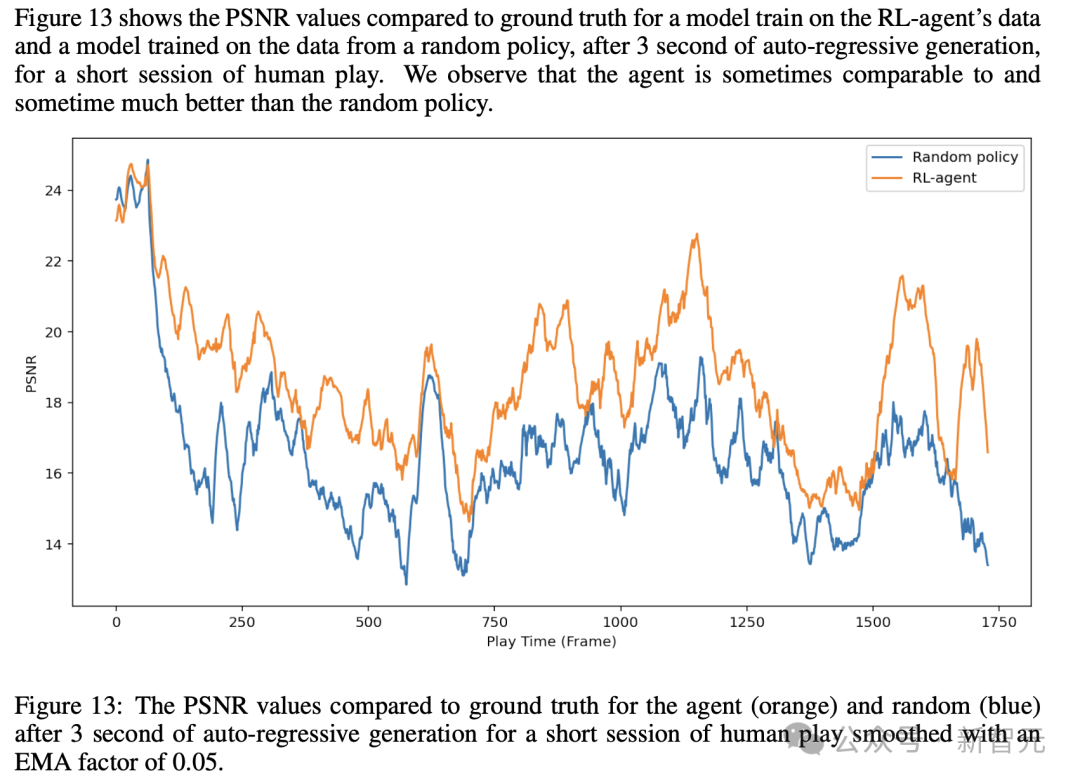
总的来说,研究发现,在随机轨迹上训练模型的效果出乎意料地好,但受到随机策略探索能力的限制。
在单帧生成的比较中,智能体仅略胜一筹,达到了25.06 PSNR,而随机策略为24.42。在比较3秒的情况下,差距增大到19.02与16.84。
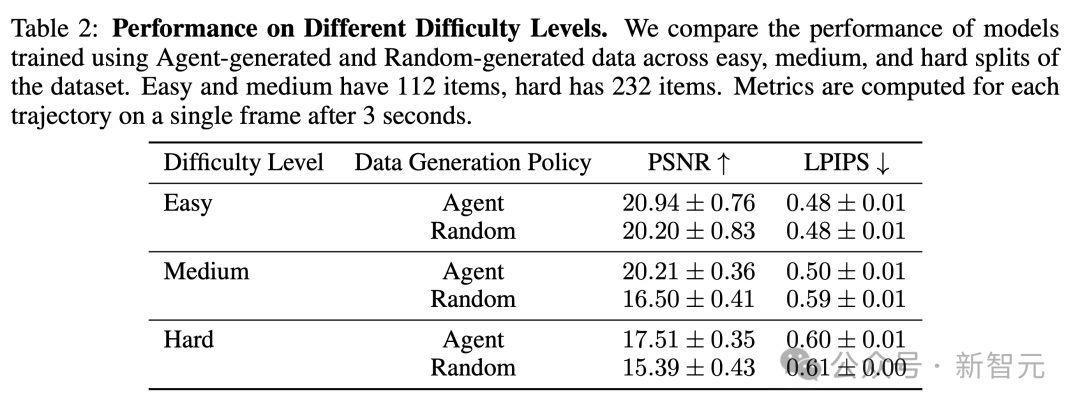
在手动操作模型时,他们还发现某些区域对两者来说都很容易,某些区域对两者来说都十分困难,而在某些区域则是智能体表现得更好。
因此,作者根据这些示例在游戏中的起始位置距离,将456个示例手动分为三个难度级别:简单、中等和困难。
如表2所示,观察结果显示,智能体在简单和困难集合中的表现仅略优于随机水平,而在中等集合中,智能体的表现则如预期般更为显著。
今天,视频游戏是由人类编写的。GameNGen的诞生开启了一种全新的实时互动视频游戏范式。
在这种范式下,游戏是神经模型的“权重”,而不是代码行。现在看来,老黄的预言即将实现。

每个像素很快都将被生成,而不是被渲染。
在今年GTC大会的记者会上,Bilawal Sidhu针对老黄的发言提出了一个后续问题:「我们距离实现每个像素都能以实时帧速率生成的世界还有多远?」
老黄表示,我们还需要5到8年的时间,并且现在已经看到了跨越创新S曲线的迹象。

这表明,目前存在一种架构和模型权重,可以使神经网络在现有的GPU上有效运行复杂的DOOM游戏。
然而,GameNGen 仍然存在许多重要问题,这些问题将是谷歌开发者下一步需要继续解决的。
Shlomi Fruchter带领团队开拓了游戏制作的新领域,并希望这一范式能为未来指引方向。
在这种新范式下,通过仅需一句话或一个示例图像,就可以直接降低视频游戏的开发成本,并让更多的开发者能够进行游戏的开发和编辑。
此外,为现有游戏创建或修改行为可能在短期内就能实现。
例如,我们可以将一组帧转换成一个全新的可玩关卡,或者仅凭示例图像创建一个新角色,而无需编写任何代码。
新范式的优势可能还包括保持出色的帧率和极低的内存占用。
正如论文作者所述,他们希望通过这一小小的尝试步骤,能够为人们的游戏体验,乃至更广泛地对日常交互软件系统的互动,带来极具价值的改进。
更令人兴奋的是,GameNGen 的潜在应用远不止于游戏领域!
无论是虚拟现实、自动驾驶汽车还是智能城市行业,都可能因此发生变革。因为在这些领域中,实时模拟对于培训、测试和运营管理都至关重要。
例如,在自动驾驶汽车中,需要能够模拟无数的驾驶场景,以便能够在复杂的环境中安全行驶。

而像GameNGen这样的AI驱动引擎,正好能够通过高保真度和实时处理来完成这一任务。
在虚拟现实(VR)和增强现实(AR)领域,人工智能引擎能够创建完全沉浸式的互动世界,并且能够实时适应用户的输入。
这种互动式模拟所产生的巨大吸引力,可能会彻底变革教育、医疗保健和远程工作等行业!
当然,GameNGen 也面临一些挑战。虽然它能够以交互速度运行《毁灭战士》,但对于图形要求更高的游戏,可能需要更强的计算能力。

此外,它是针对特定游戏进行量身定制的,因此要开发能够运行多个游戏的通用AI游戏引擎,依然面临巨大挑战。
但现在,我们已经站在了未来的风口浪尖,从今以后,我们最喜欢的游戏将不再是从代码行中诞生,而是从机器的无限创造力中涌现出来。
从此以后,人类的创造力与机器的智能之间将会越来越难以区分。
通过 GameNGen,谷歌的研究人员为我们提供了一个令人兴奋的未来展望——
在这个世界里,限制我们虚拟体验的唯一因素就是AI的想象力。
请提供要重写的文本内容。
本文转载自微信公众号:微信公众号(ID:null),作者:新智元,原题目为《谷歌推出全球首款AI游戏引擎,或颠覆2000亿游戏产业!零代码创造游戏,老黄预言成真》。
大家在看
<a href="/ai-install" class="card card-1">
<img src="https://chat-ex.com/assets/2326231.png" alt="图标描述" style="transform: scale(0.7);">
<div class="card-content">
<span>AI安装教程</span>
<div class="tooltip">AI本地安装教程</div>
</div>